

Analyze examples of blocking queues in Java

1. What is a blocking queue
A blocking queue is a special queue. Like ordinary queues in the data structure, it also follows first-in, first-out At the same time, the blocking queue is a data structure that can ensure thread safety and has the following two characteristics: when the queue is full, continuing to insert elements into the queue will block the queue until other threads take it from the queue. Remove elements; when the queue is empty, continuing to dequeue will also block the queue until other threads insert elements into the queue.
Supplement: Thread blocking means that the code will not be executed at this time, that is, The operating system will not schedule this thread to the CPU for execution at this time
2. Use the blocking queue code
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.BlockingDeque;
public class Test {
public static void main(String[] args) throws InterruptedException {
//不能直接newBlockingDeque,因为它是一个接口,要向上转型
//LinkedBlockingDeque内部是基于链表方式来实现的
BlockingDeque<String> queue=new LinkedBlockingDeque<>(10);//此处可以指定一个具体的数字,这里的的10代表队列的最大容量
queue.put("hello");
String elem=queue.take();
System.out.println(elem);
elem=queue.take();
System.out.println(elem);
}
}Note: The put method has a blocking function, but the offer does not. Therefore, the put method is generally used (the reason why the offer method can be used is that BlockingDeque inherits Queue)

to print the results As shown above, after hello is printed, the queue is empty and the code will not continue to execute until elem=queue.take();. At this time, the thread enters the blocking waiting state and nothing happens. It will not print until other threads put new elements into the queue
3. Producer-consumer model
The producer-consumer model is developed in server development and back-end development It is a relatively common programming method and is generally used for decoupling and peak-shaving and valley-filling.
High coupling: the relationship between the two code modules is relatively high
High cohesion: the elements within a code module are closely combined with each other
Therefore, we generally pursue high cohesion and low coupling. This will speed up execution efficiency, and the producer-consumer model can be used to decouple
(1) Application 1: Decoupling
Let’s take the situation in real life as an example. Here are two Server: A server and B server. When A server transmits data to B, if it is transmitted directly, then either A will push data to B, or B will pull data from A. Both require A and B to interact directly, so There is a dependency relationship between A and B (the degree of coupling between A and B is relatively high). If the server needs to be expanded in the future, such as adding a C server to let A transmit data to C, then the changes will be more complicated and efficiency will be reduced. At this time, we can add a queue. This queue is a blocking queue. If A writes data to the queue and B takes it from it, then the queue is equivalent to the transfer station (or trading place), and A is equivalent to the producer (providing data). B is equivalent to the consumer (receiving data). At this time, a producer-consumer model is formed, which will make the code less coupled, more convenient to maintain, and more efficient in execution.
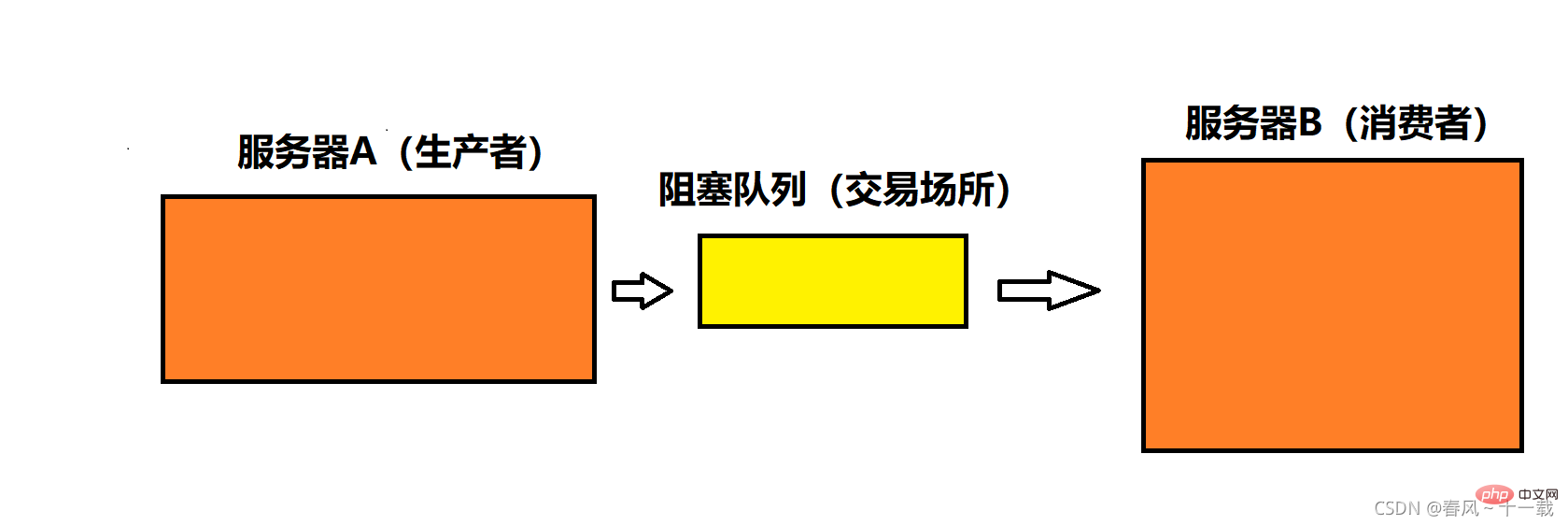
In the computer, the producer acts as one group of threads, and the consumer acts as another group of threads, and the trading venue can use blocking queues
(2) Application 2: Peak shaving and valley filling

In real life
The dam is a very important part of the river. If there is no dam , let’s just imagine the result: when the flood season comes, when there is a lot of water in the upper reaches, a large amount of water will pour into the lower reaches, causing floods and flooding the crops; while in the dry season, there will be very little water in the lower reaches, which may cause droughts. If there is a dam, the dam will store excess water in the dam during the flood season, close the gate to store water, and allow the upstream water to flow downstream at a certain rate to avoid a sudden wave of heavy rain from flooding the downstream, so that the downstream will not be flooded. flood. During drought periods, the dam releases previously stored water and allows the water to flow downstream at a certain rate to prevent the downstream from being too short of water. This can avoid both flooding during the flood season and drought during the dry period.
Peak: equivalent to the flood season
Valley: equivalent to the dry season
In computers
This situation is also very typical in computers, especially in server development, the gateway usually The request is forwarded to business servers, such as some product servers, user servers, merchant servers (which store merchant information), and live broadcast servers. However, because the number of requests from the Internet is uncontrollable, it is equivalent to upstream water. If a large wave of requests suddenly come, even if the gateway can handle it, many subsequent servers will collapse after receiving many requests (processing one The request involves a series of database operations, because the efficiency of database-related operations is relatively low. If there are too many requests, it cannot be processed, so it will crash)
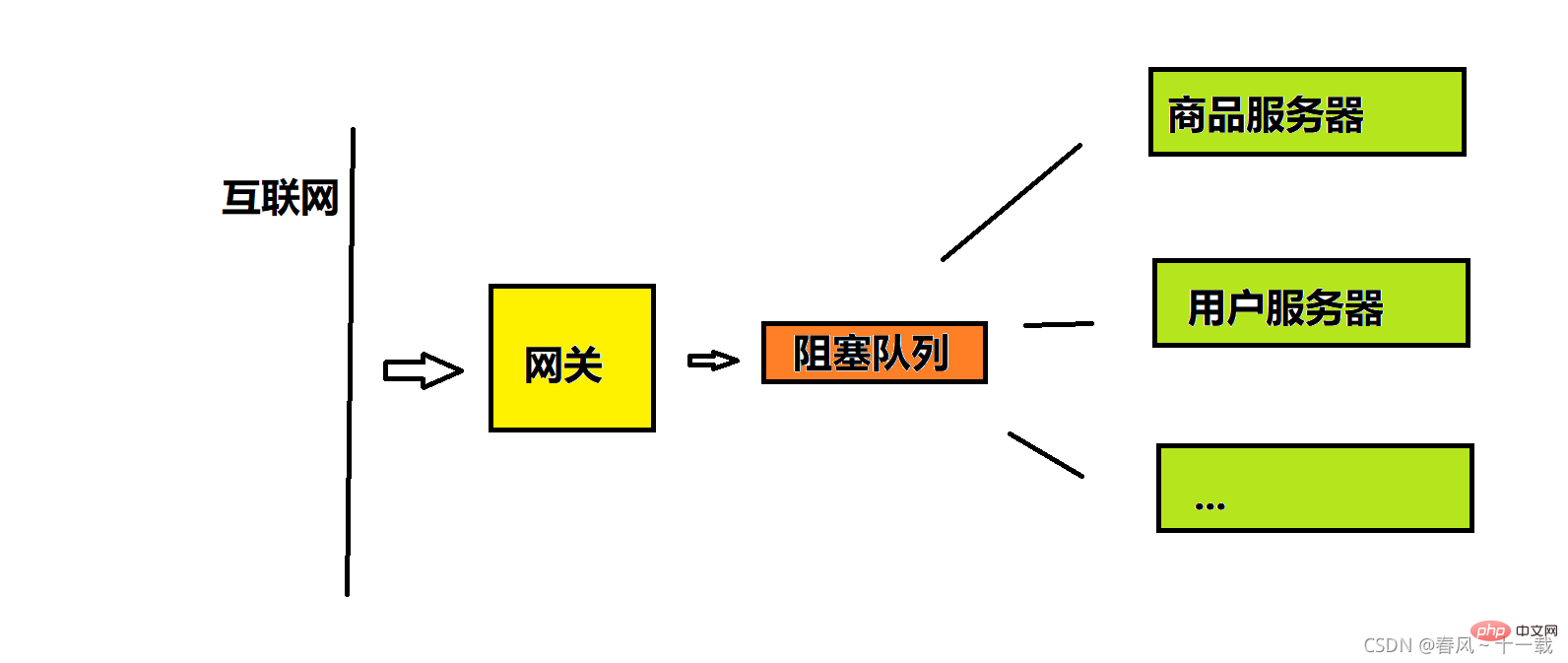
所以实际情况中网关和业务服务器之间往往用一个队列来缓冲,这个队列就是阻塞队列(交易场所),用这个队列来实现生产者(网关)消费者(业务服务器)模型,把请求缓存到队列中,后面的消费者(业务服务器)按照自己固定的速率去读请求。这样当请求很多时,虽然队列服务器可能会稍微受到一定压力,但能保证业务服务器的安全。
(3)相关代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class TestDemo {
public static void main(String[] args) {
// 使用一个 BlockingQueue 作为交易场所
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
// 此线程作为消费者
Thread customer = new Thread() {
@Override
public void run() {
while (true) {
// 取队首元素
try {
Integer value = queue.take();
System.out.println("消费元素: " + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
customer.start();
// 此线程作为生产者
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 10000; i++) {
System.out.println("生产了元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
try {
customer.join();
producer.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}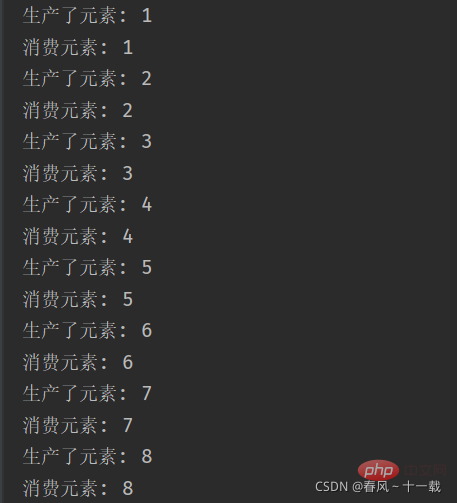
打印如上(此代码是让生产者通过sleep每过1秒生产一个元素,而消费者不使用sleep,所以每当生产一个元素时,消费者都会立马消费一个元素)
4.阻塞队列和生产者消费者模型功能的实现
在学会如何使用BlockingQueue后,那么如何自己去实现一个呢?
主要思路:
1.利用数组
2.head代表队头,tail代表队尾
3.head和tail重合后到底是空的还是满的判断方法:专门定义一个size记录当前队列元素个数,入队列时size加1出队列时size减1,当size为0表示空,为数组最大长度就是满的(也可以浪费一个数组空间用head和tail重合表示空,用tail+1和head重合表示满,但此方法较为麻烦,上一个方法较为直观,因此我们使用上一个方法)
public class Test2 {
static class BlockingQueue {
private int[] items = new int[1000]; // 此处的1000相当于队列的最大容量, 此处暂时不考虑扩容的问题.
private int head = 0;//定义队头
private int tail = 0;//定义队尾
private int size = 0;//数组大小
private Object locker = new Object();
// put 用来入队列
public void put(int item) throws InterruptedException {
synchronized (locker) {
while (size == items.length) {
// 队列已经满了,阻塞队列开始阻塞
locker.wait();
}
items[tail] = item;
tail++;
// 如果到达末尾, 就回到起始位置.
if (tail >= items.length) {
tail = 0;
}
size++;
locker.notify();
}
}
// take 用来出队列
public int take() throws InterruptedException {
int ret = 0;
synchronized (locker) {
while (size == 0) {
// 对于阻塞队列来说, 如果队列为空, 再尝试取元素, 就要阻塞
locker.wait();
}
ret = items[head];
head++;
if (head >= items.length) {
head = 0;
}
size--;
// 此处的notify 用来唤醒 put 中的 wait
locker.notify();
}
return ret;
}
}
public static void main(String[] args) throws InterruptedException {
BlockingQueue queue = new BlockingQueue();
// 消费者线程
Thread consumer = new Thread() {
@Override
public void run() {
while (true) {
try {
int elem = queue.take();
System.out.println("消费元素: " + elem);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
consumer.start();
// 生产者线程
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i < 10000; i++) {
System.out.println("生产元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
consumer.join();
producer.join();
}
}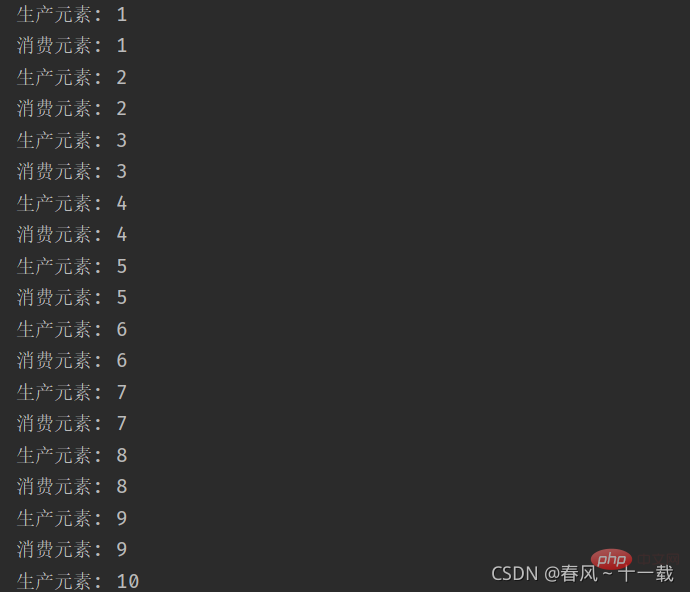
运行结果如上。
注意:
1.wait和notify的正确使用
2.put和take都会产生阻塞情况,但阻塞条件是对立的,wait不会同时触发(put唤醒take阻塞,take唤醒put阻塞)
The above is the detailed content of Analyze examples of blocking queues in Java. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
