

How to process Excel data with Python's Pandas library?

1. Read xlsx table: pd.read_excel()
The original content is as follows:
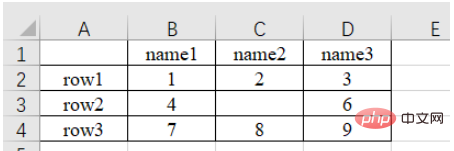
a) Read the nth Sheet (sub-table, you can view or add or delete sub-tables in the lower left) data
import pandas as pd # 每次都需要修改的路径 path = "test.xlsx" # sheet_name默认为0,即读取第一个sheet的数据 sheet = pd.read_excel(path, sheet_name=0) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 """
It can be noticed that there is no content in the upper left corner of the original form, and the read result is "Unnamed : 0", this is because the read_excel function will default the first row of the table as the column index name . In addition, for row index names, numbering starts from the second row by default (because the default first row is the column index name, so the default first row is not data). If not specifically specified, numbering starts from 0 automatically, as follows.
sheet = pd.read_excel(path) # 查看列索引名,返回列表形式 print(sheet.columns.values) # 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式 print(sheet.index.values) """ ['Unnamed: 0' 'name1' 'name2' 'name3'] [0 1 2] """
b) The column index name can also be customized, as follows:
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4']) print(sheet) # 查看列索引名,返回列表形式 print(sheet.columns.values) """ col1 col2 col3 col4 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 ['col1' 'col2' 'col3' 'col4'] """
c) You can also specify the nth column as the row index name , as follows:
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""d) Skip the nth row of data when reading
# 跳过第2行的数据(第一行索引为0) sheet = pd.read_excel(path, skiprows=[1]) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row2 4 NaN 6 1 row3 7 8.0 9 """
2. Get the data size of the table: shape
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""3. Method of indexing data: [ ] / loc[] / iloc[]
1. Directly add square brackets to index
You can use square brackets to add column names The method [col_name] is used to extract the data of a certain column, and then use square brackets plus the index number [index] to index the value of the specific position of this column. Here, the column named name1 is indexed, and then the data located in row 1 of the column (index is 1) is printed: 4, as follows:
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name1'] print(col) # 打印该列第二个数据 print(col[1]) # 4 """ 0 1 1 4 2 7 Name: name1, dtype: int64 4 """
2, iloc method, index by integer number
Use sheet.iloc[ ] index, the square brackets are the integer position numbers of the rows and columns (starting from 0 after excluding the column as the row index and the row as the column index) serial number).
a) sheet.iloc[1, 2]: Extract row 2, column 3 data. The first is the row index, the second is the column index
b) sheet.iloc[0: 2]: Extract the first two rowsdata
c) sheet.iloc[0:2, 0:2]: Extract the first two columns data of the first two rows through sharding
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = sheet.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""3. loc method, index by row and column name
Use sheet.loc[ ] index, the square brackets are row and row The name string . The specific usage is the same as iloc , except that the integer index of iloc is replaced by the name index of the row and column. This indexing method is more intuitive to use.
Note: iloc[1: 2] does not contain 2, but loc['row1': 'row2'] does Contains 'row2'.
# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""4. Determine whether the data is empty: np.isnan() / pd.isnull()
1. Use isnan() or of the numpy library The isnull() method of the pandas library determines whether it is equal to nan .
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name2'] print(np.isnan(col[1])) # True print(pd.isnull(col[1])) # True """ True True """
2. Use str() to convert it to a string and determine whether it is equal to 'nan' .
sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""5. Find data that meets the conditions
Let’s understand the following code
# 提取name1 == 1 的行
mask = (sheet['name1'] == 1)
x = sheet.loc[mask]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""6. Modify element value: replace()
sheet['name2'].replace(2, 100, inplace=True) : Change element 2 of column name2 to element 100, and operate in place.
sheet['name2'].replace(2, 100, inplace=True)
print(sheet)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""sheet['name2'].replace(np.nan, 100, inplace=True) : Change the empty element (nan) in the name2 column to element 100, operate in place .
import numpy as np
sheet['name2'].replace(np.nan, 100, inplace=True)
print(sheet)
print(type(sheet.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""7. Add data: [ ]
To add a column, directly use square brackets [name to add] to add.
sheet['name_add'] = [55, 66, 77]: Add a column named name_add with a value of [55, 66, 77]
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('====================================')
# 添加名为 name_add 的列,值为[55, 66, 77]
sheet['name_add'] = [55, 66, 77]
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name_add
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""8. Delete data: del() / drop()
a) del(sheet['name3']): Use the del method to delete
sheet = pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(sheet['name3'])
print(sheet)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""b) sheet.drop('row1', axis=0)
Use the drop method to delete the row1 row. If the column is deleted, the corresponding axis=1.
When the inplace parameter is True, the parameter will not be returned and will be deleted directly on the original data.
When the inplace parameter is False (default), the original data will not be modified, but the modified data will be returned. Data
sheet.drop('row1', axis=0, inplace=True)
print(sheet)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""c)sheet.drop(labels=['name1', 'name2'], axis=1)
Use label=[ ] parameter to delete Multiple rows or columns
# 删除多列,默认 inplace 参数位 False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""9. Save to excel file: to_excel()
1. Save the data in pandas format as an .xlsx file
names = ['a', 'b', 'c'] scores = [99, 100, 99] result_excel = pd.DataFrame() result_excel["姓名"] = names result_excel["评分"] = scores # 写入excel result_excel.to_excel('test3.xlsx')
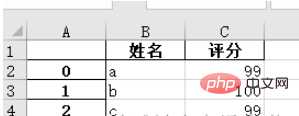
2. Save the modified excel file as an .xlsx file.
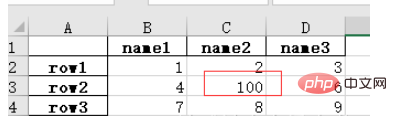
For example, after modifying nan in the original table to 100, save the file:
import numpy as np # 指定第一列为行索引 sheet = pd.read_excel(path, index_col=0) sheet['name2'].replace(np.nan, 100, inplace=True) sheet.to_excel('test2.xlsx')
Open test2.xlsx and the result is as follows:
The above is the detailed content of How to process Excel data with Python's Pandas library?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MinIO Object Storage: High-performance deployment under CentOS system MinIO is a high-performance, distributed object storage system developed based on the Go language, compatible with AmazonS3. It supports a variety of client languages, including Java, Python, JavaScript, and Go. This article will briefly introduce the installation and compatibility of MinIO on CentOS systems. CentOS version compatibility MinIO has been verified on multiple CentOS versions, including but not limited to: CentOS7.9: Provides a complete installation guide covering cluster configuration, environment preparation, configuration file settings, disk partitioning, and MinI
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
When installing PyTorch on CentOS system, you need to carefully select the appropriate version and consider the following key factors: 1. System environment compatibility: Operating system: It is recommended to use CentOS7 or higher. CUDA and cuDNN:PyTorch version and CUDA version are closely related. For example, PyTorch1.9.0 requires CUDA11.1, while PyTorch2.0.1 requires CUDA11.3. The cuDNN version must also match the CUDA version. Before selecting the PyTorch version, be sure to confirm that compatible CUDA and cuDNN versions have been installed. Python version: PyTorch official branch
 How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
CentOS Installing Nginx requires following the following steps: Installing dependencies such as development tools, pcre-devel, and openssl-devel. Download the Nginx source code package, unzip it and compile and install it, and specify the installation path as /usr/local/nginx. Create Nginx users and user groups and set permissions. Modify the configuration file nginx.conf, and configure the listening port and domain name/IP address. Start the Nginx service. Common errors need to be paid attention to, such as dependency issues, port conflicts, and configuration file errors. Performance optimization needs to be adjusted according to the specific situation, such as turning on cache and adjusting the number of worker processes.
