

What is the way to implement Python virtual machine bytes?

数据结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
上面的数据结构用图示如下所示:
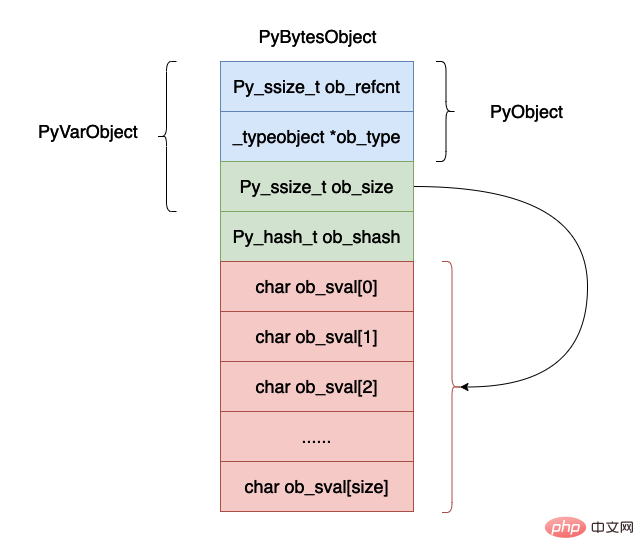
现在我们来解释一下上面的数据结构各个字段的含义:
ob_refcnt,这个还是对象的引用计数的个数,主要是在垃圾回收的时候有用。
ob_type,这个是对象的数据类型。
ob_size,表示这个对象当中字节的个数。
ob_shash,对象的哈希值,如果还没有计算,哈希值为 -1 。
ob_sval,一个数据存储一个字节的数据,需要注意的是 ob_sval[size] 一定等于 '\0' ,表示字符串的结尾。
可能你会有疑问上面的结构体当中并没有后面的那么多字节啊,数组只有一个字节的数据啊,这是因为在 cpython 的实现当中除了申请 PyBytesObject 大的小内存空间之外,还会在这个基础之上申请连续的额外的内存空间用于保存数据,在后续的源码分析当中可以看到这一点。
下面我们举几个例子来说明一下上面的布局:
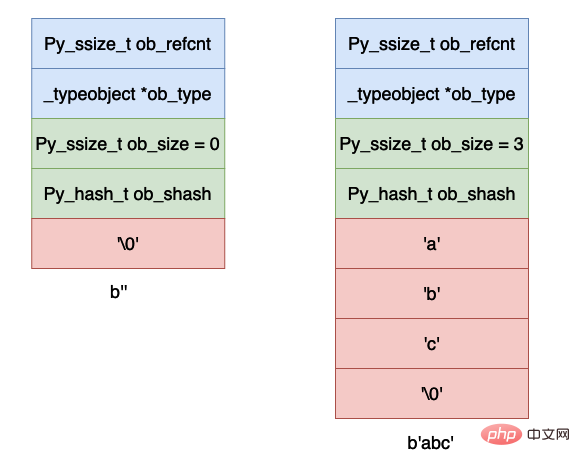
上面是空和字符串 abc 的字节表示。
创建字节对象
下面是在 cpython 当中通过字节数创建 PyBytesObject 对象的函数。下面的函数的主要功能是创建一个能够存储 size 个字节大小的数据的 PyBytesObject 对象,下面的函数最重要的一个步骤就是申请内存空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
我们可以使用一个写例子来看一下实际的 PyBytesObject 内存空间的大小。
1 2 3 4 5 |
|
上面的 44 = 32 + 11 + 1 。
其中 32 是 PyBytesObject 4 个字段所占用的内存空间,ob_refcnt、ob_type、ob_size和 ob_shash 各占 8 个字节。11 是表示字符串 "hello world" 占用 11 个字节,最后一个字节是 '\0' 。
查看字节长度
这个函数主要是返回 PyBytesObject 对象的字节长度,也就是直接返回 ob_size 的值。
1 2 3 4 5 6 |
|
字节拼接
在 python 当中执行下面的代码就会执行字节拼接函数:
1 |
|
下方就是具体的执行字节拼接的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
1 2 |
|
我们修改一个这个函数,在其中加入一条打印语句,然后重新编译 python 执行结果如下所示:

1 2 3 4 5 6 7 |
|
在上面的拼接函数当中会拷贝原来的两个字节对象,因此需要谨慎使用,一旦发生非常多的拷贝的话是非常耗费内存的。因此需要警惕使用循环内的内存拼接。比如对于 [b"a", b"b", b"c"] 来说,如果使用循环拼接的话,那么会将 b"a" 拷贝两次。
1 2 3 4 5 6 7 |
|
因为 b"a", b"b" 在拼接的时候会将他们分别拷贝一次,在进行 b"ab",b"c" 拼接的时候又会将 ab 和 c 拷贝一次,那么具体的拷贝情况如下所示:
"a" 拷贝了一次。
"b" 拷贝了一次。
"ab" 拷贝了一次。
"c" 拷贝了一次。
但是实际上我们的需求是只需要对 [b"a", b"b", b"c"] 当中的数据各拷贝一次,如果我们要实现这一点可以使用 b"".join([b"a", b"b", b"c"]),直接将 [b"a", b"b", b"c"] 作为参数传递,然后各自只拷贝一次,具体的实现代码如下所示,在这个例子当中 sep 就是空串 b"",iterable 就是 [b"a", b"b", b"c"] 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
|
单字节字符
在 cpython 的内部实现当中给单字节的字符做了一个小的缓冲池:
1 |
|
当创建的 bytes 只有一个字符的时候就可以检查是否 characters 当中已经存在了,如果存在就直接返回这个已经创建好的 PyBytesObject 对象,否则再进行创建。新创建的 PyBytesObject 对象如果长度等于 1 的话也会被加入到这个数组当中。下面是 PyBytesObject 的另外一个创建函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
我们可以使用下面的代码进行验证:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
从上面的代码可以知道,确实当我们创建的 bytes 的长度等于 1 的时候对象确实是同一个对象。
The above is the detailed content of What is the way to implement Python virtual machine bytes?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1655
1655
 14
1414
52
1307
25
1253
29
1227
24
14
1414
52
1307
25
1253
29
1227
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
