

How to use Python's json module and pickle module

json module
json is used for data exchange between different languages, such as between C and Python, etc., which can be cross-language. Pickle can only be used for data exchange between python and python.
Serialization and Deserialization
The process by which we change objects (variables) from memory to storable or transferable is called serialization. It is called pickling in Python and pickling in other languages. It is also called serialization, marshalling, flattening, etc., all with the same meaning. After serialization, the serialized content can be written to disk or transmitted to other machines through the network. In turn, rereading the variable content from the serialized object into memory is called deserialization, that is, unpickling.
If we want to transfer objects between different programming languages, we must serialize the object into a standard format, such as XML, but a better way is to serialize it into JSON, because JSON is expressed as a character Strings can be read by all languages and can be easily stored to disk or transmitted over the network. JSON is not only a standard format and faster than XML, but it can also be read directly in Web pages, which is very convenient.
The object represented by JSON is a standard JavaScript language object. The corresponding data types between JSON and Python are as follows:
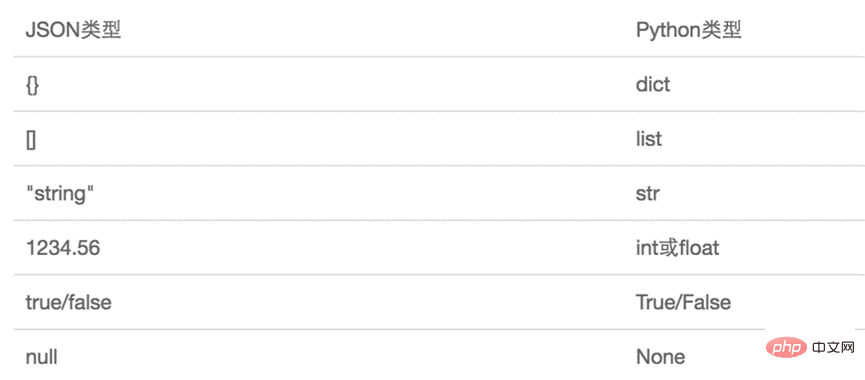
Write and read in the file Data-Dictionary
dic =' {‘string1':'hello'}' #写文件只能写入字符串 - 手动把字典变成字符串
f = open(‘hello', ‘w')
f.write(dic)f_read = open(‘hello', ‘r') data = f_read.read() #从文件中读出的都是字符串 data = eval(data) #提取出字符串中的字典 print(data[‘name'])
json implements the above functions - json can transmit data in any language
dic = {‘string1':'hello'}
data = json.dumps(dic)
print(data)
print(type(data)) #dumps()会把我们的变量变成一个json字符串
f = open(“new_hello”, “w”)
f.write(data)There is a difference between the json string and the string we manually add ’’ , which follows the json string specification, that is, the string is enclosed in double quotes.
dumps will turn any data type we pass in into a string enclosed in double quotes
# {‘string1':'hello'} ---> “{“string1”:”hello”}”
# 8 ---> “8”
# ‘hello' ---> ““hello”” – 被json包装后的数据内部只能有双引号
#[1, 2] ---> “[1, 2]”We convert the data into a json string when storing or transmitting, which can achieve any Language general
f_read = open(“new_hello”, “r”) data = json.loads(f_read.read()) #这个data直接就是字典类型 print(data) print(type(data))
Methods in json module
json.dumps() # 把数据包装成json字符串 – 序列化 json.loads() # 从json字符串中提取出原来的数据 – 反序列化
We wrap a list l = [1, 2, 3] into a json string in python and store or send it out, if When we use json parsing in C language, we will get the corresponding data structure in C language, and the extracted data is an array buf[3] = {1, 2, 3}.
This does not mean that dumps and loads must be used together. As long as the json string conforms to the json specification, loads can be used to process and extract the data structure. It does not matter whether dumps are used or not.
json.dump(data, f) #转换成json字符串并写入文件 #相当于 data = json.dumps(dic) + f.write(data) data = json.load(f) #先读取文件,再提取出数据 #相当于data = json.loads(f_read.read())
Example:
#----------------------------序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()#-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
Note:
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
dct='{"1":"111"}'
print(json.loads(dct))No matter how the data is created, as long as it meets the json format, it can be json.loads out and does not necessarily have to be dumps Data can be loaded.
pickle module
The problem with Pickle is the same as the serialization problem specific to all other programming languages, which is that it can only be used with Python, and it is possible that different versions of Python are incompatible with each other, so, You can only use Pickle to save unimportant data, and it doesn't matter if you can't successfully deserialize it.
##----------------------------序列化
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f)
f.close()#-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
The usage of pickle and json are the same. The scientific names of both are called serialization, but the result of json serialization is a string, and the result of pickle serialization is bytes. That is to say, the form is different, but the content is the same. However, what is serialized by pickle is bytes, that is, the data to be written to the file is bytes, so when open opens the file, it must be opened in the form of wb binary. The content written to the file by pickle is unreadable (messy characters, but the computer can recognize it), but the data written by json is readable. pickle supports more data types, and pickle can serialize functions and classes. Although json does not support these two serializations, json is still used in most scenarios.
The above is the detailed content of How to use Python's json module and pickle module. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
