
 Technology peripherals
AI
EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced
Technology peripherals
AI
EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced
EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced

Recently, EMNLP 2022, the top conference in the field of natural language processing, was held in Abu Dhabi, the capital of the United Arab Emirates.

A total of 4190 papers were submitted to this year’s conference. In the end, 829 papers were accepted (715 long papers, 114 papers), and the overall acceptance rate was 20%, not much different from previous years.
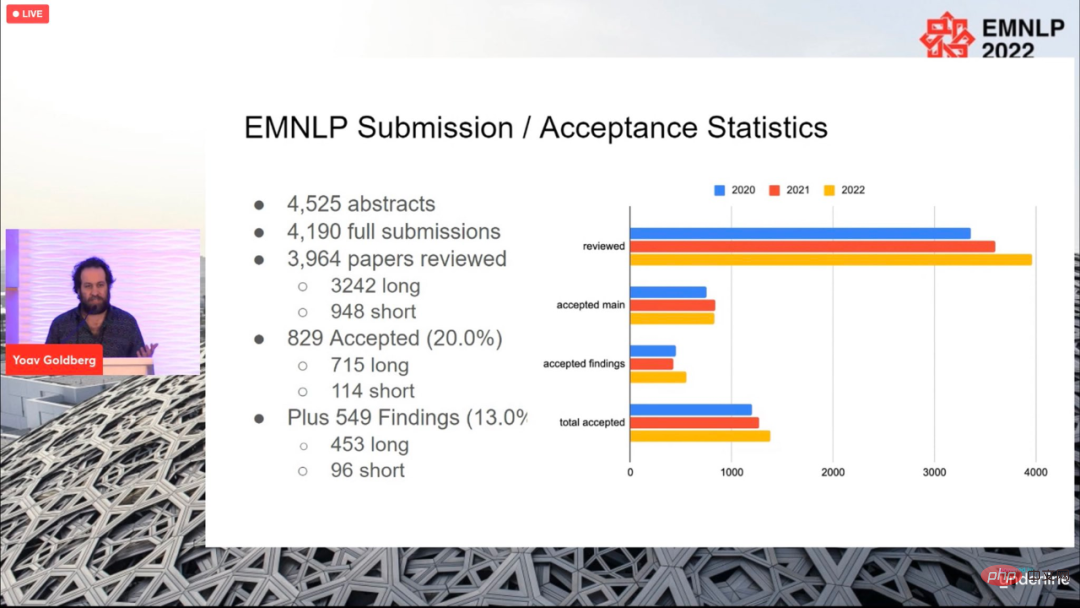
The conference ended on December 11, local time, and the paper awards for this year were also announced, including Best Long Paper (1), Best Short Paper (1 piece), Best Demo Paper (1 piece).
Best Long Paper

Paper: Abstract Visual Reasoning with Tangram Shapes
- Authors: Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi
- Organization: Kang Nair University, New York University, Allen Institute, Princeton University
- Paper link: https://arxiv.org/pdf/2211.16492.pdf
Paper abstract: In this paper, the researcher introduces "KiloGram", a user A resource library for studying abstract visual reasoning in humans and machines. KiloGram greatly improves existing resources in two ways. First, the researchers curated and digitized 1,016 shapes, creating a collection that was two orders of magnitude larger than those used in existing work. This collection greatly increases coverage of the entire range of naming variation, providing a more comprehensive perspective on human naming behavior. Second, the collection treats each tangram not as a single overall shape, but as a vector shape made up of the original puzzle pieces. This decomposition enables reasoning about whole shapes and their parts. The researchers used this new collection of digital jigsaw puzzle graphics to collect a large amount of textual description data, reflecting the high diversity of naming behavior.
We leveraged crowdsourcing to extend the annotation process, collecting multiple annotations for each shape to represent the distribution of annotations it elicited rather than a single sample. A total of 13,404 annotations were collected, each describing a complete object and its divided parts.
KiloGram’s potential is extensive. We used this resource to evaluate the abstract visual reasoning capabilities of recent multimodal models and observed that pre-trained weights exhibited limited abstract reasoning capabilities that improved greatly with fine-tuning. They also observed that explicit descriptions facilitate abstract reasoning by both humans and models, especially when jointly encoding language and visual input.
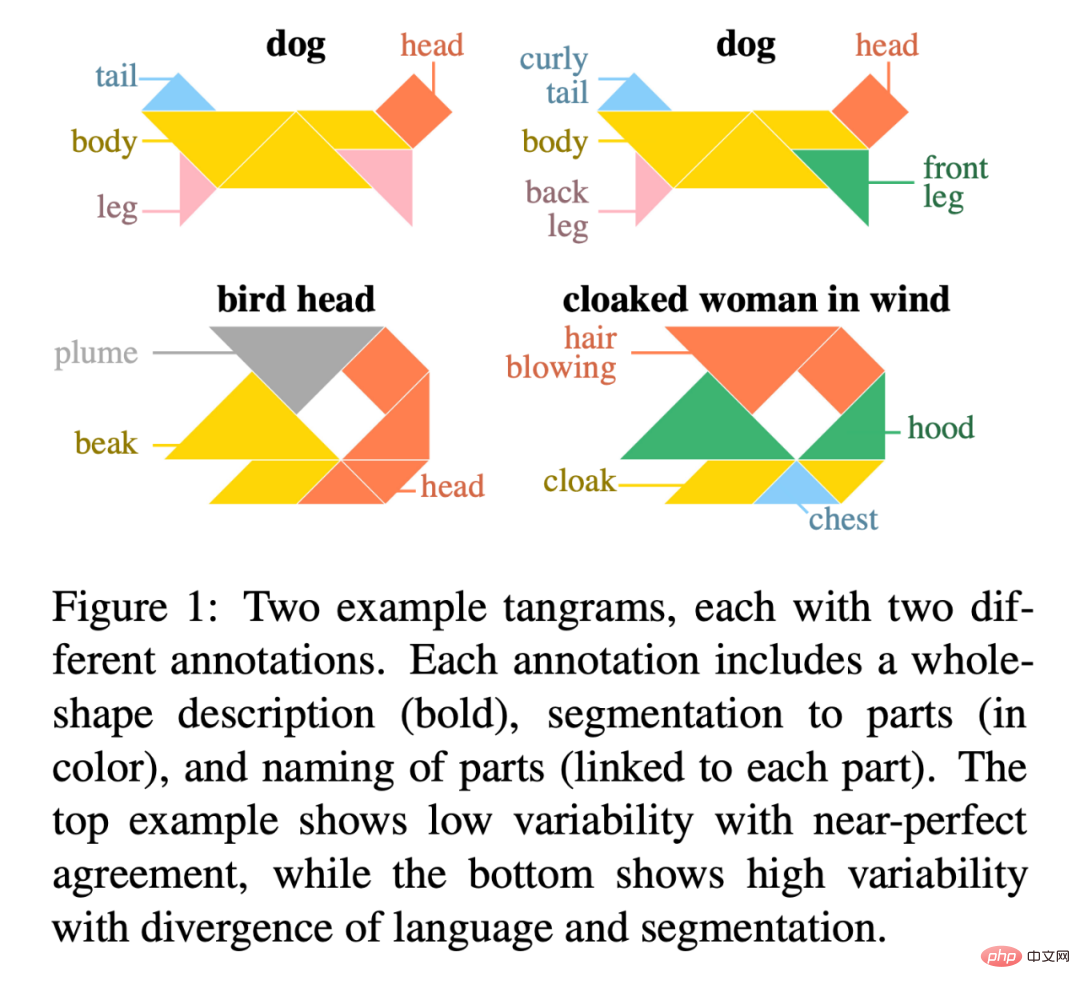
Figure 1 is an example of two tangrams, each with two different annotations. Each annotation includes a description of the entire shape (in bold), a segmentation of the parts (in color), and a name for each part (connected to each part). The upper example shows low variability for near perfect agreement, while the lower example shows high variability for language and segmentation divergence.
##KiloGram Address: https://lil.nlp .cornell.edu/kilogram
The best long paper nomination for this conference was won by two researchers, Kayo Yin and Graham Neubig.
Paper: Interpreting Language Models with Contrastive Explanations
- Author: Kayo Yin, Graham Neubig
Paper abstract: Model interpretability methods are often used to explain the decisions of NLP models on tasks such as text classification. , the output space of these tasks is relatively small. However, when applied to language generation, the output space often consists of tens of thousands of tokens, and these methods cannot provide informative explanations. Language models must consider various features to predict a token, such as its part of speech, number, tense, or semantics. Because existing explanatory methods combine evidence for all these features into a single explanation, this is less interpretable to human understanding.
To distinguish between different decisions in language modeling, researchers have explored language models that focus on contrastive explanations. They look for input tokens that stand out and explain why the model predicted one token but not another. Research demonstrates that contrastive explanations are much better than non-contrastive explanations at validating major grammatical phenomena, and that they significantly improve contrastive model simulatability for human observers. The researchers also identified groups of contrastive decisions for which the model used similar evidence and were able to describe which input tokens the model used in various language generation decisions.
Code address: https://github.com/kayoyin/interpret-lm
Best short paper

Paper: Topic-Regularized Authorship Representation Learning
- ## Author: Jitkapat Sawatphol, Nonthakit Chaiwong, Can Udomcharoenchaikit, Sarana Nutanong
- Institution: VISTEC Institute of Science and Technology, Thailand
Abstract :In this study, the researchers proposed Authorship Representation Regularization, a distillation framework that can improve cross-topic performance and can also handle unseen authors. This approach can be applied to any authorship representation model. Experimental results show that in the cross-topic setting, 4/6 performance is improved. At the same time, researchers' analysis shows that in data sets with a large number of topics, training shards set across topics have topic information leakage problems, thus weakening their ability to evaluate cross-topic attributes.
Best Demo Paper
Paper: Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
- ##Authors: Leandro von Werra, Lewis Tunstall, Abhishek Thakur, Alexandra Sasha Luccioni, etc.
- Organization: Hugging Face
- Paper link: https://arxiv.org/pdf/2210.01970.pdf
Paper abstract:Evaluation is a key part of machine learning (ML), and this study introduces Evaluate and Evaluation on Hub - a set of tools that help evaluate Tools for models and datasets in ML. Evaluate is a library for comparing different models and datasets, supporting various metrics. The Evaluate library is designed to support reproducibility of evaluations, document the evaluation process, and expand the scope of evaluations to cover more aspects of model performance. It includes more than 50 efficient specification implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementation and evaluation results.
Project address: https://github.com/huggingface/evaluate
In addition, the researcher also launched Evaluation on the Hub, the platform enables free, large-scale evaluation of over 75,000 models and 11,000 datasets on Hugging Face Hub with the click of a button.The above is the detailed content of EMNLP 2022 conference officially concluded, best long paper, best short paper and other awards announced. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV2023, the top computer vision conference held in Paris, France, has just ended! This year's best paper award is simply a "fight between gods". For example, the two papers that won the Best Paper Award included ControlNet, a work that subverted the field of Vincentian graph AI. Since being open sourced, ControlNet has received 24k stars on GitHub. Whether it is for diffusion models or the entire field of computer vision, this paper's award is well-deserved. The honorable mention for the best paper award was awarded to another equally famous paper, Meta's "Separate Everything" ”Model SAM. Since its launch, "Segment Everything" has become the "benchmark" for various image segmentation AI models, including those that came from behind.
 NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
Since Neural Radiance Fields was proposed in 2020, the number of related papers has increased exponentially. It has not only become an important branch of three-dimensional reconstruction, but has also gradually become active at the research frontier as an important tool for autonomous driving. NeRF has suddenly emerged in the past two years, mainly because it skips the feature point extraction and matching, epipolar geometry and triangulation, PnP plus Bundle Adjustment and other steps of the traditional CV reconstruction pipeline, and even skips mesh reconstruction, mapping and light tracing, directly from 2D The input image is used to learn a radiation field, and then a rendered image that approximates a real photo is output from the radiation field. In other words, let an implicit three-dimensional model based on a neural network fit the specified perspective
 Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Generative AI has taken the artificial intelligence community by storm. Both individuals and enterprises have begun to be keen on creating related modal conversion applications, such as Vincent pictures, Vincent videos, Vincent music, etc. Recently, several researchers from scientific research institutions such as ServiceNow Research and LIVIA have tried to generate charts in papers based on text descriptions. To this end, they proposed a new method of FigGen, and the related paper was also included in ICLR2023 as TinyPaper. Picture paper address: https://arxiv.org/pdf/2306.00800.pdf Some people may ask, what is so difficult about generating the charts in the paper? How does this help scientific research?
 Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Just as the AAAI 2023 paper submission deadline was approaching, a screenshot of an anonymous chat in the AI submission group suddenly appeared on Zhihu. One of them claimed that he could provide "3,000 yuan a strong accept" service. As soon as the news came out, it immediately aroused public outrage among netizens. However, don’t rush yet. Zhihu boss "Fine Tuning" said that this is most likely just a "verbal pleasure". According to "Fine Tuning", greetings and gang crimes are unavoidable problems in any field. With the rise of openreview, the various shortcomings of cmt have become more and more clear. The space left for small circles to operate will become smaller in the future, but there will always be room. Because this is a personal problem, not a problem with the submission system and mechanism. Introducing open r
 The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
Since it was first held in 2017, CoRL has become one of the world's top academic conferences in the intersection of robotics and machine learning. CoRL is a single-theme conference for robot learning research, covering multiple topics such as robotics, machine learning and control, including theory and application. The 2023 CoRL Conference will be held in Atlanta, USA, from November 6th to 9th. According to official data, 199 papers from 25 countries were selected for CoRL this year. Popular topics include operations, reinforcement learning, and more. Although CoRL is smaller in scale than large AI academic conferences such as AAAI and CVPR, as the popularity of concepts such as large models, embodied intelligence, and humanoid robots increases this year, relevant research worthy of attention will also
 CVPR 2023 rankings released, the acceptance rate is 25.78%! 2,360 papers were accepted, and the number of submissions surged to 9,155
Apr 13, 2023 am 09:37 AM
CVPR 2023 rankings released, the acceptance rate is 25.78%! 2,360 papers were accepted, and the number of submissions surged to 9,155
Apr 13, 2023 am 09:37 AM
Just now, CVPR 2023 issued an article saying: This year, we received a record 9155 papers (12% more than CVPR2022), and accepted 2360 papers, with an acceptance rate of 25.78%. According to statistics, the number of submissions to CVPR only increased from 1,724 to 2,145 in the 7 years from 2010 to 2016. After 2017, it soared rapidly and entered a period of rapid growth. In 2019, it exceeded 5,000 for the first time, and by 2022, the number of submissions had reached 8,161. As you can see, a total of 9,155 papers were submitted this year, indeed setting a record. After the epidemic is relaxed, this year’s CVPR summit will be held in Canada. This year it will be a single-track conference and the traditional Oral selection will be cancelled. google research
 Microsoft's new hot paper: Transformer expands to 1 billion tokens
Jul 22, 2023 pm 03:34 PM
Microsoft's new hot paper: Transformer expands to 1 billion tokens
Jul 22, 2023 pm 03:34 PM
As everyone continues to upgrade and iterate their own large models, the ability of LLM (large language model) to process context windows has also become an important evaluation indicator. For example, the star model GPT-4 supports 32k tokens, which is equivalent to 50 pages of text; Anthropic, founded by a former member of OpenAI, has increased Claude's token processing capabilities to 100k, which is about 75,000 words, which is roughly equivalent to summarizing "Harry Potter" with one click "First. In Microsoft's latest research, they directly expanded Transformer to 1 billion tokens this time. This opens up new possibilities for modeling very long sequences, such as treating an entire corpus or even the entire Internet as one sequence. For comparison, common
