
 Technology peripherals
AI
Zhu Jun's team open sourced the first large-scale multi-modal diffusion model based on Transformer at Tsinghua University, and it was completely completed after text and image rewriting.
Technology peripherals
AI
Zhu Jun's team open sourced the first large-scale multi-modal diffusion model based on Transformer at Tsinghua University, and it was completely completed after text and image rewriting.
Zhu Jun's team open sourced the first large-scale multi-modal diffusion model based on Transformer at Tsinghua University, and it was completely completed after text and image rewriting.

It is reported that GPT-4 will be released this week, and multi-modality will become one of its highlights. The current large language model is becoming a universal interface for understanding various modalities and can give reply texts based on different modal information. However, the content generated by the large language model is only limited to text. On the other hand, the current diffusion models DALL・E 2, Imagen, Stable Diffusion, etc. have set off a revolution in visual creation, but these models only support a single cross-modal function from text to image, and are still far from a universal generative model. distance. The multi-modal large model will be able to open up the capabilities of various modalities and realize conversion between any modalities, which is considered to be the future development direction of universal generative models.
The TSAIL team led by Professor Zhu Jun from the Department of Computer Science at Tsinghua University recently published a paper "One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale", which was the first to publish the multi-modal Some exploratory work on generative models has enabled mutual transformation between arbitrary modes.

##Paper link: https://ml.cs. tsinghua.edu.cn/diffusion/unidiffuser.pdf
##Open source code: https://github.com/thu-ml/unidiffuser
This paper proposes a probabilistic modeling framework UniDiffuser designed for multi-modality, and adopts the transformer-based network architecture U-ViT proposed by the team to use open source large-scale graphic and text data A model with one billion parameters was trained on LAION-5B, enabling an underlying model to complete a variety of generation tasks with high quality (Figure 1). To put it simply, in addition to one-way text generation, it can also realize multiple functions such as image generation, image and text joint generation, unconditional image and text generation, image and text rewriting, etc., which greatly improves the production efficiency of text and image content, and further improves the generation of text and graphics. The application imagination of formula model.The first author of this paper, Bao Fan, is currently a doctoral student. He was the previous proposer of Analytic-DPM. He won the outstanding paper award of ICLR 2022 (currently the only one) for his outstanding work in diffusion models. award-winning papers independently completed by mainland units).
In addition, Machine Heart has previously reported on the DPM-Solver fast algorithm proposed by the TSAIL team, which is still the fastest generation algorithm for diffusion models. The multi-modal large model is a concentrated display of the team's long-term in-depth accumulation of algorithms and principles of deep probabilistic models. Collaborators on this work include Li Chongxuan from Renmin University’s Hillhouse School of Artificial Intelligence, Cao Yue from Beijing Zhiyuan Research Institute, and others.

Effect Display
Figure 8 below shows the effect of UniDiffuser in jointly generating images and text:
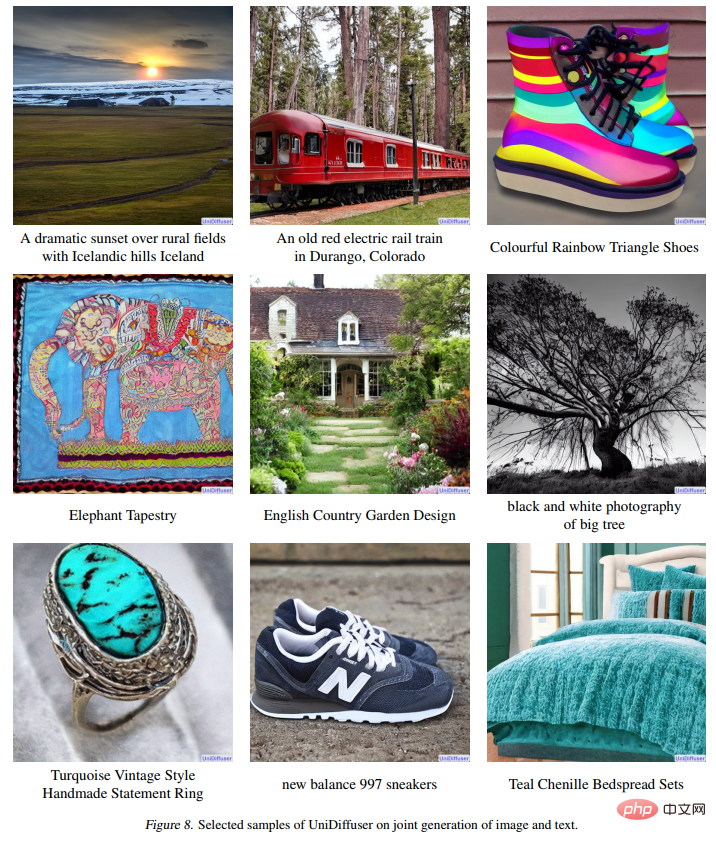



The following figure 12 shows the effect of UniDiffuser on image rewriting:

The following figure 15 shows that UniDiffuser can jump back and forth between the two modes of graphics and text:

As shown in Figure 16 below UniDiffuser can interpolate two real images:
Method Overview
The research team divided the design of a general generative model into two sub-problems:
- Probabilistic modeling framework: Is it possible to find a probabilistic modeling framework that can simultaneously model all distributions between modes, such as the edge distribution between images and texts? , conditional distribution, joint distribution, etc.?
- Network architecture: Can a unified network architecture be designed to support various input modalities?
Probabilistic modeling framework
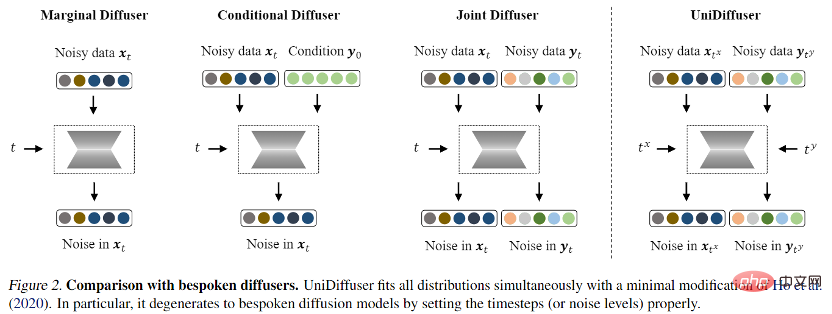
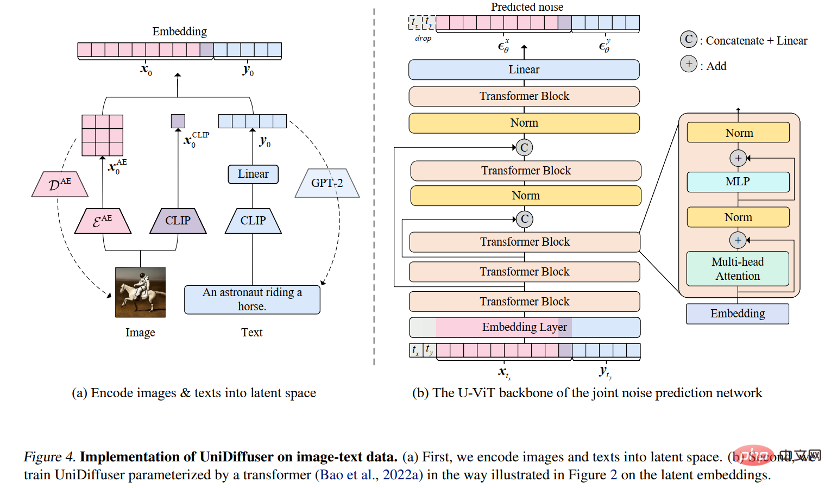
For the probabilistic modeling framework, the research team proposed UniDiffuser, a A probabilistic modeling framework for diffusion models. UniDiffuser can explicitly model all distributions in multimodal data, including marginal distributions, conditional distributions, and joint distributions. The research team found that diffusion model learning about different distributions can be unified into one perspective: first add a certain size of noise to the data of the two modalities, and then predict the noise on the data of the two modalities. The amount of noise on the two modal data determines the specific distribution. For example, setting the noise size of the text to 0 corresponds to the conditional distribution of the Vincentian diagram; setting the noise size of the text to the maximum value corresponds to the distribution of unconditional image generation; setting the noise size of the image and text to the same value corresponds to the distribution of the unconditional image generation. Joint distribution of images and texts. According to this unified perspective, UniDiffuser only needs to make slight modifications to the training algorithm of the original diffusion model to learn all the above distributions at the same time - as shown in the figure below, UniDiffuser adds noise to all modes at the same time instead of a single mode, input The noise magnitude corresponding to all modes, and the predicted noise on all modes.
Taking bimodal mode as an example, the final training objective function is as follows:
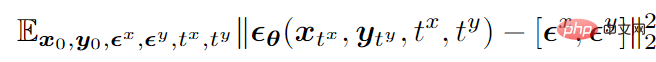

## represents data ,


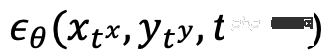
After training, UniDiffuser is able to achieve unconditional, conditional and joint generation by setting the appropriate time for the two modalities to the noise prediction network. For example, setting the time of the text to 0 can achieve text-to-image generation; setting the time of the text to the maximum value can achieve unconditional image generation; setting the time of the image and text to the same value can achieve joint generation of images and texts. The training and sampling algorithms of UniDiffuser are listed below. It can be seen that these algorithms have only made minor changes compared to the original diffusion model and are easy to implement. 
In addition, because UniDiffuser models both conditional distribution and unconditional distribution, UniDiffuser naturally supports classifier-free guidance . Figure 3 below shows the effect of UniDiffuser's conditional generation and joint generation under different guidance scales:

Network Architecture
#In view of the network architecture, the research team proposed to use a transformer-based architecture to parameterize the noise prediction network. Specifically, the research team adopted the recently proposed U-ViT architecture. U-ViT treats all inputs as tokens and adds U-shaped connections between transformer blocks. The research team also adopted the Stable Diffusion strategy to convert data of different modalities into latent space and then model the diffusion model. It is worth noting that the U-ViT architecture also comes from this research team and has been open sourced at https://github.com/baofff/U-ViT.
Experimental results
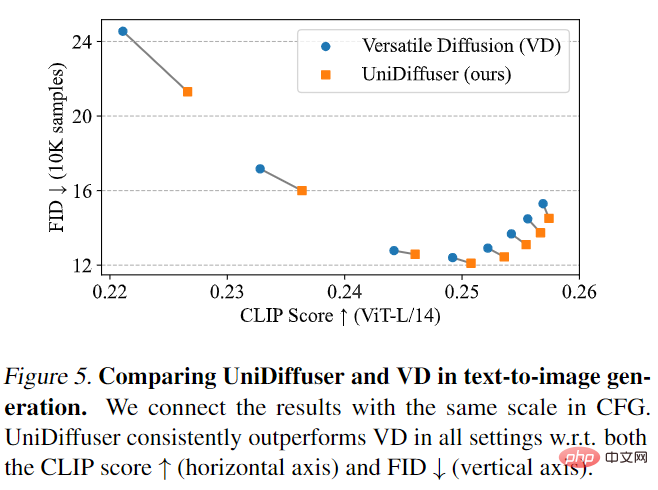
UniDiffuser was first compared with Versatile Diffusion. Versatile Diffusion is a past multi-modal diffusion model based on a multi-task framework. First, UniDiffuser and Versatile Diffusion were compared on text-to-image effects. As shown in Figure 5 below, UniDiffuser is better than Versatile Diffusion in both CLIP Score and FID metrics under different classifier-free guidance scales.
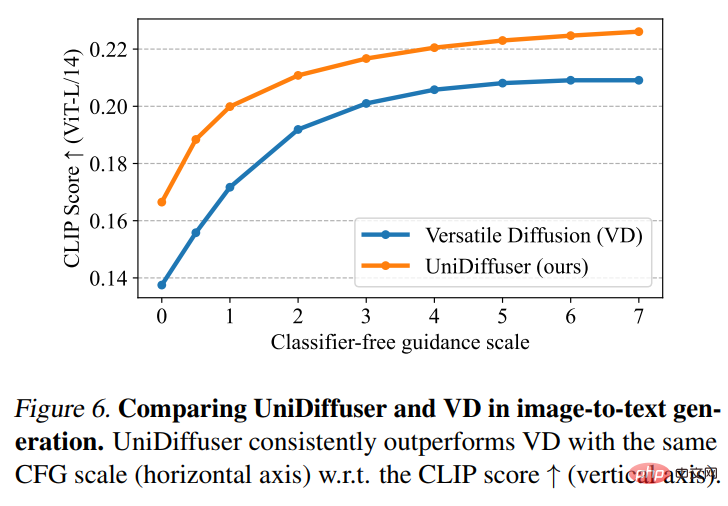
Then UniDiffuser and Versatile Diffusion performed a picture-to-text comparison. As shown in Figure 6 below, UniDiffuser has a better CLIP Score on image-to-text.
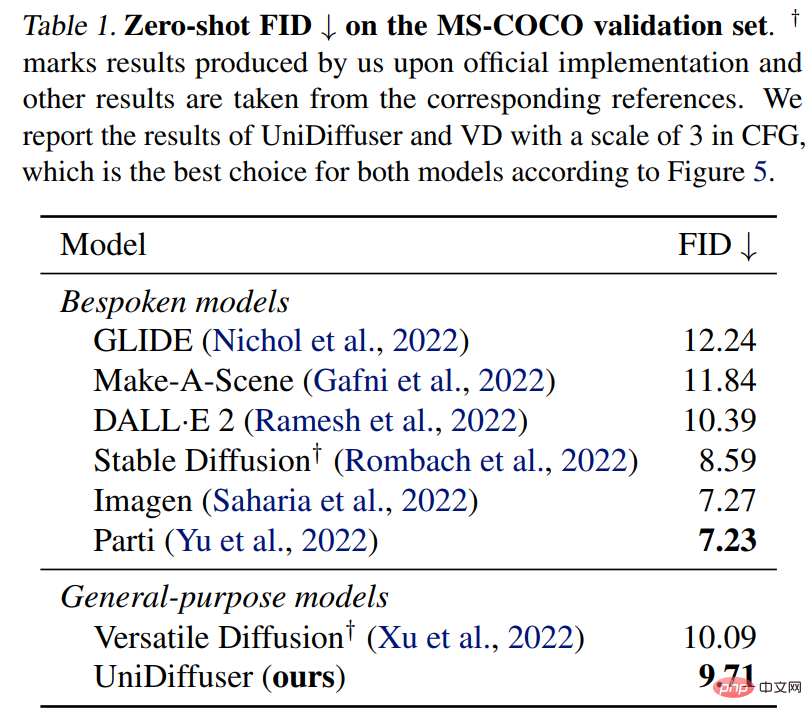
## UniDiffuser also performs a zero-shot FID comparison on MS-COCO against a dedicated text-to-graph model. As shown in Table 1 below, UniDiffuser can achieve comparable results to dedicated text-to-graph models.
The above is the detailed content of Zhu Jun's team open sourced the first large-scale multi-modal diffusion model based on Transformer at Tsinghua University, and it was completely completed after text and image rewriting.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
 How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
Evaluating the cost/performance of commercial support for a Java framework involves the following steps: Determine the required level of assurance and service level agreement (SLA) guarantees. The experience and expertise of the research support team. Consider additional services such as upgrades, troubleshooting, and performance optimization. Weigh business support costs against risk mitigation and increased efficiency.
 Tsinghua University took over and YOLOv10 came out: the performance was greatly improved and it was on the GitHub hot list
Jun 06, 2024 pm 12:20 PM
Tsinghua University took over and YOLOv10 came out: the performance was greatly improved and it was on the GitHub hot list
Jun 06, 2024 pm 12:20 PM
The benchmark YOLO series of target detection systems has once again received a major upgrade. Since the release of YOLOv9 in February this year, the baton of the YOLO (YouOnlyLookOnce) series has been passed to the hands of researchers at Tsinghua University. Last weekend, the news of the launch of YOLOv10 attracted the attention of the AI community. It is considered a breakthrough framework in the field of computer vision and is known for its real-time end-to-end object detection capabilities, continuing the legacy of the YOLO series by providing a powerful solution that combines efficiency and accuracy. Paper address: https://arxiv.org/pdf/2405.14458 Project address: https://github.com/THU-MIG/yo
 Google Gemini 1.5 technical report: Easily prove Mathematical Olympiad questions, the Flash version is 5 times faster than GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 technical report: Easily prove Mathematical Olympiad questions, the Flash version is 5 times faster than GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
In February this year, Google launched the multi-modal large model Gemini 1.5, which greatly improved performance and speed through engineering and infrastructure optimization, MoE architecture and other strategies. With longer context, stronger reasoning capabilities, and better handling of cross-modal content. This Friday, Google DeepMind officially released the technical report of Gemini 1.5, which covers the Flash version and other recent upgrades. The document is 153 pages long. Technical report link: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf In this report, Google introduces Gemini1
 Review! Comprehensively summarize the important role of basic models in promoting autonomous driving
Jun 11, 2024 pm 05:29 PM
Review! Comprehensively summarize the important role of basic models in promoting autonomous driving
Jun 11, 2024 pm 05:29 PM
Written above & the author’s personal understanding: Recently, with the development and breakthroughs of deep learning technology, large-scale foundation models (Foundation Models) have achieved significant results in the fields of natural language processing and computer vision. The application of basic models in autonomous driving also has great development prospects, which can improve the understanding and reasoning of scenarios. Through pre-training on rich language and visual data, the basic model can understand and interpret various elements in autonomous driving scenarios and perform reasoning, providing language and action commands for driving decision-making and planning. The base model can be data augmented with an understanding of the driving scenario to provide those rare feasible features in long-tail distributions that are unlikely to be encountered during routine driving and data collection.
 How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
The learning curve of a PHP framework depends on language proficiency, framework complexity, documentation quality, and community support. The learning curve of PHP frameworks is higher when compared to Python frameworks and lower when compared to Ruby frameworks. Compared to Java frameworks, PHP frameworks have a moderate learning curve but a shorter time to get started.
 How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
The lightweight PHP framework improves application performance through small size and low resource consumption. Its features include: small size, fast startup, low memory usage, improved response speed and throughput, and reduced resource consumption. Practical case: SlimFramework creates REST API, only 500KB, high responsiveness and high throughput
