
 Technology peripherals
AI
This figure illustrates the application of learning techniques in a drug recommendation system.
Technology peripherals
AI
This figure illustrates the application of learning techniques in a drug recommendation system.
This figure illustrates the application of learning techniques in a drug recommendation system.


Introduction: The topic shared this time is the application of graph representation learning technology in drug recommendation systems.
mainly includes the following four parts:
- Research background and challenges
- Discriminative drug package recommendation
- Generative drugs Package recommendation
- Summary and outlook
1. Research background and challenges
1. Research background
- #The overall shortage of medical resources and uneven distribution bring heavy pressure
Drug recommendation is a sub-problem of smart medical care. Let’s start with the general background of smart medical care. There is an urgency for smart medical care in our country. As the population grows and the aging population intensifies, , people’s demand for high-quality medical services continues to rise. Two sets of data in the figure: first, the number of visits to medical institutions across the country was 6.05 billion, a year-on-year increase of 22.4%; second, statistics on the medical and health conditions of various countries in The Lancet show that only 57.4% of Chinese doctors have a bachelor's degree or above, including doctors, The number of practitioners per 10,000 people in 16 categories of health occupations, including nurses and community health workers, in China is only one-third of that in the United States. The number of people diagnosed and treated in our country continues to rise, but medical resources and medical standards are still insufficient compared with developed countries. In addition, there is also the problem of uneven distribution of medical resources. The medical level of primary medical institutions is relatively limited, while the supply of top-level institutions exceeds demand. Therefore, how to make full use of the diagnosis and treatment experience of high-level medical institutions to help improve the medical level of primary medical institutions is an important issue that needs to be solved urgently.
- Smart medical care, artificial intelligence technology brings the dawn
With the acceleration of the digitalization of medical institutions in recent years, a large number of medical institutions in my country, especially high-level medical institutions such as tertiary hospitals, have accumulated very rich electronic medical record data. If big data artificial intelligence technology can be used to fully mine this information and extract relevant knowledge, it may help us understand some of the diagnosis and treatment methods and ideas of medical experts in these high-level institutions, and then support smart follow-up visits, medical image analysis, chronic disease follow-up, etc. A series of downstream smart medical applications are of significant significance.
2. Research Challenges
Nowadays, more and more medical AI technologies are becoming more widely used. It also promotes the fairness and universalization of medical services. Some AI technologies, such as medical image analysis, have achieved some impressive results, but they are rarely used in drug recommendation systems. The reason is that drug recommendation systems are very different from traditional recommendation systems, and there are also technical problems with many difficulties.
- Pack recommendation system

##The first challenge is that the application scenario of traditional recommendation systems based on collaborative filtering and other methods is mainly to recommend one item to one user at a time. Their input is the representation of a single item and a single user, and the output is one of the two. Score the degree of matching between them. However, in drug recommendation, doctors often need to prescribe a group of drugs to patients at one time. The drug recommendation system is actually a package recommendation system, called a package recommendation system, which recommends a set of drugs to a user at the same time. How to combine drug recommendation with the package recommendation system is the first big challenge we face.
- Drug-drug interactions
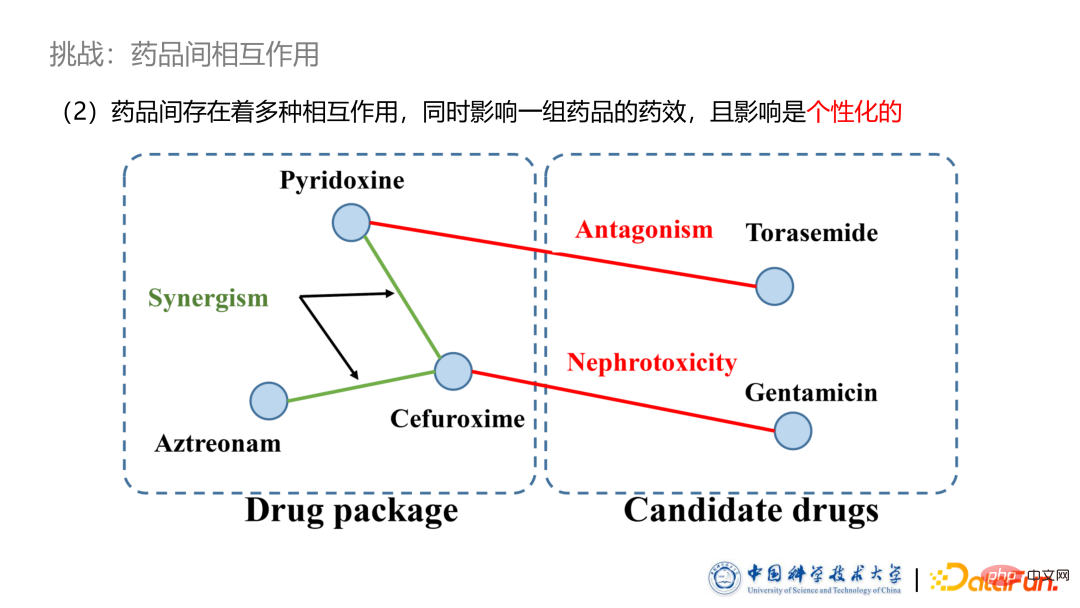
The second challenge of the drug recommendation system is the diverse interactions between drugs. Some drugs have synergistic effects that promote each other's effects, while some drugs have antagonisms that offset each other's effects. Even the combined use of some drugs can lead to toxicity or other side effects. The patient in the picture is suffering from some kind of kidney disease. The left part shows the medicines prescribed by the doctor for the patient. Some of the medicines have synergistic effects and can promote the effectiveness of the medicine. The right part shows the symptomatic high-frequency drugs analyzed statistically. It can be seen that these drugs may not be selected due to some antagonistic effects. The following drugs may be toxic to some existing drugs, so they are not used by this patient.
#In addition, drug interaction effects are individualized. We found in the statistics that a large number of drugs with antagonistic or even toxic effects are used simultaneously. According to analysis, doctors actually prescribe drugs based on the patient's condition and considering the interaction effects. For example, some patients with healthy kidneys can often tolerate a certain amount of drug nephrotoxicity. Therefore, we need to conduct personalized modeling and analysis of the interactions between drugs.
3. Graph representation learning technology has become a new possibility

In summary, combined with the above challenges, graph representation learning technology is very suitable for solving problems existing in drug recommendation systems. With the rapid development of graph neural networks, people realize that graph neural network technology can very effectively model the combination effect between nodes and the relationship between nodes. This inspires us that graph representation learning technology may become a useful tool for building drug recommendation systems. A sharp tool.
#For example, in the figure, we can construct a drug package into a graph based on the interactions within it, and model it through the existing graph neural network. Based on the above ideas, we used graph deep learning technology to do two works on the drug recommendation system, which were published in WWW and TOIS journals respectively. The following is a detailed introduction.
2. Discriminative medicine package recommendation
First introduce the medicine package recommendation we published on WWW2021 paper. This article adopts the discriminative model definition method widely used in package recommendation systems for modeling, and also uses graph representation learning technology as the core technology part.
1. Data description
- Electronic case data

#First introduce the data description used in the work.
The electronic medical records we used in our research work are from a real electronic medical record database of a large tertiary hospital. Each electronic medical record includes the following information: Type information: First, the patient's basic information, including the patient's age, gender, medical insurance, etc.; second, the patient's laboratory information, including abnormalities in laboratory results that the doctor is concerned about, and the type of abnormality: high, low, positive or not etc.; the third is the condition description written by the doctor for the patient: including information such as why the patient was admitted to the hospital, as well as preliminary physical examination; and finally, a set of medicines prescribed by the doctor for the patient.
#This electronic medical record data is heterogeneous data, including structured information such as age, gender, laboratory tests, and unstructured text information such as disease description.
- Drug data

In order to study the interactions between drugs, we collected some drug attributes and interaction data from two large online open source drug knowledge bases, DrugBank and Pharmaceutical Network. Drug interactions are natural language descriptions based on some templates. As shown in the picture above, the description column talks about how a certain drug may increase metabolism or weaken metabolism, etc. The middle word is the template, and the front and back are the filled drug names. Therefore, as long as the model classification is clear, all drug interactions in the database can be marked.
Therefore, under the guidance of professional doctors, we consider drug interactions into no interaction, synergy and antagonism. In the third category, the templates were annotated and the classification of drug interactions was obtained.
2. Data preprocessing and problem definitionIn terms of data preprocessing, for electronic medical record data, we divide it into two Part: The patient's basic information and laboratory information, we process it into a one-hot vector; for the disease description text part, we convert it into fixed-length text through some Padding and Cut off. For drug interaction data: we convert it into a drug interaction matrix.
At the same time, the problem is defined as follows: given a group of patient descriptions and corresponding Ground-truth drug packages, we will train a personalized scoring function, which A given patient and sample package can be input and a match score output. Clearly, this is how a discriminant model is defined.
3. Model Overview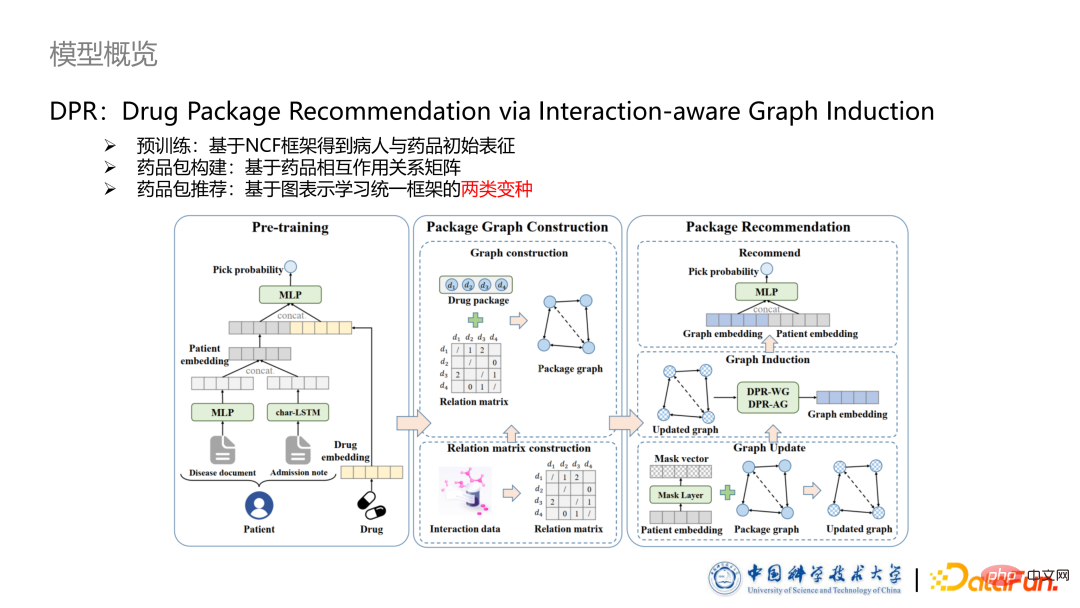 The thesis title proposed in this article is DPR: Drug Package Recommendation via Interaction -aware Graph Induction. The model consists of three parts:
The thesis title proposed in this article is DPR: Drug Package Recommendation via Interaction -aware Graph Induction. The model consists of three parts:
Pre-training part, we obtain the initial representation of patients and drugs based on the NCF framework.
#Drug package construction part, we propose a method to construct a drug package into a drug graph based on the type of drug interaction relationship.
The last part is the graph-based drug package recommendation framework, in which two different variants are designed to understand how to build it from two different perspectives. interactions between model drugs.
- Pre-training

The pre-training part is mainly to capture basic drug effect information, providing a basis for capturing more complex interactions later. For the One-hot part, we use MLP to extract features; for the text part, we use LSTM to extract text features.
- Drug diagram construction
 ##Compared with traditional recommendation, the core issue of drug recommendation is how to consider the interaction between drugs and obtain the representation of the drug package. Based on this, this paper proposes a pharmaceutical package modeling method based on a graphical model.
##Compared with traditional recommendation, the core issue of drug recommendation is how to consider the interaction between drugs and obtain the representation of the drug package. Based on this, this paper proposes a pharmaceutical package modeling method based on a graphical model.
First, the marked drug interaction relationships will be converted into a drug interaction matrix, in which different values represent different interaction types. Then based on this moment, any given drug package can be converted into a heterogeneous drug graph. The nodes in the graph correspond to the drugs in the drug package, and the node attributes are that the nodes correspond to the pre-trained Embedding in the previous step. At the same time, in order to avoid excessive calculations, we did not construct the drug graph into a complete graph, that is, we did not allow an edge between any two drugs, but selectively retained them. Specifically, only those labeled The edges of drug pairs that have been passed and the edges whose frequency exceeds a certain threshold. In order to carry out the drug map Effective Representation,We propose two ways to formalize edge attributes on,drug graphs. The first form is DPR-WG, which uses a weighted graph to represent the drug graph. The first step is to initialize the full value of the edge based on the marked drug interactions, where -1 represents antagonism, 1 represents synergy, and 0 represents no interaction or unknown. The mask vector is then used to perform personalized updates to the edge weights in the drug graph. This mask vector reflects the interaction of different drugs and the degree of personalized impact on individual patients. Its calculation method is to use a nonlinear layer plus a Sigmoid function such that The value of each dimension is from 0 to 1, thereby realizing the role of feature selection and personalized adjustment of drug interactions. The drug graph update process is to first calculate an update factor in DPR-WG, and then update the update factor by multiplying or adding the weight of the corresponding edge. In subsequent experiments, it was found that the update method had little impact on the results. In the process of drug graph representation, we designed a method to represent drugs based on weighted graphs. In summary, we first designed an information update process for weighted graphs: aggregating neighbor information. During the aggregation process, based on the edge weight , personalize the degree of aggregation. We then used a Self Attention mechanism to calculate the weights between different nodes, and used an aggregation MLP to aggregate the graph to obtain the final representation of the entire drug graph. Subsequently, the patient representation and drug image representation are input into the scoring function, and the output can be obtained for recommendation. In addition, this article uses BPRLoss to train the model and introduces a negative sampling method, corresponding to 1 positive sample and 10 negative samples. lf attention and aggregation methods. We can also use BPRLoss for training. The difference is that we have introduced an additional cross-entropy loss function for edge classification. We hope that the edge vector can include the interaction between drugs. Function category information. Because the initialized sign in the previous variant naturally retains this information, but the graph of this variant does not, this information is supplemented by introducing a loss function. From the experimental results, our two models exceed other discriminant models in different evaluation indicators. At the same time, we also conducted a case analysis: using the t-SNE method to project the previously mentioned mask vector onto a two-dimensional space. As shown in the figure, for example, the drugs used by pregnant women, infants, and liver patients have a very obvious tendency to cluster into clusters, which proves the effectiveness of our method. The above discriminant model can only be used in existing drug packages Selection, without the ability to generate new drug packages, will affect the recommendation effect. Next, we will introduce the extension work of the previous work published in the TOIS journal. The purpose is to hope that the model can generate new medicines tailored for new patients. Medicine package. This work retains the core idea of graph representation learning in the previous paper, while completely changing the problem definition, defining the model as a generative model, and introducing sequences Generative and reinforcement learning technologies have greatly improved the recommendation effect. ##Discriminant The core difference between the formula model and the generative model is that the discriminant model scores the matching degree between a given patient and a given drug package, while the generative model generates candidate drug packages for the patient and selects the best drug package. In view of the above mentioned To address the shortcomings of the discriminant model, we designed some heuristic generation methods: by adding and deleting some drugs in drug packages for similar patients, some drug packages that have never appeared in the historical records are formed for the model to select. Experimental results prove that this simple method is very effective and provides a basis for subsequent methods. The following is published in TOIS Interaction-aware Drug Package Recommendation via Policy Gradient article. The model proposed in this article is called DPG, which is different from the DPR in the previous article. G here is Generation. This model mainly contains three parts, namely information dissemination on the drug interaction diagram, patient characterization and drug package generation module, and the above The biggest difference is the medicine package generation module. First build the drug interaction graph part. This article retains the method of graph neural network to capture the interaction between drugs. The difference is that in the discriminant model, the drug package is given and can be easily converted into a drug graph. In the generative model, the drug graph is not fixed. Due to the amount of calculation, it is impossible to construct all drug packages into graphs. This article includes all drugs in a drug interaction graph. It also uses Attributed graph to formalize the graph, while also retaining the edge classification loss. function, retaining the Embedding information of the edges, and finally a GNN based on this drug interaction graph was constructed. After several rounds (usually 2) of message passing, we extract the node Embedding as the drug Embedding to be used. The patient characterization part is also used. MLP and LSTM are used to extract the patient's representation vector, and also calculate the mask vector, which is subsequently used to capture the patient's personalized representation vector. The drug package generation task can be regarded as a sequence generation task, which is implemented using the recurrent neural network RNN. However, this method also brings two major challenges: The first challenge is how to consider the generated drugs and existing drugs during the generation process. interactions between. To this end, we propose a method based on drug interaction vectors to explicitly model the interactions between drugs. #The second challenge is that the sample package is a set, which is inherently unordered, but sequence generation tasks often target ordered sequence methods. To this end, we proposed a reinforcement learning method based on policy gradient, and added a method based on SCST to improve the effect and stability of this algorithm. First introduce how to consider the interaction between drugs in the process of generating drug packages based on the great nature. This part is also the basis for the reinforcement learning part that will be used later. Sequence generation methods based on maximum likelihood have been widely used in the field of NLP. During the generation process, each generated drug depends on other previously generated drugs. In order to take into account the interaction between drugs without bringing excessive computational burden to the model, we propose to explicitly Calculate the interaction vector between the newly generated drug and the previous drug. This vector calculation method comes from a layer in the previous graph neural network. At the same time, we add the mask vector and the interaction vector to multiply the corresponding elements to introduce the patient's personalized information. Finally, sum the interaction vectors of all drugs and use MLP to fuse them to obtain a comprehensive interaction vector. The subsequent integration of this vector into the classic sequence model for generation solves the first challenge. Different from the classic sequence generation, the medicine package is actually a collection, and there should be no duplicate medicines, so we Later, a restriction was added to prevent the model from generating the drug that has already been generated, ensuring that the generated result must be a set. Finally, we used the MLE loss function based on maximum likelihood to train the model. The biggest disadvantage of the above method based on maximum likelihood is that the drug package has a strict order. Some methods of manually specifying the order for the drugs, such as sorting by frequency, sorting by first letter, etc., will destroy the drugs. The characteristics of the package collection will also lose part of the model's performance, so we proposed a drug package generation model based on reinforcement learning. The goal of the model in reinforcement learning is to maximize the artificially set reward function. After the model generates a complete drug package, giving a reward loss function that is independent of order can reduce the model's dependence on order. This article uses F-value as reward, which is an order-independent function and is the evaluation index we are concerned about. This article uses F-value as the evaluation index, and adopts a training method based on policy gradient in the training method, and will not be deduced in detail here. Among the training methods based on policy gradient, one of the most well-known methods is to use a baseline to reduce the variance of the gradient estimate. , thereby increasing the stability of training. Therefore, we used a training method based on SCST, namely the Self-critical sequence training method. The baseline also comes from the reward obtained by the drug package generated by the model itself. The way I generate it is the normal sequence generation method of Greedy search. We hope that the reward of the drug package sampled by the model based on Policy gradient is higher than the drug package generated by the traditional Greedy search. Based on this, this article designs a loss function for reinforcement learning, as shown in the figure. The derivation process will not be introduced in detail here. In addition, one of the characteristics of reinforcement learning is that training is difficult, so we combine the above two training methods. First, we use the extremely natural estimation method to pre-train the model, and then use the reinforcement learning method. method to fine-tune the model parameters. The next step is the experiment of the model result. In the above table, all medicine packages are generated using Greedy search. First of all, the performance of methods based on generative models is generally better than methods based on discriminative models. This experiment proves that generative models will be a better choice. This model surpasses all other baselines in F value. In addition, the performance of the model based on reinforcement learning greatly surpassed the model based on maximum likelihood, proving the effectiveness of the reinforcement learning method. We then conducted a series of ablation experiments. We removed the interaction graph, including the interaction mask vector and the reinforcement learning module for ablation, and the results proved that each of our modules is effective. At the same time, it can be seen that if the SCST module is removed, the model effect drops significantly, which proves that reinforcement learning is indeed difficult to train. Without Baseline restrictions, the entire training process will be very jittery. Finally, we have also done a lot of case analysis, and we can see that pregnant women and babies have obvious personalized preferences. At the same time, we added some additional common diseases such as stomach disease, heart disease, etc. The mask vectors of these diseases are very scattered and do not form clusters. The conditions of patients with common diseases are diverse, and there will be no particularly personalized situations. Unlike pregnant women and infants, there are very obvious screenings for drugs. For example, certain pediatric drugs need to be designated, and some drugs cannot be used by pregnant women. At the same time, we projected the interaction vector of the drugs. We can see that the two drugs, synergy and antagonism, form two different oppositions when interacting with each other. situation, indicating that the model captures the different effects brought about by two different interactions. In summary, our research is mainly about the personalization of interaction perception Drug package recommendations include discriminative drug package recommendations and generative drug package recommendations. The two have in common that they both use graph representation learning technology to model the interaction between drugs, and both use mask vectors to consider the impact of patient conditions on each other. Personalized perception of effects. The biggest difference between the two works is the difference in problem definition. For the discriminant model, what we want is a scoring function, so for the generative model, what we want is a generating function. It has been proved through experiments that the generative model is actually a better definition of the problem. 
 #The second variant is to use attribute graphs to represent drug graphs. The first step is to initialize the edge vector by fusing the node vectors at both ends of the edge through an MLP. Then the mask vector is also used to update the edge vector. At this time, the update method is no longer an update factor, but calculates an update vector. The update vector is multiplied element by element with the edge vector of the drug to obtain the updated edge attributes. vector. We specially designed a GNN for attribute graphs. The message passing process first calculates the message based on the edge vector and the node Embedding at both ends for propagation, and obtains the Graph Embedding through se
#The second variant is to use attribute graphs to represent drug graphs. The first step is to initialize the edge vector by fusing the node vectors at both ends of the edge through an MLP. Then the mask vector is also used to update the edge vector. At this time, the update method is no longer an update factor, but calculates an update vector. The update vector is multiplied element by element with the edge vector of the drug to obtain the updated edge attributes. vector. We specially designed a GNN for attribute graphs. The message passing process first calculates the message based on the edge vector and the node Embedding at both ends for propagation, and obtains the Graph Embedding through se3. Generative drug package recommendation
1. Discriminant recommendation -> Generative recommendation

2. Heuristic generation method

3. Model Overview











4. Summary and Outlook
The above is the detailed content of This figure illustrates the application of learning techniques in a drug recommendation system.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
