

Greedy algorithm
Classic applications: such as Huffman Coding, Prim and Kruskal minimum spanning tree algorithms, and Dijkstra single-source shortest path algorithm.
Steps of greedy algorithm to solve problems
The first step, when we see this kind of problem, we must first think of the greedy algorithm: for a set of data, we define the limit value and the expected value, and hope to select a few data from it, and satisfy the In the case of limiting values, the expected value is the largest.
By analogy to the example just now, the limit value is that the weight cannot exceed 100kg, and the expected value is the total value of the item. This set of data is 5 kinds of beans. We select a portion of them that weighs no more than 100kg and has the greatest total value.
In the second step, we try to see if this problem can be solved with a greedy algorithm: each time, select the data that contributes the most to the expected value under the current situation and contributes the same amount to the limit value.
Analogy to the example just now, we select the beans with the highest unit price from the remaining beans every time, that is, the beans that contribute the most to the value when the same weight.
The third step, let’s give a few examples to see whether the results produced by the greedy algorithm are optimal. In most cases, just give a few examples to verify it. Strictly proving the correctness of the greedy algorithm is very complicated and requires a lot of mathematical reasoning.
The main reason why the greedy algorithm does not work is that the previous choices will affect the subsequent choices.
Practical Analysis of Greedy Algorithm
1. Share candy
We have m candies and n children. We now want to distribute candies to these children, but there are less candies and more children (m We can abstract this problem into, from n children, select a part of the children to distribute candies, so that the number of satisfied children (expected value) is the largest. The limit value of this problem is the number of candies m.
Every time we find the one with the smallest demand for candy size among the remaining children, and then give him the smallest candy among the remaining candies that can satisfy him. The distribution plan obtained in this way is The plan that satisfies the largest number of children.
2. Coin change
This problem is more common in our daily lives. Suppose we have banknotes of 1 yuan, 2 yuan, 5 yuan, 10 yuan, 20 yuan, 50 yuan, and 100 yuan. Their numbers are c1, c2, c5, c10, c20, c50, and c100 respectively. We now need to use this money to pay K yuan. What is the minimum number of banknotes we need to use?
In life, we must pay with the one with the largest face value first. If it is not enough, continue to use a smaller face value, and so on, and finally use 1 yuan to make up the rest. In the case of contributing the same expected value (number of banknotes), we hope to contribute more, so that the number of banknotes can be reduced. This is a solution to a greedy algorithm.
3. Interval coverage
Suppose we have n intervals, and the starting and ending endpoints of the interval are [l1, r1], [l2, r2], [l3, r3], ..., [ln, rn]. We select a part of the intervals from these n intervals. This part of the interval satisfies that the two intervals are disjoint (the endpoints intersect are not considered intersections). How many intervals can be selected at most?
This processing idea is used in many greedy algorithm problems, such as task scheduling, teacher scheduling, etc.
The solution to this problem is as follows: We assume that the leftmost endpoint of these n intervals is lmin and the rightmost endpoint is rmax. This problem is equivalent to selecting several disjoint intervals and covering [lmin, rmax] from left to right. We sort these n intervals in order from small to large starting endpoints.
Every time we select, the left endpoint does not coincide with the previous covered interval, and the right endpoint is as small as possible, so that the remaining uncovered interval can be as large as possible, and it can be placed More intervals. This is actually a greedy selection method.
How to use greedy algorithm to implement Huffman coding?
Huffman coding uses this unequal length encoding method to encode characters. It is required that between the encodings of each character, there will be no situation where one encoding is the prefix of another encoding. Use a slightly shorter encoding for characters that appear more frequently; use a slightly longer encoding for characters that appear less frequently.
Suppose I have a file containing 1000 characters. Each character occupies 1 byte (1byte=8bits). It takes a total of 8000bits to store these 1000 characters. Is there a more space-saving storage method?
Suppose we find through statistical analysis that these 1000 characters only contain 6 different characters, assuming they are a, b, c, d, e, and f. 3 binary bits can represent 8 different characters. Therefore, in order to minimize storage space, we use 3 binary bits to represent each character. Then it only takes 3000 bits to store these 1000 characters, which saves a lot of space than the original storage method. However, is there a more space-saving storage method?
a(000), b(001), c(010), d(011), e(100), f(101)
Huffman coding is a very effective coding method and is widely used in data compression. Its compression rate is usually between 20% and 90%.
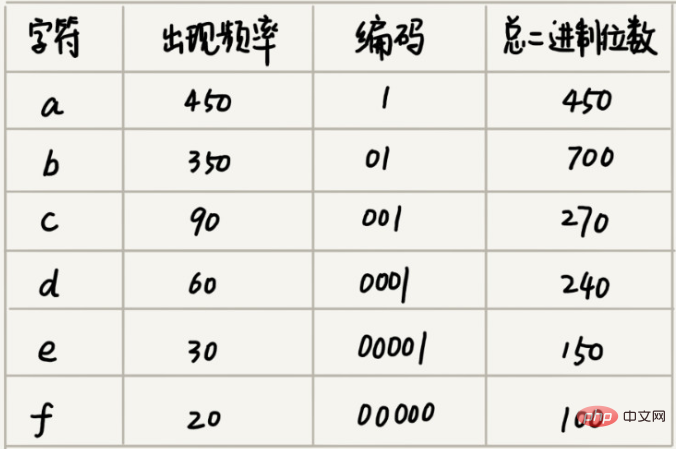
Huffman coding not only examines how many different characters there are in the text, but also examines the frequency of each character. Based on the frequency, codes of different lengths are selected. Huffman coding attempts to use this unequal length coding method to further increase the compression efficiency. How to choose different length codes for characters with different frequencies? Based on greedy thinking, we can use slightly shorter codes for characters that appear more frequently; use slightly longer codes for characters that appear less frequently.
The codes are not of equal length, how to read them and parse them?
For equal-length encoding, it is very simple for us to decompress it. For example, in the example just now, we use 3 bits to represent a character. When decompressing, we read 3-digit binary codes from the text each time and translate them into corresponding characters. However, Huffman codes are not of equal length. Should 1 bit be read each time, or 2 bits, 3 bits, etc. for decompression? This problem makes Huffman coding more complicated to decompress. In order to avoid ambiguity during the decompression process, Huffman encoding requires that between the encodings of each character, there will be no situation where one encoding is the prefix of another encoding.
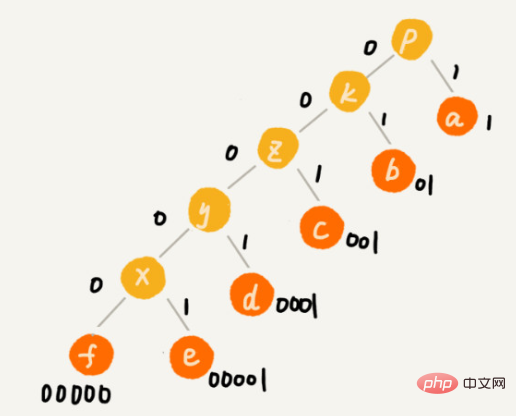
Assume that the frequency of these 6 characters from high to low is a, b, c, d, e, f. We encode them like this. The encoding of any character is not a prefix of another. When decompressing, we will read as long a decompressible binary string as possible every time, so we will not There will be ambiguity. After this encoding and compression, these 1000 characters only require 2100 bits.
Although the idea of Huffman coding is not difficult to understand, How to code different characters with different lengths according to the frequency of occurrence of characters?
Use a large top pile and place characters according to frequency.
Divide and Conquer Algorithm
The core idea of the divide and conquer algorithm is actually four words: divide and conquer, that is, divide the original problem into n smaller sub-problems with a similar structure to the original problem, and recursively Solving these subproblems and then combining their results yields a solution to the original problem.
The divide-and-conquer algorithm is a problem-solving idea, and recursion is a programming technique. In fact, divide-and-conquer algorithms are generally more suitable to be implemented using recursion. In the recursive implementation of the divide-and-conquer algorithm, each level of recursion involves the following three operations:
Decomposition: Decompose the original problem into a series of sub-problems; Solution: Solve each sub-problem recursively. If the sub-problem is small enough, then Direct solution; Merge: merge the results of sub-problems into the original problem. The problems that the divide-and-conquer algorithm can solve generally need to meet the following conditions:
The original problem has the same pattern as the small problems it is decomposed into; The original problem is decomposed into sub-problems that can be solved independently, and the sub-problems can be solved independently. There is no correlation between has decomposition termination conditions, that is to say, when the problem is small enough, it can be solved directly; can be divided into The problem is merged into the original problem, and the complexity of this merge operation cannot be too high, otherwise it will not have the effect of reducing the overall complexity of the algorithm. Analysis of Examples of Application of Divide and Conquer Algorithm
How to program to find the number of ordered pairs or reversed pairs of a set of data?
Compare each number with the number after it to see how many are smaller than it. We record the number of numbers smaller than it as k. In this way, after examining each number, we sum up the k values corresponding to each number. The final sum obtained is the number of pairs in reverse order. However, the time complexity of this operation is O(n^2).
We can divide the array into two halves, A1 and A2, calculate the number of reverse-order pairs K1 and K2 of A1 and A2 respectively, and then calculate the number of reverse-order pairs K3 between A1 and A2. Then the number of reverse-order pairs of array A is equal to K1 K2 K3. With the help of merge sort algorithm
Is there a need to sort 10GB order files according to amount?
We can scan the order first and divide the 10GB file into several amount ranges based on the amount of the order. For example, the order amount between 1 and 100 yuan is placed in a small file, the order amount between 101 and 200 is placed in another file, and so on. In this way, each small file can be loaded into the memory for sorting separately, and finally these ordered small files are merged to form the final ordered 10GB order data.
Backtracking algorithm
Application scenarios: depth-first search, regular expression matching, syntax analysis in compilation principles. Many classic mathematical problems can be solved using the backtracking algorithm, such as Sudoku, eight queens, 0-1 knapsack, graph coloring, traveling salesman problem, total permutation, etc.
The processing idea of backtracking is somewhat similar to enumeration search. We enumerate all solutions and find the one that satisfies our expectations. In order to regularly enumerate all possible solutions and avoid omissions and duplications, we divide the problem-solving process into multiple stages. At each stage, we will face a fork in the road. We first choose a path at random. When we find that this path does not work (does not meet the expected solution), we go back to the previous fork in the road and choose another path. Keep walking.
Eight Queens Problem
We have an 8x8 chessboard and want to put 8 chess pieces (queens) on it. Each chess piece cannot have another chess piece in the row, column, or diagonal.
1.0-1 Backpack
Many scenarios can be abstracted into this problem model. The classic solution to this problem is dynamic programming, but there is also a simple but less efficient solution, which is the backtracking algorithm we are talking about today.
We have a backpack, and the total carrying weight of the backpack is Wkg. Now we have n items, each of which has a different weight and is indivisible. We now want to select a few items and load them into our backpack. How to maximize the total weight of items in a backpack without exceeding the weight that the backpack can carry?
For each item, there are two options, put it in the backpack or not put it in the backpack. For n items, there are 2^n ways to install them. Remove those with a total weight exceeding Wkg, and select the one with a total weight closest to Wkg from the remaining installation methods. However, how can we exhaustively enumerate these 2^n ways of pretending without repetition?
Backtracking method: We can arrange the items in order, and the whole problem is decomposed into n stages, and each stage corresponds to how to choose an item. Process the first item first, choose to load it or not, and then process the remaining items recursively.
Dynamic programming
Dynamic programming is more suitable for solving optimal problems, such as finding maximum values, minimum values, etc. It can significantly reduce time complexity and improve code execution efficiency.
0-1 Backpack problem
For a set of indivisible items of different weights, we need to select some to put into the backpack. On the premise of meeting the maximum weight limit of the backpack, what is the maximum total weight of the items in the backpack?
Thinking:
(1) Divide the entire solution process into n stages, and each stage will decide whether to put an item in the backpack. After the decision is made for each item (to put it in the backpack or not to put it in the backpack), the weight of the items in the backpack will have many situations, that is to say, it will reach many different states, which correspond to the recursive tree, that is, there are many different node.
(2) We merge the repeated states (nodes) of each layer, only record the different states, and then derive the state set of the next layer based on the state set of the previous layer. We can merge the repeated states of each layer to ensure that the number of different states in each layer will not exceed w (w represents the carrying weight of the backpack), which is 9 in the example.
Divide n stages. Each stage is derived based on the previous stage and moves forward dynamically to avoid repeated calculations.
The time complexity of using the backtracking algorithm to solve this problem is O(2^n), which is exponential. So what is the time complexity of the dynamic programming solution?
The most time-consuming part is the two-layer for loop in the code, so the time complexity is O(n*w). n represents the number of items, and w represents the total weight that the backpack can carry. We need to apply for an additional two-dimensional array of n times w 1, which consumes a lot of space. Therefore, sometimes, we will say that dynamic programming is a solution that exchanges space for time.
0-1 Upgraded version of backpack problem
For a set of indivisible items of different weights, different values, we choose to put certain items into the backpack. On the premise of meeting the maximum weight limit of the backpack, the total value of the items that can be loaded into the backpack is the largest. How much is it?
What kind of problems are suitable to be solved by dynamic programming?
Three features of a model
A model: multi-stage decision-making optimal solution model
Three characteristics:
Optimal substructure, the optimal solution to the problem contains the optimal solution to the sub-problem No aftereffects, the first level of meaning Yes, when deriving the state of the later stage, we only care about the state value of the previous stage, not how this state is derived step by step. The second meaning is that once the status of a certain stage is determined, it will not be affected by decisions in subsequent stages. (The latter does not affect the previous.) Repeated sub-problems, different decision sequences, may produce repeated states when reaching a certain same stage. Summary of two dynamic programming problem-solving ideas
1. State transition table method
Generally, problems that can be solved by dynamic programming can be solved by brute force search using the backtracking algorithm. Draw the recursion tree. From the recursion tree, we can easily see whether there are repeated sub-problems and how the repeated sub-problems are generated.
After finding the duplicate sub-problem, we have two ways to deal with it. The first one is to directly use backtracking and add "memo" to avoid duplicate sub-problems. In terms of execution efficiency, this is no different from the solution idea of dynamic programming. The second method is to use dynamic programming, state transition table method.
Let’s first draw a state table. State tables are generally two-dimensional, so you can think of it as a two-dimensional array. Among them, each state contains three variables, rows, columns, and array values. We fill each state in the state table in stages according to the decision-making process, from front to back, and according to the recursive relationship. Finally, we translate this recursive form filling process into code, which is dynamic programming code.
If many variables are needed to represent it, the corresponding state table may be high-dimensional, such as three-dimensional or four-dimensional. At this time, we are not suitable to use the state transition table method to solve it. On the one hand, it is because high-dimensional state transition tables are difficult to draw and represent, and on the other hand, it is because the human brain is really not good at thinking about high-dimensional things.
2. State transition equation method
We need to analyze how a certain problem can be solved recursively through sub-problems, which is the so-called optimal substructure. Based on the optimal substructure, write a recursive formula, which is the so-called state transition equation. With the state transition equation, the code implementation is very simple. Generally speaking, we have two code implementation methods, one is recursion plus "memo" , and the other is iterative recursion .
min_dist(i, j) = w[i][j] min(min_dist(i, j-1), min_dist(i-1, j))
I want to emphasize that not every problem is suitable for both problem-solving ideas. Some problems may be clearer with the first way of thinking, and some problems may be clearer with the second way of thinking. Therefore, you have to consider the specific problem to decide which problem-solving method to use. State transition table methodThe problem-solving idea can be roughly summarized as,Implementation of backtracking algorithm-define state-draw recursion tree-find repeated sub-problems-draw state transition table-according to recursion Push relationship form filling - translate the form filling process into code . The general idea of the state transition equation method can be summarized as, Find the optimal substructure - write the state transition equation - translate the state transition equation into code.
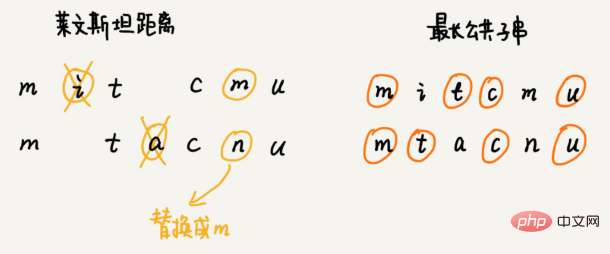
How to quantify the similarity of two strings? Edit distance refers to the minimum number of editing operations required to convert one string into another string (such as adding a character, deleting a character, replacing a character). The larger the edit distance, the smaller the similarity between the two strings; conversely, the smaller the edit distance, the greater the similarity between the two strings. For two identical strings, the edit distance is 0. There are many different calculation methods for edit distance, the more famous ones are Levenshtein distance (Levenshtein distance) and Longest common substring length (Longest common substring length) . Among them, Levinstein distance allows three editing operations of adding, deleting, and replacing characters, and the length of the longest common substring only allows two editing operations of adding and deleting characters. Levenstein distance and the longest common substring length analyze the similarity of strings from two completely opposite perspectives. The size of Levenstein distance represents the difference between two strings; and the size of the longest common substring represents the similarity between two strings. The Levinstein distance of the two strings mitcmu and mtacnu is 3, and the length of the longest common substring is 4. How to calculate Levenstein distance programmatically? This question is to find the minimum number of edits required to change one string into another string. The entire solution process involves multiple decision-making stages. We need to examine in turn whether each character in a string matches the characters in another string, how to deal with it if it matches, and how to deal with it if it does not match. Therefore, this problem conforms to the Multi-stage decision-making optimal solution model. Recommended algorithm Use the distance of vectors to find the similarity. Search: How to use the A* search algorithm to implement the pathfinding function in the game? So how to quickly find a sub-optimal route that is close to the shortest route? This fast path planning algorithm is the A* algorithm we are going to learn today. In fact, the A* algorithm is an optimization and transformation of Dijkstra's algorithm. Use the straight-line distance between the vertex and the end point, that is, the Euclidean distance, to approximately estimate the path length between the vertex and the end point (note: path length and straight-line distance are two concepts) This distance is recorded as h(i) (i represents the number of this vertex). The professional name is heuristic function (heuristic function) because of the Euclidean distance The calculation formula will involve the more time-consuming root calculation, so we generally use another simpler distance calculation formula, that is, the Manhattan distance (Manhattan distance) The Manhattan distance is the distance between two points The sum of the distances between the horizontal and vertical coordinates. The calculation process only involves addition, subtraction and sign bit reversal, so it is more efficient than Euclidean distance. int hManhattan(Vertex v1, Vertex v2) { // Vertex represents the vertex, which is defined later
return Math.abs(v1.x - v2.x) Math.abs(v1.y - v2.y);
}
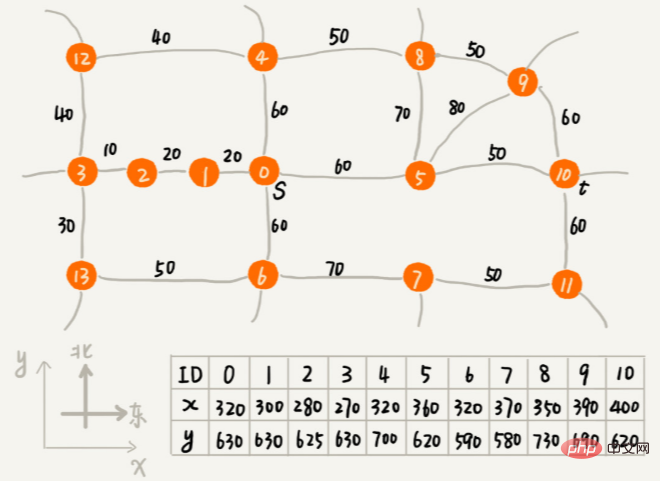
f(i)=g(i) h(i), the path length between the vertex and the starting point g(i), the estimated path length from the vertex to the end point h(i). f(i) The professional name for is evaluation function. A* algorithm is a simple modification of Dijkstra's algorithm. The smallest f(i) is listed first. There are three main differences between it and the code implementation of Dijkstra's algorithm: The way the priority queue is constructed is different. The A* algorithm builds a priority queue based on the f value (that is, the f(i)=g(i) h(i) just mentioned), while the Dijkstra algorithm builds a priority queue based on the dist value (that is, the g( just mentioned) i)) to build a priority queue; A* algorithm will update the f value synchronously when updating the vertex dist value; The conditions for the end of the loop are also different. The Dijkstra algorithm ends when the end point is dequeued, and the A* algorithm ends once the traversal reaches the end point. 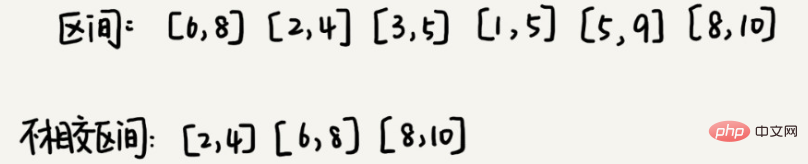
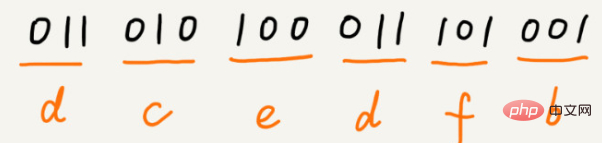

The above is the detailed content of What common algorithms are commonly used in Java development?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



