
 Technology peripherals
AI
Flying Paddle is designed and practiced for automatic parallelism in heterogeneous scenarios.
Technology peripherals
AI
Flying Paddle is designed and practiced for automatic parallelism in heterogeneous scenarios.
Flying Paddle is designed and practiced for automatic parallelism in heterogeneous scenarios.


1. Background introduction
Before introducing automatic parallelism, let’s think about why automatic parallelism is needed? On the one hand, there are different model structures, and on the other hand, there are various parallel strategies. There is generally a many-to-many mapping relationship between the two. Assuming that we can implement a unified model structure to meet various task requirements, will our parallel strategy achieve convergence on this unified model structure?
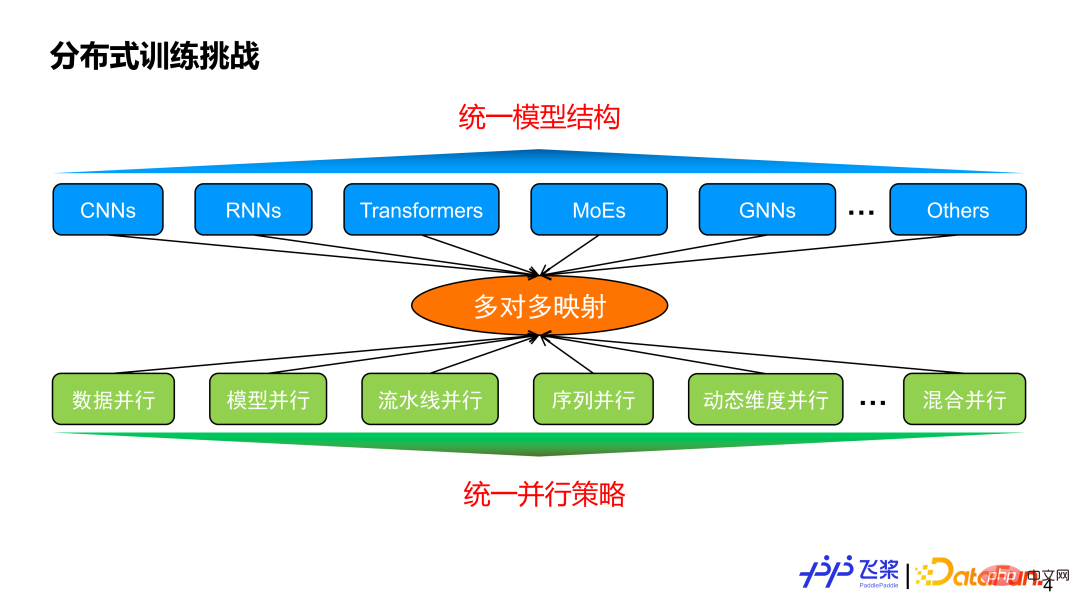
The answer is no, because the parallel strategy is not only related to the model structure, but also The size of the model and the actual machine resources used are closely related. This reflects the value of automatic parallelism. Its goal is: after the user is given a model and the machine resources used, it can automatically help the user choose a better or optimal parallel strategy for efficient execution.
Here is a list of some jobs that I am personally interested in. It may not be complete. I would like to discuss the current status and history of automatic parallelism with you. It is roughly divided into several dimensions: the first dimension is the degree of automatic parallelism, which is divided into fully automatic and semi-automatic; the second dimension is the parallel granularity, which provides parallel strategies for each Layer or for each operator. Or tensors to provide parallel strategies; the third is representation ability, which is simplified into two categories: SPMD (Single Program Multiple Data) parallelism and Pipeline parallelism; the fourth is characteristics, and here is a list of related work that I personally think are more distinctive. place; the fifth is supporting hardware, mainly writing the largest type and quantity of hardware supported by related work. Among them, the parts marked in red are mainly enlightening points for the automatic parallel development of flying paddles.
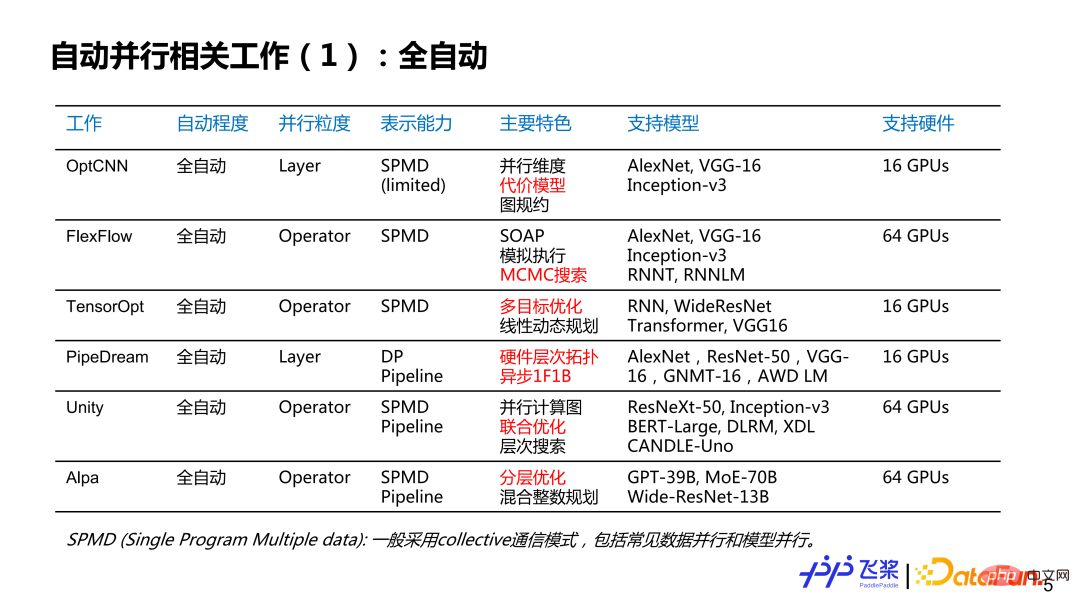
##For fully automatic parallelism, we can see that the parallel granularity is determined by coarse The development process from granularity to fine-graining; the representation capability is from the relatively simple SPMD to the very general SPMD and Pipeline; the supported models are from simple CNN to RNN to the more complex GPT; although it supports multiple machines and multiple cards, But the overall scale is not particularly large.
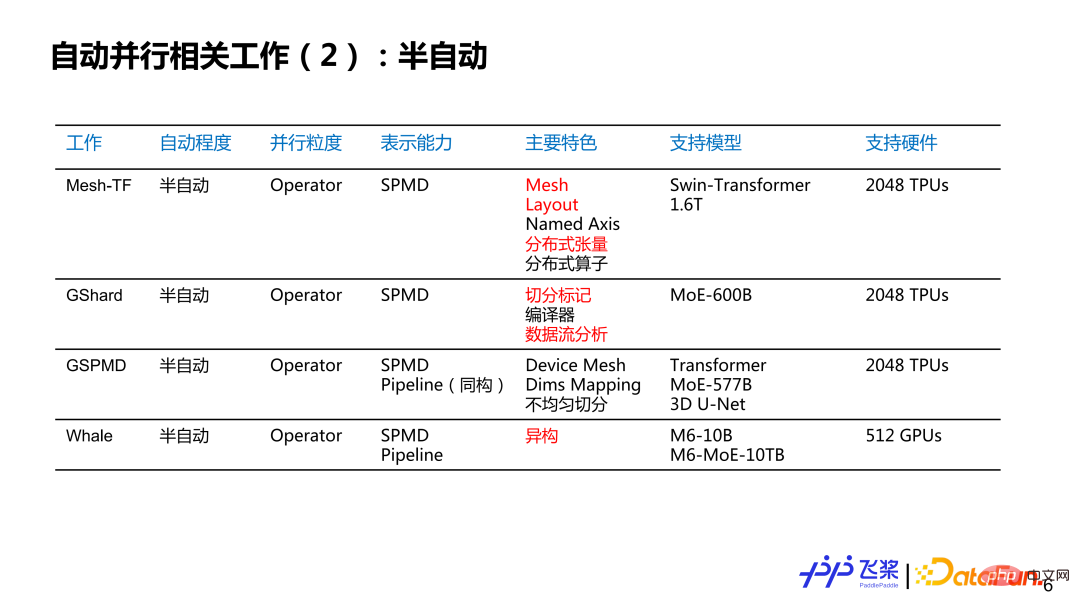
For semi-automatic parallelism, the parallel granularity is basically based on the operator. , and the representation capabilities range from simple SPMD to complete SPMD plus Pipeline's parallel strategy, the model support scale reaches hundreds of billions and trillions, and the number of hardware used reaches the kilocard level.
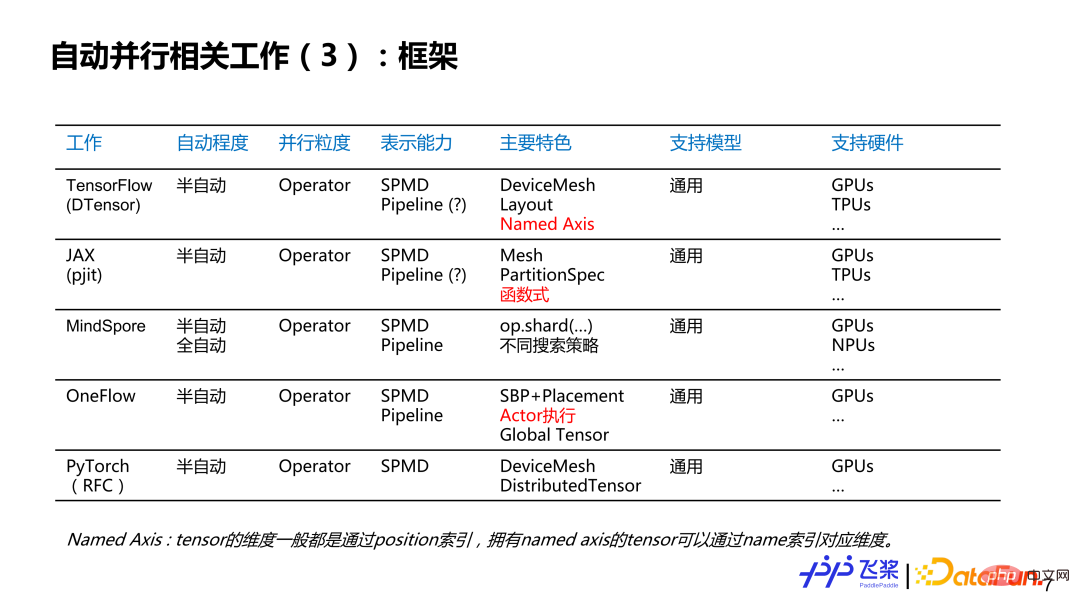
From a framework perspective, we can see that the existing framework is basically The semi-automatic mode has been supported or planned to be supported, and the parallel granularity has also developed to operator granularity. The representation capabilities basically use the complete representation of SPMD plus Pipeline, and are oriented to various models and various hardware.

##Here is a summary of some personal thoughts:
① The first point is that the distributed strategy is gradually unified in the underlying representation.
② Second point, semi-automatic will gradually become a distributed programming paradigm of the framework, while fully automatic will be explored and implemented based on specific scenarios and empirical rules. . ③ The third point is to achieve the ultimate end-to-end performance, which requires joint tuning of parallel strategies and optimization strategies. Generally, complete distributed training includes 4 specific processes. The first is model segmentation. Whether it is manual parallelization or automatic parallelization, the model needs to be divided into multiple tasks that can be parallelized. The second is resource acquisition. We can prepare the equipment resources we need for training by building it ourselves or applying from the platform. ; Then there is task placement (or task mapping), which means placing the divided tasks on the corresponding resources; finally there is distributed execution, which means tasks on each device are executed in parallel and synchronized and interacted through message communication. There are some problems with some current mainstream solutions: on the one hand, they may only consider some processes in distributed training, or only focus on some processes; the second is that they rely too much on the experience of experts Rules, such as model segmentation and resource allocation; finally, the lack of awareness of tasks and resources during the entire training process. 2. Architecture design
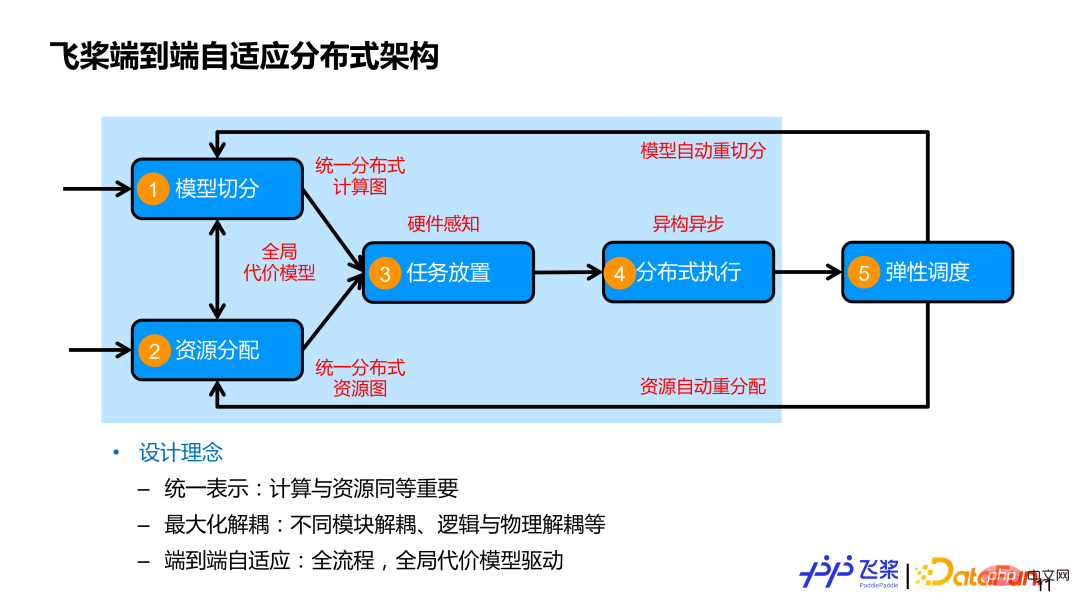
The end-to-end adaptive distributed training architecture designed by Feipiao comprehensively considers the basis of 4 processes Above, a fifth process is added, namely flexible scheduling. Our core design concepts mainly include these three points:
First, computing and resources are expressed in a unified manner, and computing and resources are equally important. Often people are more concerned about how to segment the model, but less attention is paid to resources. On the one hand, we use a unified distributed computing graph to represent various parallel strategies; on the other hand, we use a unified distributed resource graph to model various machine resources, which can represent isomorphic, It can also represent heterogeneous resource connection relationships, and also includes the computing and storage capabilities of the resources themselves.
Second, maximize decoupling. In addition to decoupling between modules, we will also decouple logical segmentation from physical placement and distributed execution, so that we can better implement different models in different Cluster resources perform efficiently.
Third, end-to-end adaptation covers the comprehensive processes involved in distributed training, and uses a global representative model to drive adaptive decisions on parallel strategies or resource placement to replace manual customization as much as possible. decision-making. The part framed in light blue in the above picture is the automatic parallelism related work introduced in this report.
1. Unified distributed computing graph
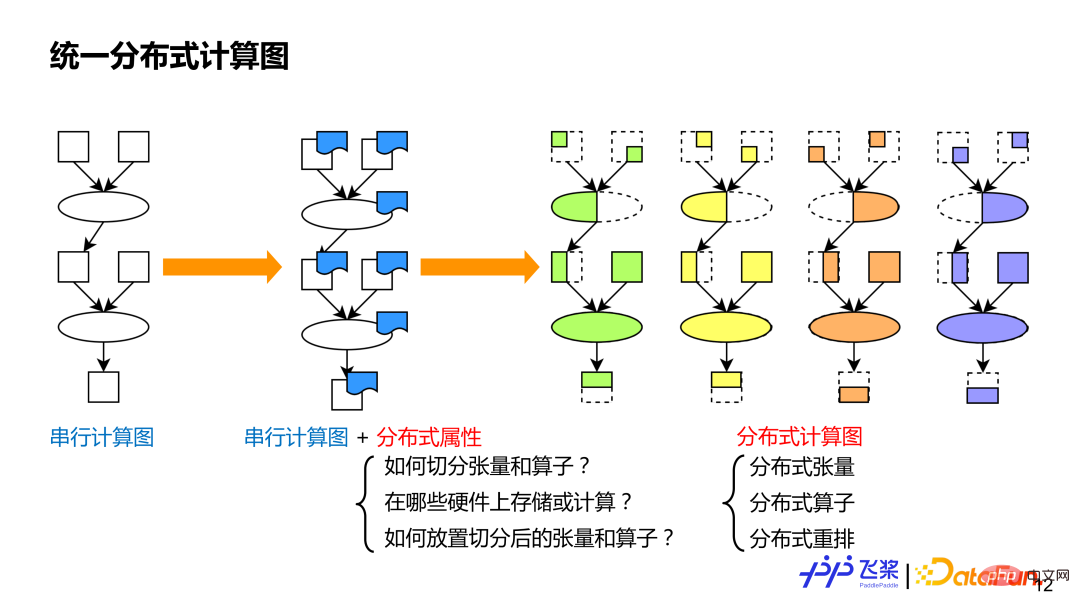
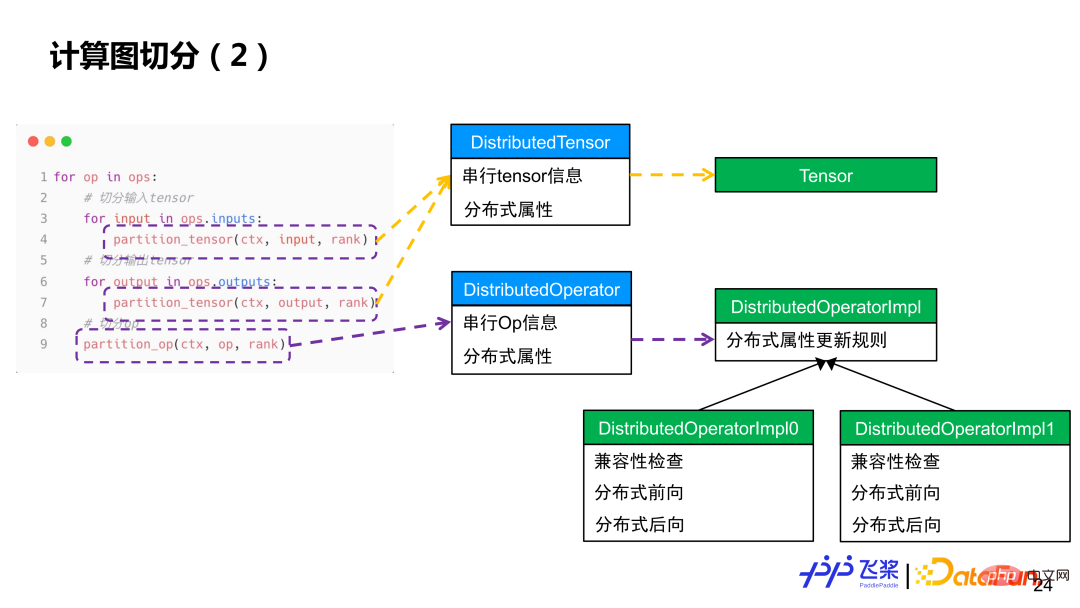
The first is a unified distributed computing graph. The purpose of unification is to facilitate us to express various existing parallel strategies in a unified way, which is conducive to automated processing. As we all know, serial calculation graphs can represent various models. Similarly, on the basis of serial calculation graphs, we add distributed attributes to each operator and tensor to form a distributed calculation graph. This kind of The fine-grained approach can represent existing parallel strategies, and the semantics will be richer and more general, and it can also represent new parallel strategies. The distributed attributes in the distributed computing graph mainly include three aspects of information: 1) It needs to indicate how to split the tensor or how to split the operator; 2) It needs to indicate which resources are used for distributed computing; 3) How to split it The resulting tensor or operator is mapped to the resource. Compared with serial computing graphs, distributed computing graphs have three basic concepts: distributed tensors, which are similar to serial tensors; distributed operators, which are similar to serial operators; distributed rearrangements, which are distributed Unique to computational graphs.
(1) Distributed tensor
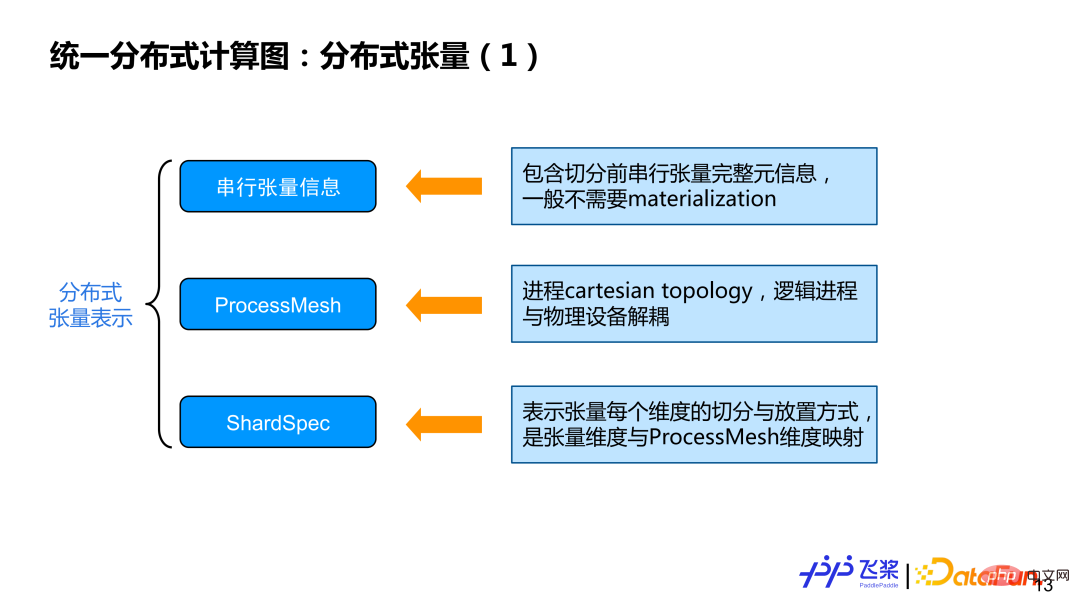
First, introduce the three aspects of information included in distributed tensors:
① Serial tensor information: Mainly contains some meta-information such as tensor shape, dtype, etc. Generally, actual calculation does not require instantiation of serial tensors.
② ProcessMesh: The cartesion topology representation of the process is different from DeviceMesh. The reason why we use ProcessMesh is mainly to hope that the logical process can be connected with the physical device. A decoupling, which facilitates more efficient task mapping.
③ ShardSpec: is used to indicate which dimension of ProcessMesh is used to split each dimension of the serial tensor , please see the example below for details.
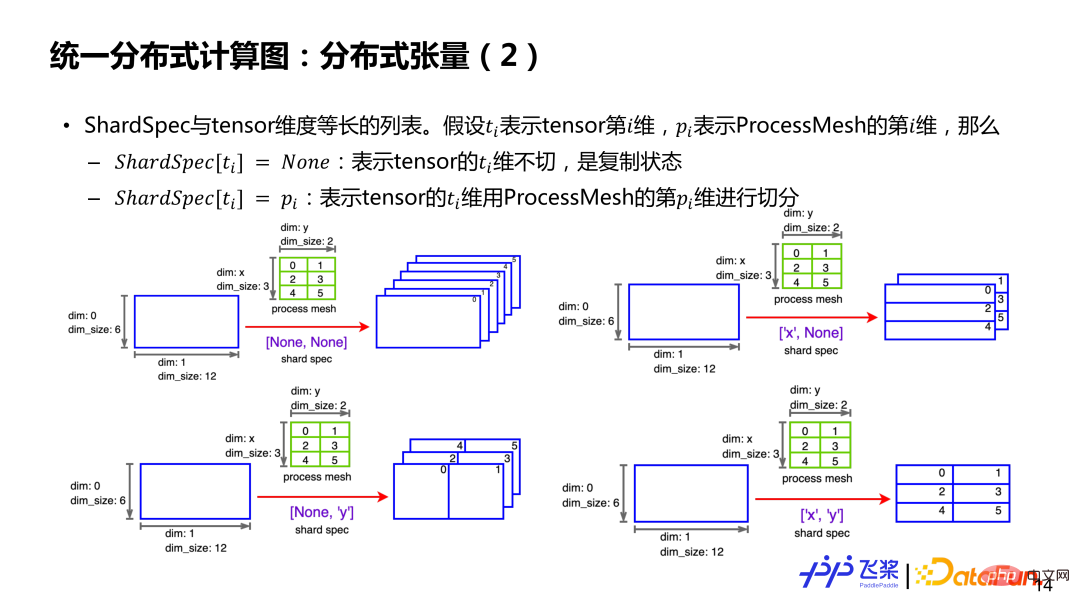
If there is a two-dimensional 6*12 tensor and a 3*2 ProcessMesh (the first dimension is x, the second dimension is y, and the elements are process IDs). If ShardSpec is [None, None], it means that the 0th and 2nd dimensions of the tensor are not divided, and there is a full tensor on each process. If ShardSpec is ['x', 'y'], it means that the x-axis of ProcessMesh is used to cut the 0th dimension of the tensor, and the y-axis of ProcessMesh is used to cut the 1st dimension of the tensor, so that each process has a 2*6 Local tensor of size. In short, through ProcessMesh and ShardSpec and the serial information before the tensor is split, it is possible to represent the splitting situation of a tensor on the relevant process.
(2) Distributed operator
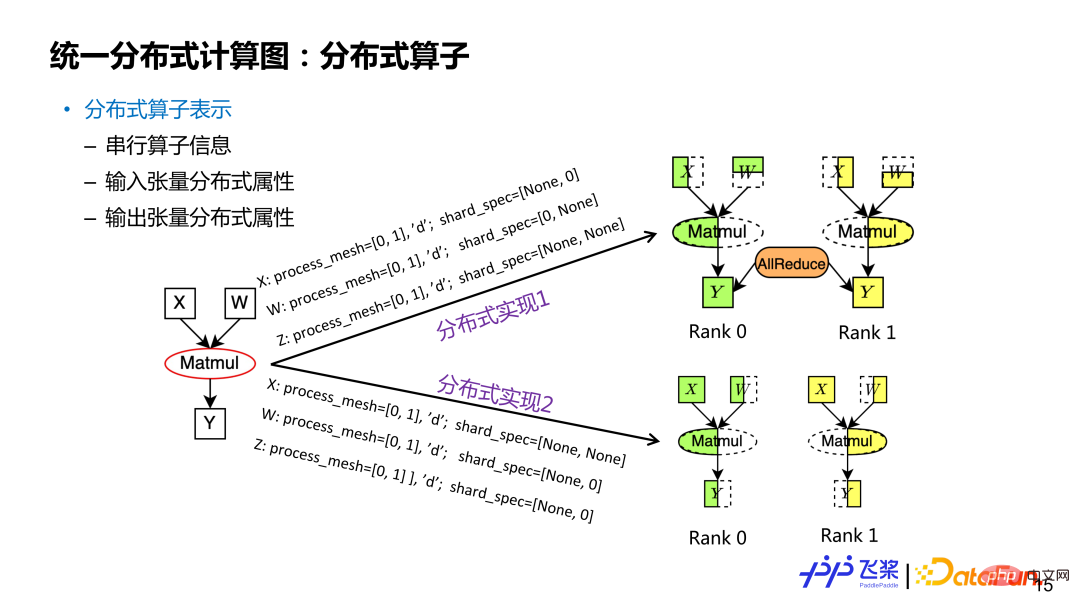
##Distributed operator The representation is based on distributed tensors and includes serial operator information, distributed properties of input and output tensors. Similarly, a distributed tensor may correspond to multiple slicing methods. The distributed attributes in distributed operators are different and correspond to different slicing methods. Taking the rectangular multiplication Y=X*W operator as an example, if the input and output distribution attributes are different, they correspond to different distributed operator implementations (distribution attributes include ProcessMesh and ShardSpec). For a distributed operator, the ProcessMesh of its input and output tensors is the same.
(3) Distributed rearrangement
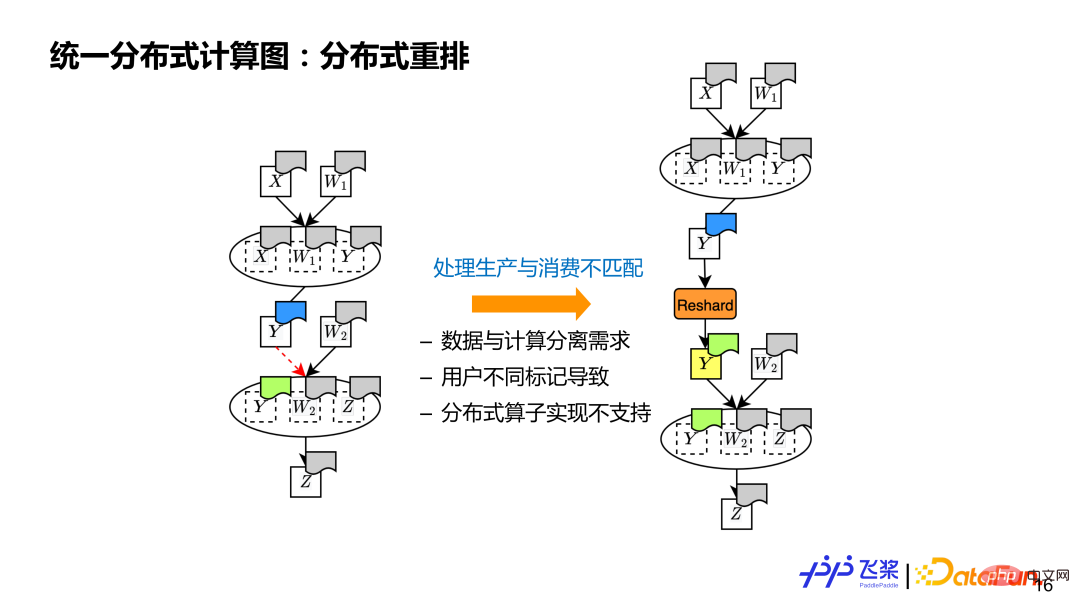
The last one is distributed rearrangement, which is a concept that must be possessed by distributed computing graphs to handle situations where the distribution properties of the source tensor and the destination tensor are different. For example, there are two operators in the calculation. The previous operator produces y, which is different from the next operator using the distributed attribute of y (indicated by different colors in the figure). At this time, we need to insert an additional Reshard operation to perform it through communication. The essence of tensor distributed rearrangement is to deal with the mismatch between production and consumption.
There are three main reasons for the mismatch: 1) It supports the separation of data and calculation, so there are different requirements for tensors and operators that use it. Distributed attributes; 2) Supports user-defined marking of distributed attributes. Users may mark different distributed attributes for tensors and operators using them; 3) The underlying implementation of distributed operators is limited. If there is an input or output distribution If the formula attribute is not supported, distributed rearrangement is also required.
2. Unified distributed resource map
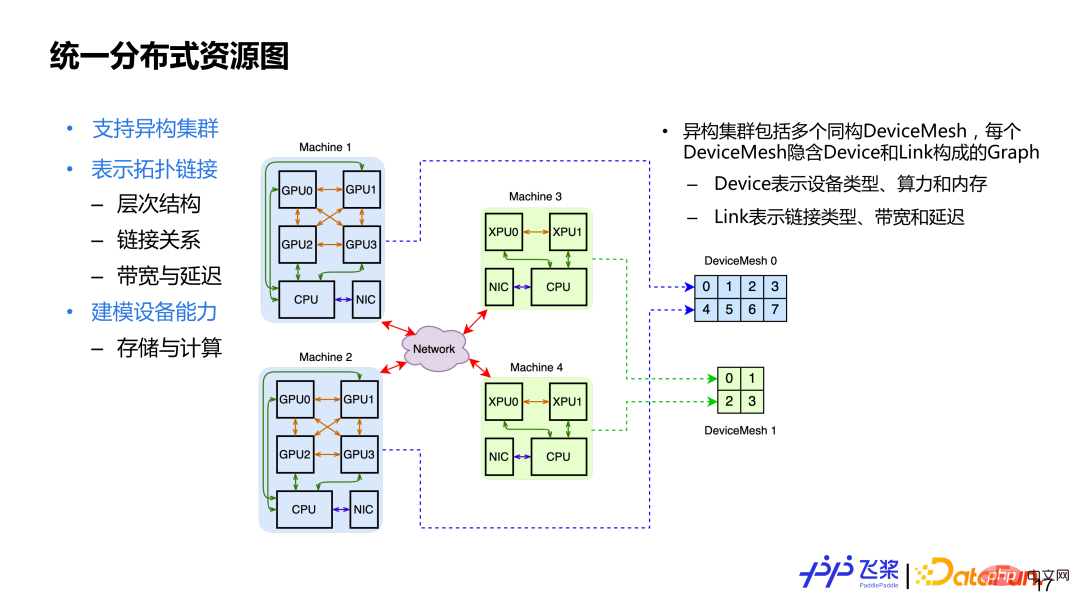
After introducing the three basic concepts of the unified distributed computing graph, let’s look at the unified distributed resource graph. The main design considerations are: 1) Support heterogeneous clusters. Heterogeneous clusters means that the cluster may have CPU, GPU, and XPU resources. ; 2) Represents topological connections, which covers the hierarchical connection relationships of the cluster, including the quantification of connection capabilities, such as bandwidth or latency; 3) Modeling of the device itself, including the storage and computing capabilities of a device. In order to meet the above design requirements, we use Cluster to represent distributed resources, which contains multiple isomorphic DeviceMesh. Each DeviceMesh will contain a Graph composed of Device links.
Here is an example. As shown in the above picture, there are 4 machines, including 2 GPU machines and 2 XPU machines. For 2 GPU machines, one isomorphic DeviceMesh will be used, and for 2 XPU machines, another isomorphic DeviceMesh will be used. For a fixed cluster, its DeviceMesh is fixed, and the user operates ProcessMesh, which can be understood as an abstraction of DeviceMesh. The user can reshape and slice at will, and finally the ProcessMesh process will be uniformly mapped to the DeviceMesh device.
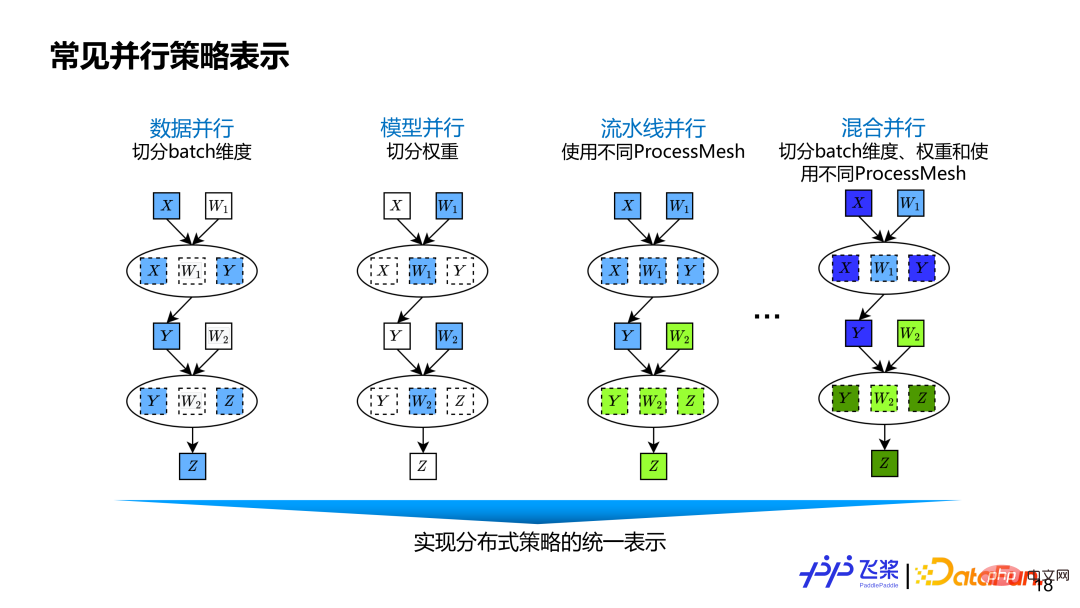
is represented by the fine-grained distributed computing graph based on tensors and operators. It can cover existing parallel strategies as well as new parallel strategies that may appear in the future. Data parallelism is to split the Batch dimension of the data tensor. The model segments weight-related dimensions in parallel. Pipeline parallelism is represented by different ProcessMesh, which can be expressed as more flexible Pipeline parallelism. For example, a Pipeline Stage can connect multiple Pipeline Stages, and the shapes of ProcessMesh used by different Stages can be different. The pipeline parallelism of some other frameworks is achieved through Stage Number or Placement, which is not flexible and versatile enough. Hybrid parallelism is a mixture of data parallelism, tensor model parallelism and pipeline parallelism.
3. Key Implementation
The front is the design of the automatic parallel architecture of the flying paddle and the introduction of some abstract concepts. Based on the previous foundation, let’s introduce the internal implementation process of automatic parallelization of flying paddles through the example of layer 2 FC network.
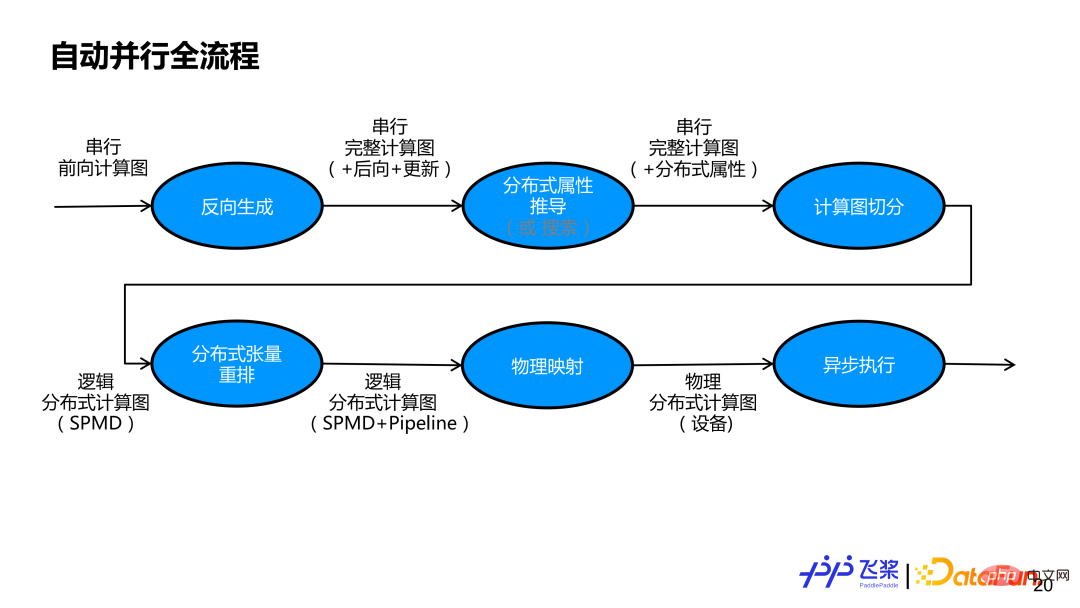
The above picture is the entire automatic parallel flow chart of the flying paddle. First, we will perform reverse generation based on a serial forward calculation graph to obtain a complete calculation graph including forward, backward and update subgraphs. Then, it is necessary to clarify the distributed properties of each tensor and each operator in the network. Either a semi-automatic derivation method or a fully automatic search method can be used. This report mainly explains the semi-automatic derivation method, which is to derive the distributed properties of other unlabeled tensors and operators based on a small number of user labels. After derivation through distributed properties, each tensor and each operator in the serial calculation graph has its own distributed properties. Based on the distributed attributes, the serial calculation graph is first transformed into a logical distributed calculation graph that supports SPMD parallelism through automatic segmentation modules, and then through distributed rearrangement, a logical distributed calculation graph that supports Pipeline parallelism is realized. The generated logical distributed computing graph will be transformed into a physical distributed computing graph through physical mapping. Currently, only one-to-one mapping of one process and one device is supported. Finally, the physical distributed computing graph is turned into an actual task dependency graph and handed over to the asynchronous executor for actual execution.
1. Distributed attribute derivation
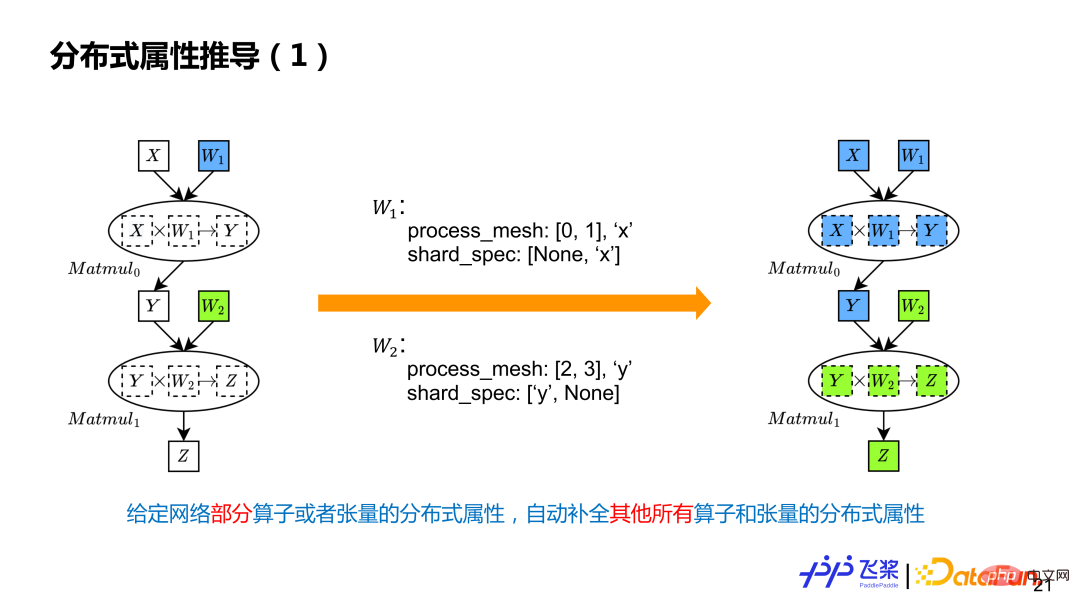
Distributed attribute derivation is Given the distributed properties of some tensors and operators in the calculation graph, the distributed properties of all other tensors and operators are automatically completed. The example is two Matmul calculations. The user only marked two parameter distributed attributes, which means that W1 performs column cutting on processes 0 and 1, and W2 performs row cutting on processes 2 and 3. There are two different ProcessMesh. Use Different colors indicate.
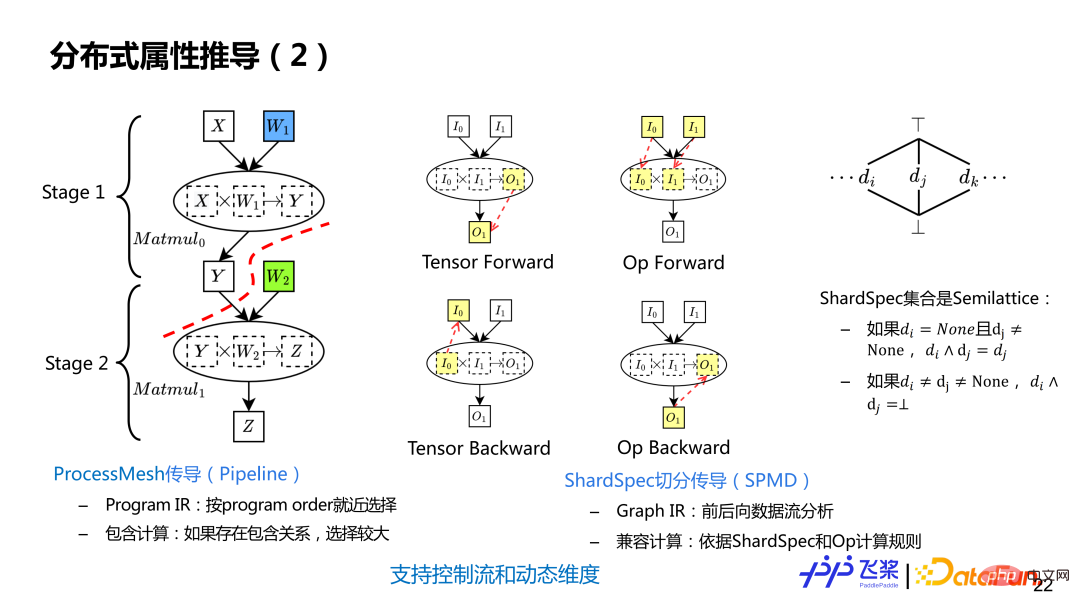
Distributed attribute derivation is divided into two steps: 1) First conduct ProcessMesh transmission to implement Pipeline segmentation; 2) Then conduct ShardSpec transmission to implement SPMD segmentation within a Stage. ProcessMesh derivation uses the flying paddle linear Program lR, and uses the nearest selection strategy to perform derivation according to the static Program Order. It supports inclusive calculations, that is, if there are two ProcessMesh, one is larger and the other is smaller, the larger one is selected as the final ProcessMesh. ShardSpec derivation uses the flying paddle SSA Graph IR to perform forward and backward data flow analysis for derivation. The reason why data flow analysis can be used is because ShardSpec semantics satisfies the Semilattice property of data flow analysis. Data flow analysis can theoretically guarantee convergence. By combining forward and backward analysis, any position mark information in the calculation graph can be propagated to the entire calculation graph, instead of only propagating in one direction.
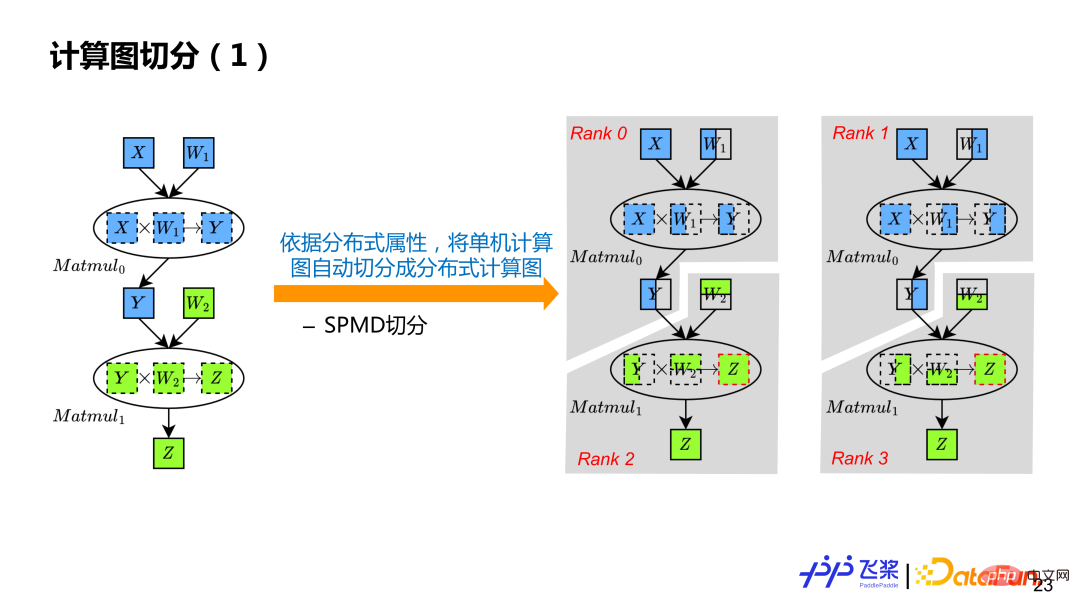
Based on distributed attribute derivation, each tensor sum in the graph is calculated serially Each operator has its own distributed attributes, so that the calculation graph can be automatically segmented based on the distributed attributes. According to the example, the single-machine serial calculation graph is transformed into four calculation graphs Rank0, Rank1, Rank2, and Rank3.
Simply put, each operator will be traversed, and the sum of The output is divided into tensors, and then each operator is calculated and divided. Tensor segmentation will use the Distributed Tensor object to construct a Local Tensor object, while operator segmentation will use the Distributed Operator object to select the corresponding distributed implementation based on the distribution attributes of the actual input and output, similar to the distribution of operators from a single-machine framework to the Kernel. process.
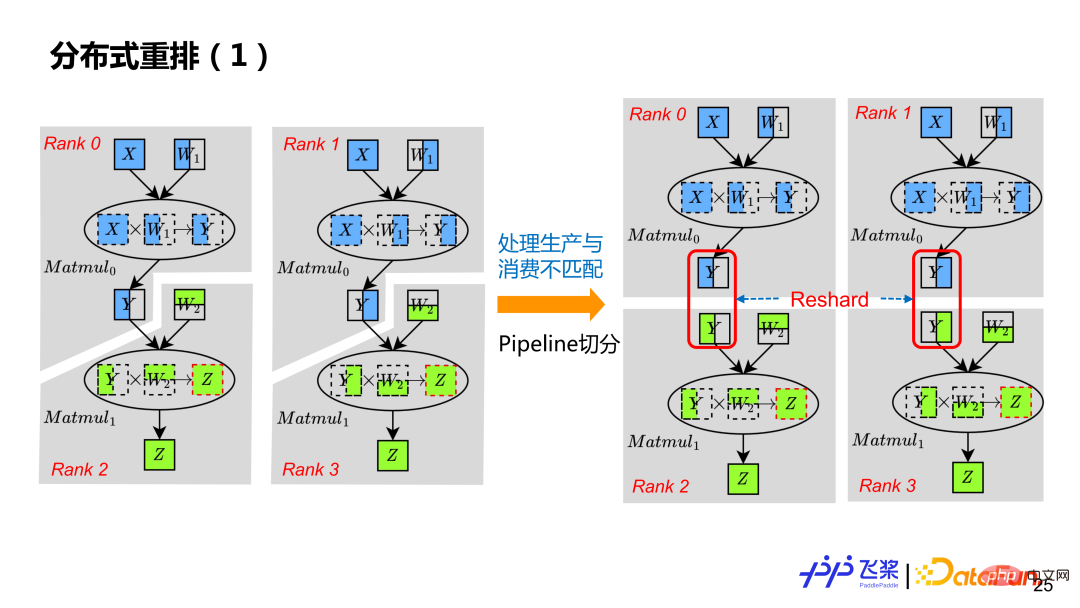
Through the previous automatic segmentation, you can only obtain the distributed computing graph that supports SPMD parallelism . In order to support Pipeline parallelism, it also needs to be processed through distributed rearrangement, so that by inserting a suitable Reshard operation, each Rank in the example has its own truly independent calculation graph. Although the Y of Rank0 in the left picture is the same as the Y of Rank2, the segmentation is the same, but because they are on different ProcessMesh, the distribution attributes of production and consumption do not match, so Reshard also needs to be inserted.
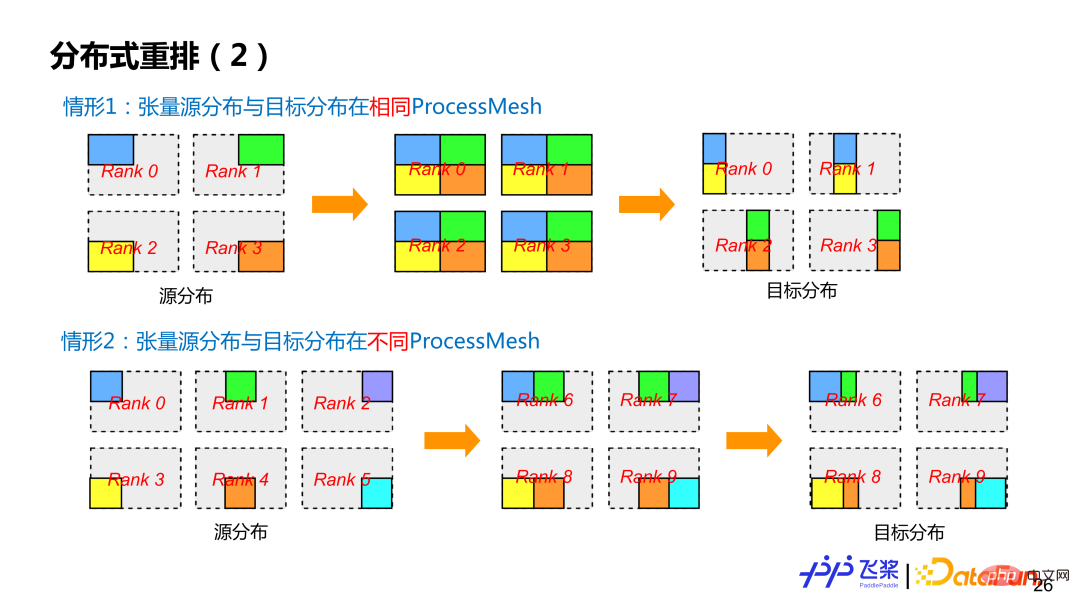
Flying Paddle currently supports two types of distributed rearrangement. The first category is the more common source tensor distribution and the target tensor distribution on the same ProcessMesh, but the source tensor distribution and the target tensor distribution use different slicing methods (that is, the ShardSpec is different). The second category is that the source tensor distribution and the target tensor are distributed on different ProcessMesh, and the ProcessMesh size can be different, such as the 0-5 process and the 6-9 process in case 2 in the figure. In order to reduce communication as much as possible, Flying Paddle also performs related optimizations on Reshard operations.
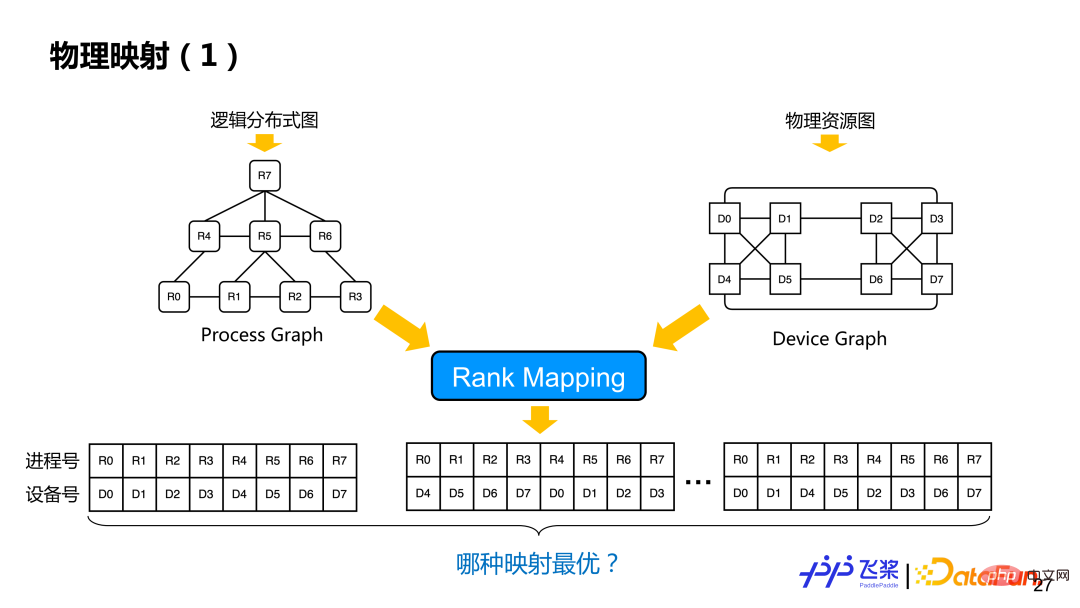
After distributed rearrangement, a logical distributed computing graph is obtained. The process has not yet been decided at this time. and specific device mapping. Based on the logical distributed computing graph and the previously unified resource representation graph, physical mapping operations are performed, which is Rank Mapping, which is to find an optimal mapping solution from multiple mapping solutions (which device a process is mapped to specifically). .
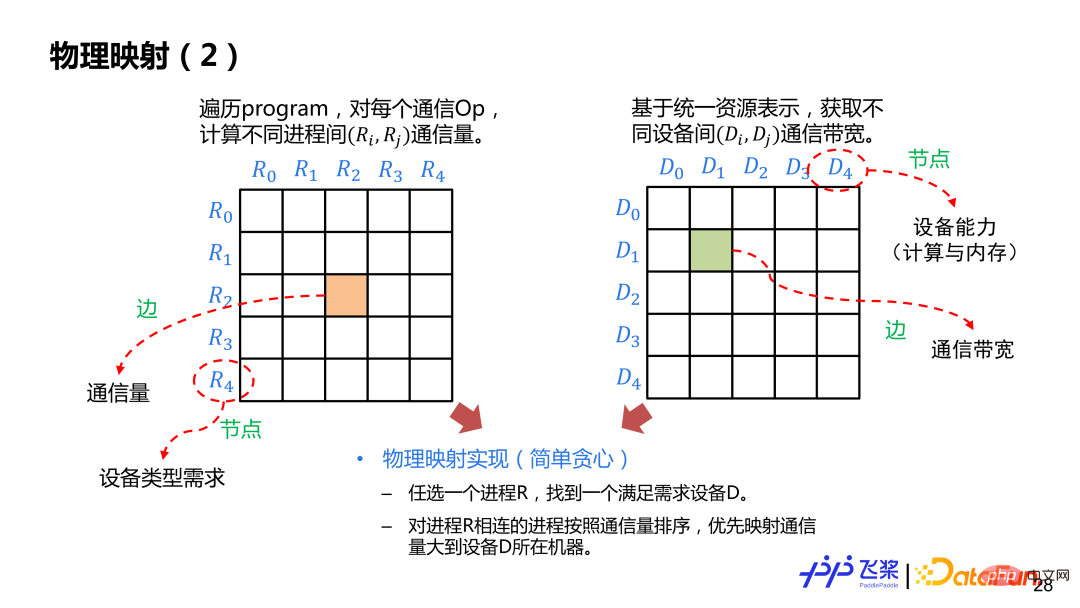
Here is a relatively simple implementation based on greedy rules. First, build the adjacency table between processes and inter-process communication. The edges represent the communication volume and the nodes represent the device requirements. Then build the adjacency table between devices. The edges represent the communication bandwidth and the nodes represent the device computing and memory. We will randomly select a process R and place it on the device D that meets the needs. After placing it, we will select the process with the greatest communication volume with R and place it on other devices of the machine where D is located. This method will be used until all process mappings are completed. During the mapping process, it is necessary to determine whether the selected device matches the device type required by the process graph, as well as the required calculation amount and memory.
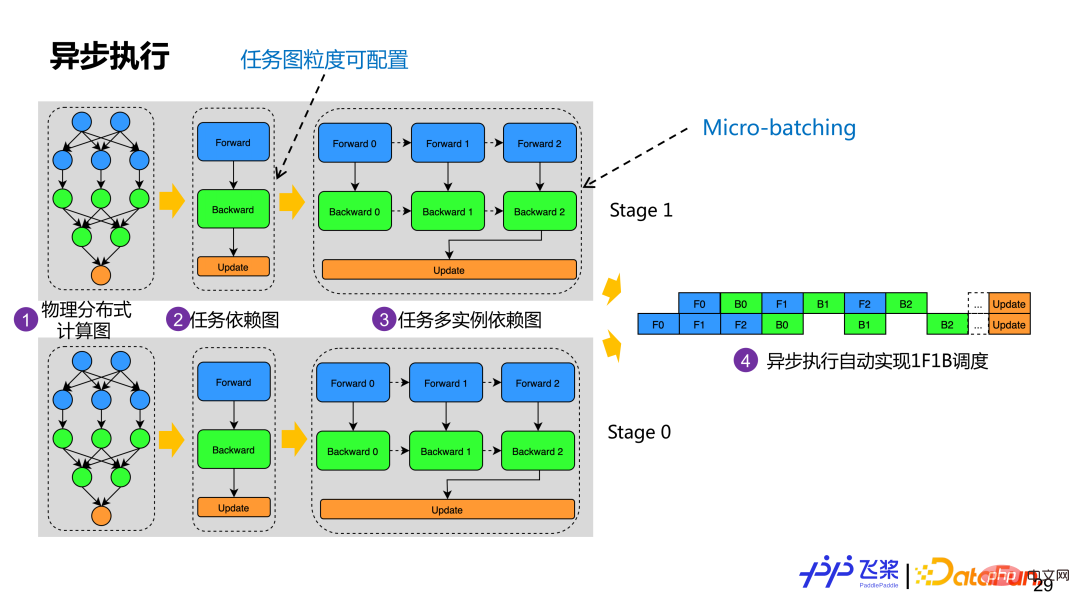
##After passing the physical mapping, we will build the physical distributed network based on the obtained Actual task dependency graph. The example in the figure is to build a task dependency graph based on the forward, backward and update roles of the calculation graph. Operators with the same role will form a task. In order to support micro-batching optimization, a task dependency graph will generate multiple task instance dependency graphs. Although each instance has the same calculation logic, it uses different memory. Currently, Flying Paddle will automatically build a task graph based on the calculation graph roles, but users can customize task construction according to appropriate granularity. After each process has a task multi-instance dependency graph, it will be executed asynchronously based on the Actor mode, and 1F1B execution scheduling can be automatically realized through the message-driven method.
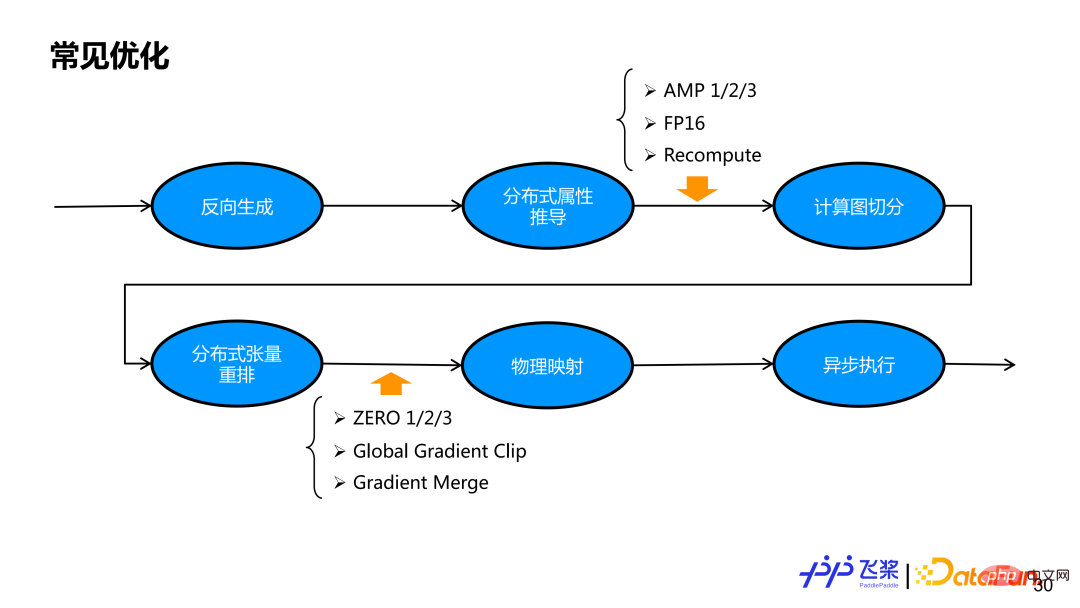
Based on the entire process above, we have implemented an automatic parallelization with relatively complete functions. But only the parallel strategy cannot obtain a better end-to-end performance, so we also need to add corresponding optimization strategies. For automatic parallelization of flying paddles, we will add some optimization strategies before automatic segmentation and after network segmentation. This is because some optimizations are more natural to implement in serial logic, and some optimizations are easier to implement after segmentation. Through a unified optimization pass management mechanism, we can ensure the free combination of parallel strategies and optimization strategies in automatic parallelization of flying paddles.
4. Application Practice
The application practice is introduced below.
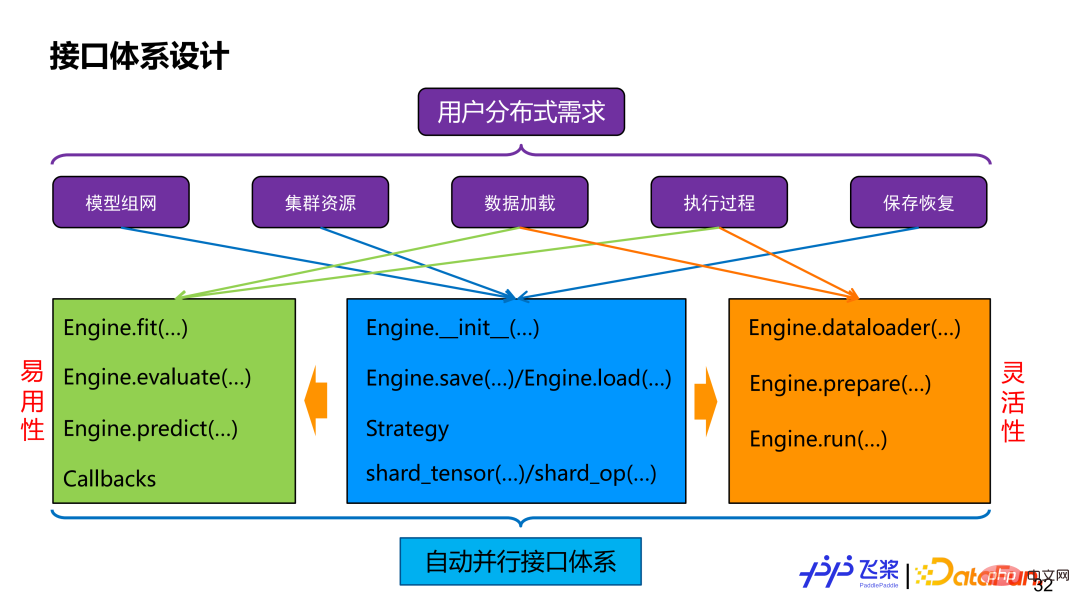
The first is the interface. No matter how it is implemented, users will ultimately use what we have through the interface. Automatic parallel capabilities provided. If the user's distributed requirements are dismantled, it includes model network segmentation, resource representation, distributed data loading, distributed execution process control, distributed saving and recovery, etc. To meet these needs, we provide an Engine class that combines ease of use with flexibility. In terms of ease of use, it provides high-level APIs, can support customized callbacks, and the distributed process is transparent to users. In terms of flexibility, it provides low-level APIs, including distributed dataloader construction, automatic parallel graph cutting and execution, and other interfaces, allowing users to have more fine-grained control. The two will share interfaces such as shard_tensor, shard_op, save and load.
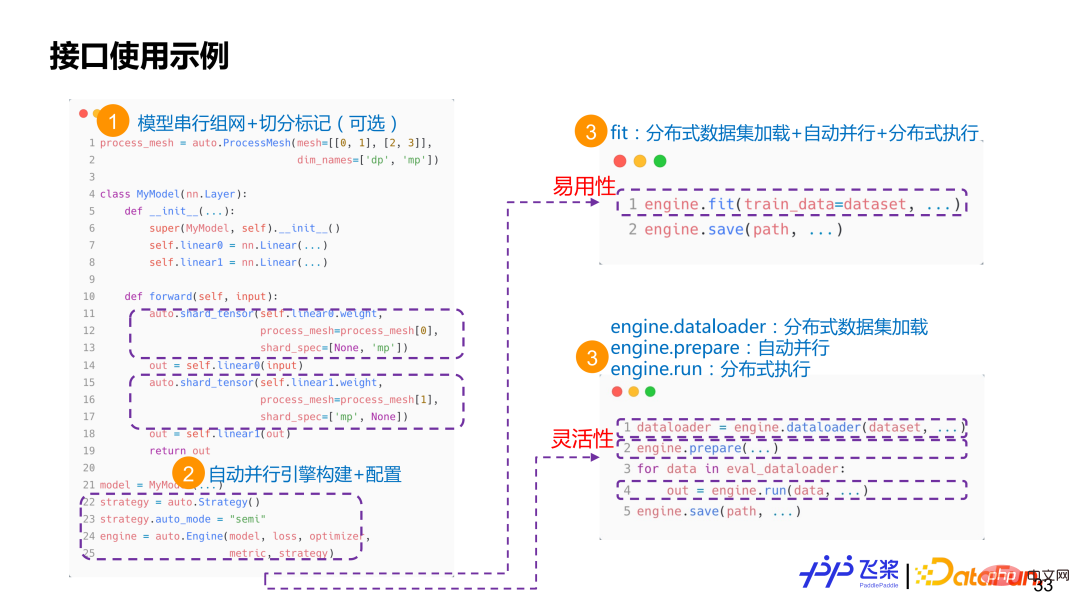
There are two labeled interfaces shard_op and shard_tensor. Among them, shard_op can mark either a single operator or the entire Module, which is a functional formula. The picture above is a very simple usage example. First, use the existing API of Flying Paddle to conduct a serial network, in which we will use shard_tensor or shard_op for non-intrusive distributed attribute marking. Then, build an automatic parallel engine and pass in model-related information and configuration. At this time, the user has two options. One option is to directly use the fit /evaluate/predict high-order interface, and the other option is to use the dataloader prepare run interface. If you choose the fit interface, the user only needs to pass the Dataset, and the framework will automatically load the distributed data set, automatically compile the parallel process and execute distributed training. If you choose the dataloader prepare run interface, users can decouple distributed data loading, automatic parallel compilation and distributed execution, allowing for better single-step debugging.
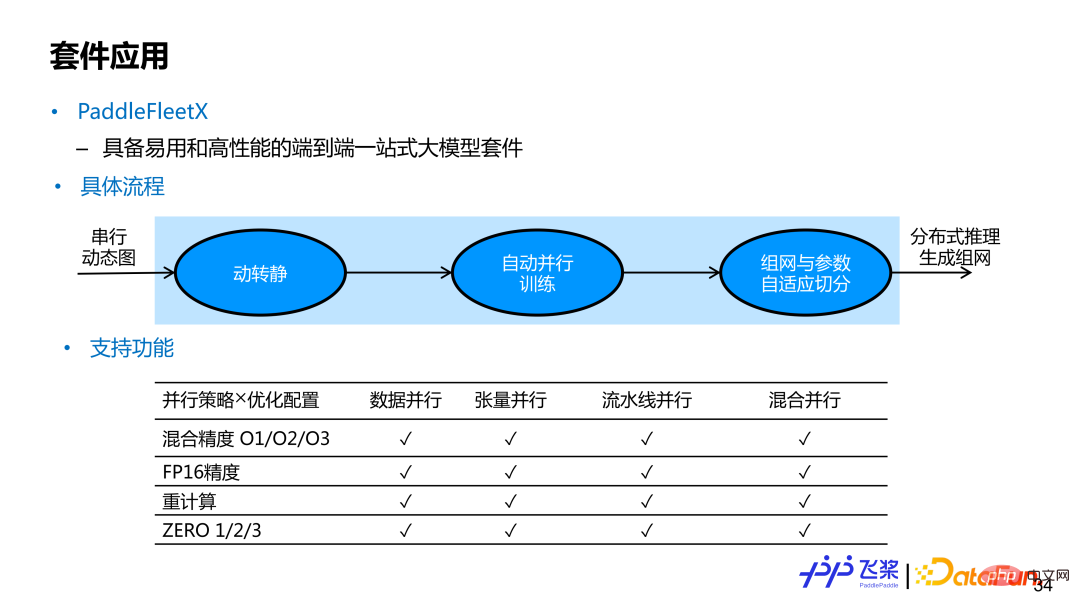
PaddleFleetX is an end-to-end one-stop solution with ease of use and high performance Large model suite with support for automatic parallelization capabilities. If users want to use the automatic parallel end-to-end function of the flying paddle, they only need to provide a serial dynamic graph model network. After obtaining the user's dynamic graph serial network, the internal implementation will use the flying paddle dynamic to static module to convert the dynamic graph single-card network into a static graph single-card network, and then automatically compile in parallel, and finally conduct distributed training. . During inference generation, the machine resources used may be different from those used during training. The internal implementation will also perform adaptive parameter segmentation of parameters and networking. Currently, the automatic parallelism in PaddleFleetX covers commonly used parallel strategies and optimization strategies, and supports any combination of the two. For generated tasks, it also supports automatic segmentation of While control flow.
5. Summary and Outlook

飞There is still a lot of work being done on automatic paddle parallelism. The current features can be summarized in the following aspects:
First of all, a unified distributed computing graph can support The complete distributed strategy of SPMD and Pipeline can support the separated representation of storage and calculation;
#Second, the unified distributed resource graph can support Modeling and representation of heterogeneous resources;
Third, support the organic combination of parallel strategies and optimization strategies;
Fourthly, it provides a relatively complete interface system;
Finally, as a key component, it supports the end-to-end automatic operation of the flying propeller. Adapt to distributed architecture.
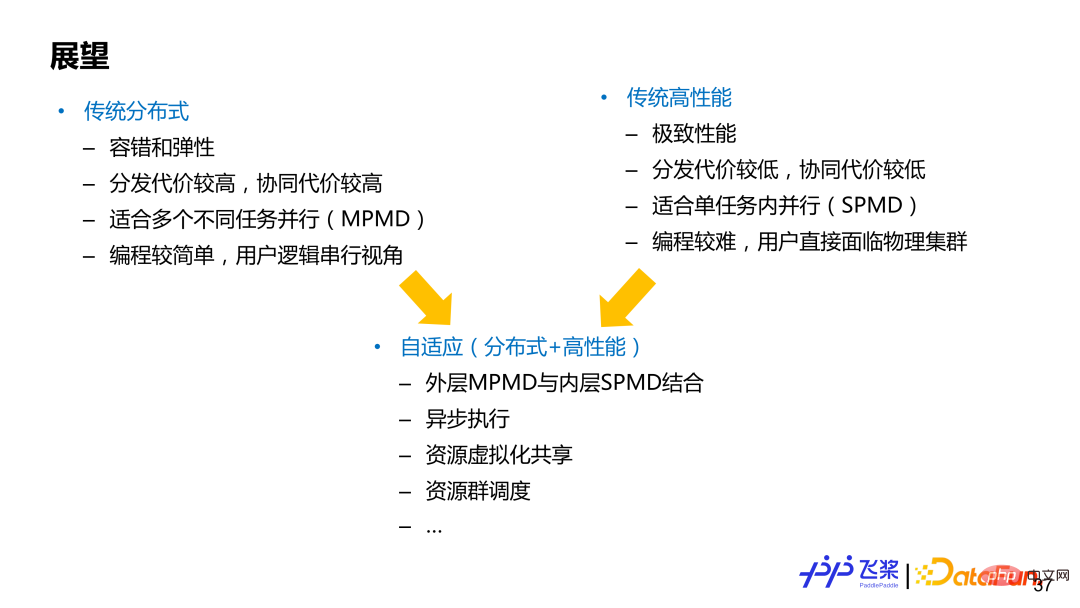
Parallelism can generally be divided into two fields (no clear demarcation), one is traditional Distributed computing, one is traditional high-performance computing, both have their own advantages and disadvantages. The representative framework based on traditional distributed computing is TensorFlow, which focuses on the MPMD (Multiple Program-Multiple Data) parallel mode and can well support elasticity and fault tolerance. The user experience of distributed computing will be better, and programming is simpler. Users generally use Programming from a serial global perspective; the representative framework based on traditional high-performance computing is PyTorch, which focuses more on the SPMD (Single Program-Multiple Data) mode and pursues ultimate performance. Users need to directly face the physical cluster for programming and are responsible for segmenting the model themselves. And insert appropriate communication, the user requirements are higher. Automatic parallelism or adaptive distributed computing can be seen as a combination of the two. Of course, different architectures have different design priorities and need to be weighed according to actual needs. We hope that the flying paddle adaptive architecture can take into account the advantages of both fields.
The above is the detailed content of Flying Paddle is designed and practiced for automatic parallelism in heterogeneous scenarios.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
15 recommended open source free image annotation tools
Mar 28, 2024 pm 01:21 PM
Image annotation is the process of associating labels or descriptive information with images to give deeper meaning and explanation to the image content. This process is critical to machine learning, which helps train vision models to more accurately identify individual elements in images. By adding annotations to images, the computer can understand the semantics and context behind the images, thereby improving the ability to understand and analyze the image content. Image annotation has a wide range of applications, covering many fields, such as computer vision, natural language processing, and graph vision models. It has a wide range of applications, such as assisting vehicles in identifying obstacles on the road, and helping in the detection and diagnosis of diseases through medical image recognition. . This article mainly recommends some better open source and free image annotation tools. 1.Makesens
 This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
This article will take you to understand SHAP: model explanation for machine learning
Jun 01, 2024 am 10:58 AM
In the fields of machine learning and data science, model interpretability has always been a focus of researchers and practitioners. With the widespread application of complex models such as deep learning and ensemble methods, understanding the model's decision-making process has become particularly important. Explainable AI|XAI helps build trust and confidence in machine learning models by increasing the transparency of the model. Improving model transparency can be achieved through methods such as the widespread use of multiple complex models, as well as the decision-making processes used to explain the models. These methods include feature importance analysis, model prediction interval estimation, local interpretability algorithms, etc. Feature importance analysis can explain the decision-making process of a model by evaluating the degree of influence of the model on the input features. Model prediction interval estimate
 Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
Identify overfitting and underfitting through learning curves
Apr 29, 2024 pm 06:50 PM
This article will introduce how to effectively identify overfitting and underfitting in machine learning models through learning curves. Underfitting and overfitting 1. Overfitting If a model is overtrained on the data so that it learns noise from it, then the model is said to be overfitting. An overfitted model learns every example so perfectly that it will misclassify an unseen/new example. For an overfitted model, we will get a perfect/near-perfect training set score and a terrible validation set/test score. Slightly modified: "Cause of overfitting: Use a complex model to solve a simple problem and extract noise from the data. Because a small data set as a training set may not represent the correct representation of all data." 2. Underfitting Heru
 Transparent! An in-depth analysis of the principles of major machine learning models!
Apr 12, 2024 pm 05:55 PM
Transparent! An in-depth analysis of the principles of major machine learning models!
Apr 12, 2024 pm 05:55 PM
In layman’s terms, a machine learning model is a mathematical function that maps input data to a predicted output. More specifically, a machine learning model is a mathematical function that adjusts model parameters by learning from training data to minimize the error between the predicted output and the true label. There are many models in machine learning, such as logistic regression models, decision tree models, support vector machine models, etc. Each model has its applicable data types and problem types. At the same time, there are many commonalities between different models, or there is a hidden path for model evolution. Taking the connectionist perceptron as an example, by increasing the number of hidden layers of the perceptron, we can transform it into a deep neural network. If a kernel function is added to the perceptron, it can be converted into an SVM. this one
 The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
The evolution of artificial intelligence in space exploration and human settlement engineering
Apr 29, 2024 pm 03:25 PM
In the 1950s, artificial intelligence (AI) was born. That's when researchers discovered that machines could perform human-like tasks, such as thinking. Later, in the 1960s, the U.S. Department of Defense funded artificial intelligence and established laboratories for further development. Researchers are finding applications for artificial intelligence in many areas, such as space exploration and survival in extreme environments. Space exploration is the study of the universe, which covers the entire universe beyond the earth. Space is classified as an extreme environment because its conditions are different from those on Earth. To survive in space, many factors must be considered and precautions must be taken. Scientists and researchers believe that exploring space and understanding the current state of everything can help understand how the universe works and prepare for potential environmental crises
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Explainable AI: Explaining complex AI/ML models
Jun 03, 2024 pm 10:08 PM
Translator | Reviewed by Li Rui | Chonglou Artificial intelligence (AI) and machine learning (ML) models are becoming increasingly complex today, and the output produced by these models is a black box – unable to be explained to stakeholders. Explainable AI (XAI) aims to solve this problem by enabling stakeholders to understand how these models work, ensuring they understand how these models actually make decisions, and ensuring transparency in AI systems, Trust and accountability to address this issue. This article explores various explainable artificial intelligence (XAI) techniques to illustrate their underlying principles. Several reasons why explainable AI is crucial Trust and transparency: For AI systems to be widely accepted and trusted, users need to understand how decisions are made
