

First, let’s introduce the business background of Alibaba Health and the analysis of the current situation.
Interpretable recommendation, for example, as shown in the figure below on Dangdang.com "Recommendations based on the products you browse" (telling users the reasons for recommendations) and Taobao's "1000 Home Control Collection" and "2000 Digital Experts Add Purchases" are all explainable recommendations, which explain the reasons for recommended products by providing user information.

The explainable recommendation in the picture on the left has a relatively simple implementation idea: the recommendation mainly includes recall and sorting There are two main modules, and recall often involves multi-channel recall. User behavior recall is also a common recall method. The products that have passed through the sorting module can be judged. If the products come from the user behavior recall pool, corresponding recommendation comments can be added after the recommended products. However, this method often has low accuracy and does not provide users with much effective information.
In comparison, in the example on the right, the corresponding explanatory text can provide the user with more information, such as product category information, etc., but this method often requires more manual intervention, from features to text. The output link is manually processed.
As for Ali Health, due to the particularity of the industry, there may be more restrictions than in other scenarios. Relevant regulations stipulate that text information such as "hot sales, ranking, and recommendation" are not allowed to appear in advertisements for "three products and one device" (drugs, health foods, formula foods for special medical purposes, and medical devices). Therefore, Alibaba Health needs to recommend products based on Alibaba Health's business on the premise of complying with the above regulations.
Ali Health currently has two types of stores: Ali Health self-operated stores and Ali Health industry stores. Among them, self-operated stores mainly include large pharmacies, overseas stores and pharmaceutical flagship stores, while Alibaba's health industry stores mainly involve flagship stores of various categories and private stores.
#In terms of products, Alibaba Health mainly covers three major categories of products: conventional commodities, OTC commodities, and prescription drugs. Regular products are defined as products that are not medicines. For recommendations of regular products, more information can be displayed, such as category sales top, more than n people have collected/purchased, etc. Recommendations for pharmaceutical products such as OTC and prescription drugs are subject to corresponding regulations, and recommendations need to be more integrated with user concerns, such as information on functional indications, medication cycles, contraindications, and other information.
The information mentioned above that can be used for drug recommendation text mainly comes from the following major sources:
The second part mainly introduces the characteristics of products How to extract and encode .
The following takes Huoxiang Zhengqi water as an example to show how to extract the characteristics from the above data Source to extract key features:

In order to increase the recall of products, merchants often add more keywords to the title. Therefore, keywords can be extracted through the merchant's own title description.
OCR technology can be borrowed based on the product More comprehensive product information such as the product's functions, main selling points, and core selling points can be extracted from the detailed image.
By user based on a certain function The emotional score can be used to weight and reduce the weight of the corresponding keywords of the product. For example, for the Huoxiang Zhengqi Water that "prevents heatstroke", the corresponding label can be weighted based on the emotional score of "preventing heatstroke" in user comments.
Through the above multiple data sources , can extract keywords from the information and build a keyword library. Since there are many duplicates and synonyms in the extracted keywords, synonyms need to be merged and combined with manual verification to generate a standard thesaurus. Finally, a single product-tag list relationship can be formed, which can be used for subsequent coding and use in the model.
The following describes how to encode features. Feature encoding is mainly based on word2vec method for word embedding.
The real historical purchase data can be divided into the following three categories:
(1) Common Browsing product pairs: Users who click one after another within a period of time (30 minutes) are defined as co-browsed data.
(2) Common purchase of goods: Common purchase can be defined as the same main order in a broad sense Sub-orders can be considered a pair of jointly purchased goods; however, considering the actual user ordering habits, define the product data of orders placed by the same user within a certain period of time (10 minutes).
(3) Product pair purchased after browsing: The same user purchased product B after clicking A, and A and B are mutually exclusive Browse and buy data.
#Through the analysis of historical data, it was found that the purchase data after browsing has a high degree of similarity between products: often the core functions of drugs are similar, with only slight differences. Define it as a pair of similar products, which is a positive sample.
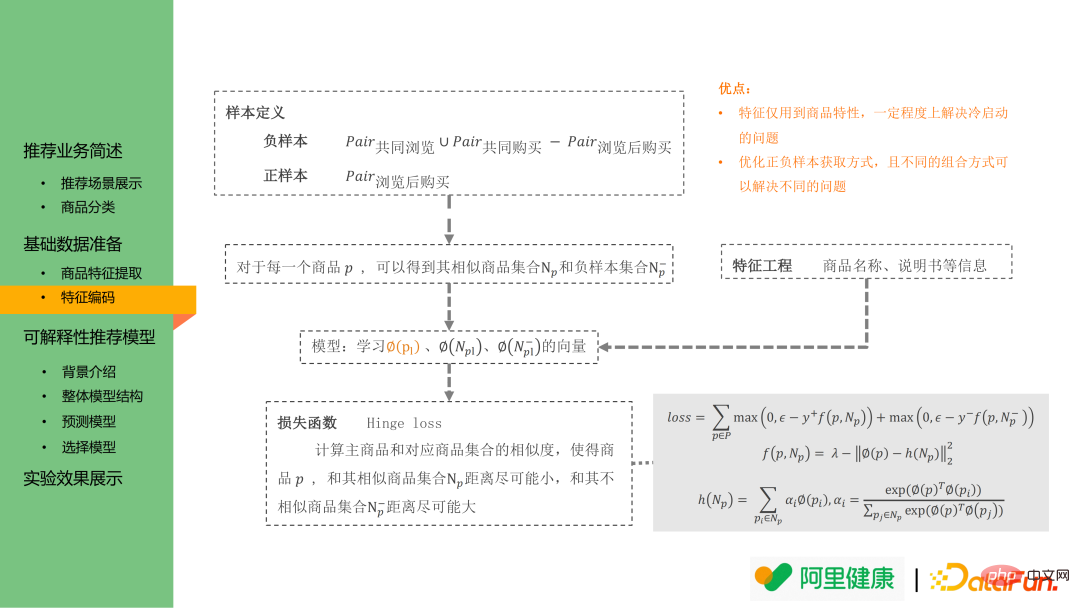
The feature encoding model is still based on the idea of word2vec: mainly hoping that embeddings between similar products/tags will be closer . Therefore, the positive sample in word embedding is defined as the above-mentioned product pairs purchased after browsing; the negative sample is the union of co-browsed product pairs and co-purchased product pairs minus the data of product pairs purchased after browsing.
Based on the above definition of positive and negative sample pairs, using hinge loss, the embedding of each product can be learned for the i2i recall stage, and the embedding of tags/keywords can also be learned in this scenario for subsequent use. input to the model.
The above method has two advantages:
(1) Features only use product characteristics, which can solve the cold problem to a certain extent. Startup issue: For newly launched products, you can still get the corresponding tags through their titles, product details, and other information.
(2) The definition of positive and negative samples can be used in different recommendation scenarios: if the positive samples are defined as pairs of jointly purchased products, the trained product embedding can be used in the "collocation purchase recommendation" scenario.
The industry is now relatively mature The interpretable types mainly include built-in interpretability (model-intrinsic) and model-independent interpretability (model-agnostic).
It has built-in interpretability models, such as the common XGBoost, etc. However, although XGBoost is an end-to-end model, its feature importance is based on the overall data set, which does not meet the personalized recommendation of "thousands of people and thousands of faces" Require.
Model-independent interpretability mainly refers to reconstructing the logical simulation model and explaining the model, such as SHAP, which can analyze a single case and determine the reason why the predicted value is different from the actual value. However, SHAP is complex and time-consuming, and cannot meet online performance requirements after performance modification.
Therefore, it is necessary to build an end-to-end model that can output the feature importance of each sample.
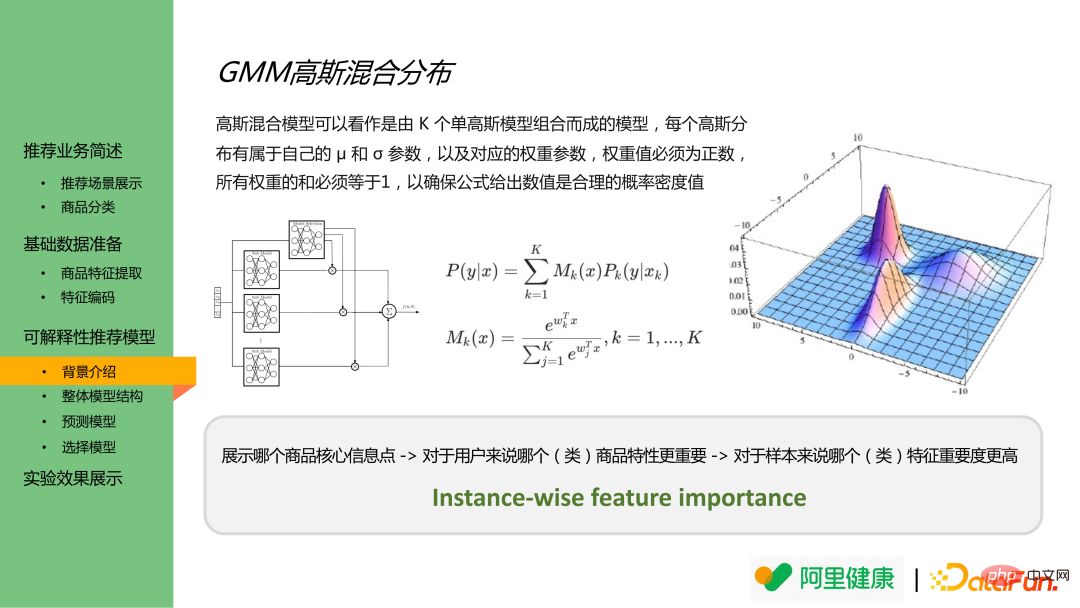
The Gaussian mixture distribution is a combination of multiple Gaussian distributions, which can output the result value of a certain distribution and the probability that each sample result belongs to a certain distribution. Therefore, an analogy can be made to understand the classified features as data with different distributions, and model the prediction results of the corresponding features and the importance of the prediction in the actual results.
The following picture is the overall model structure diagram. The left picture is the selected model, which can be used to display the feature importance. The right picture is The prediction model corresponding to the feature.
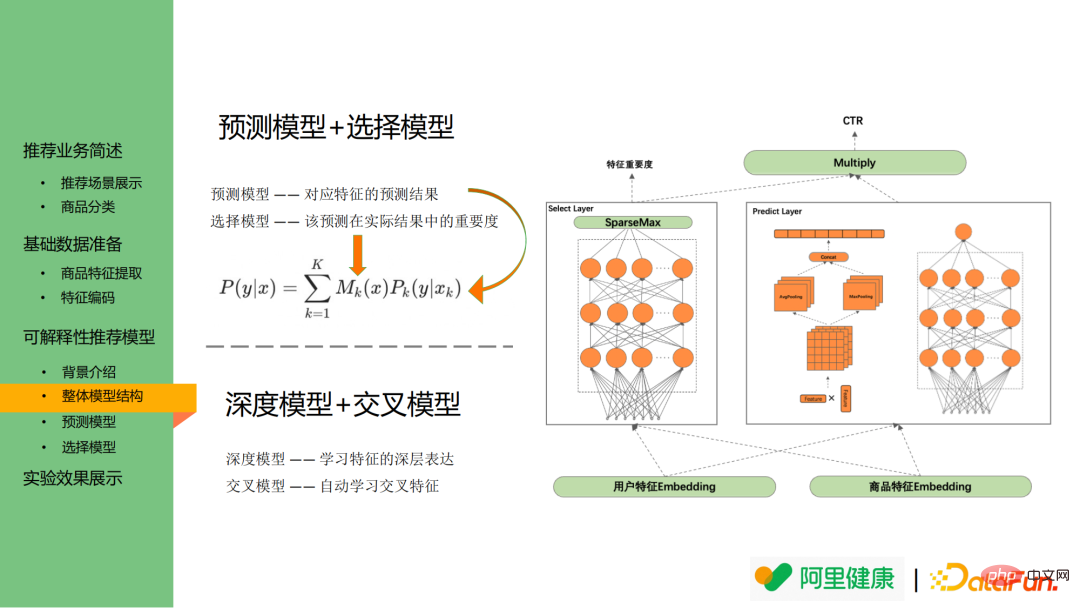
Specifically, the prediction model is used to predict the probability of corresponding feature prediction/click, while the selection model is used to explain which feature distributions are more important and can be used as explanations Display of sexual texts.
The following figure shows the results of the prediction model. The prediction model mainly draws on the ideas of DeepFM and includes a deep model and a cross model. Deep models are mainly used to learn deep representations of features, while cross models are used to learn cross features.
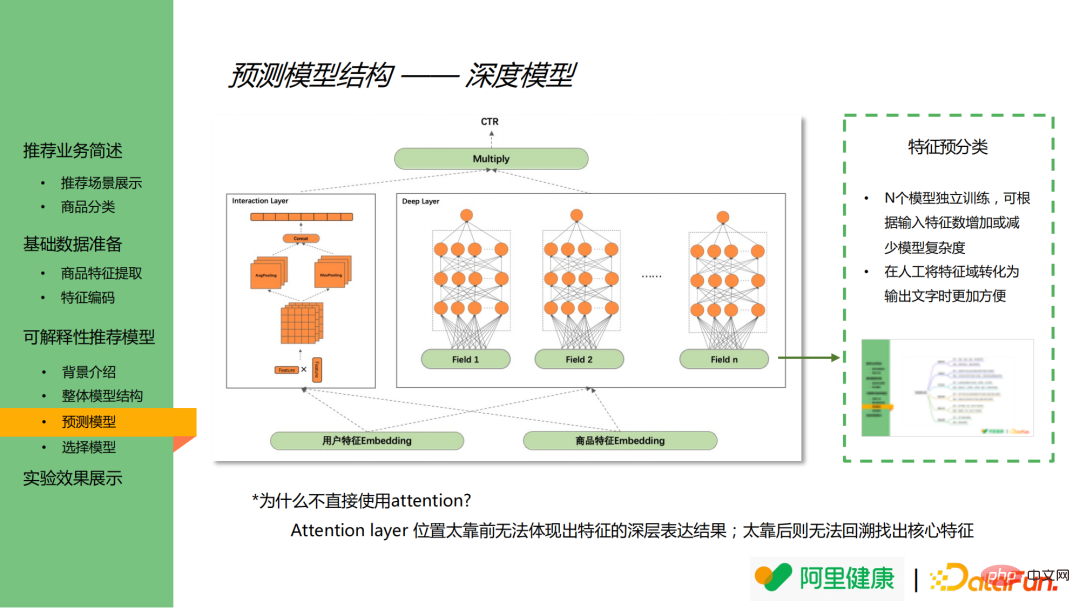
In the deep model, the features are first grouped in advance (assuming there are N groups in total), such as price, category and other related features are merged into price, category categories ( field field in the figure), conduct separate model training for each set of features, and obtain model results based on this set of features.
Merging and grouping models in advance has the following two advantages:
(1) Through independent training of N models, the complexity of the model can be changed by increasing or decreasing the input features, This affects online performance.
(2) Merging and grouping features can significantly reduce feature magnitude, making it more convenient to manually convert feature domains into text.
It is worth mentioning that the attention layer can theoretically be used to analyze feature importance, but the main reasons for not introducing attention in this model are as follows:
(1) If attention is used If the layer is placed too far forward, it will not be able to reflect the results of the deep expression of features;
(2) If the attention layer is placed too far back, it will be impossible to backtrack and find the core features.
As for the prediction model:
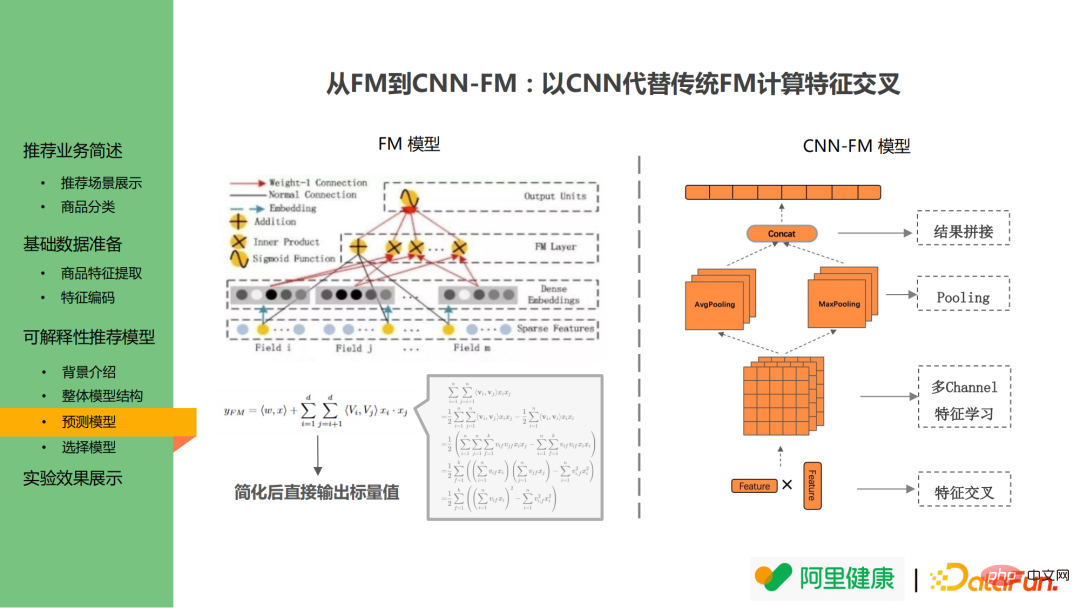
The cross layer does not follow the FM model but uses CNN to replace the FM structure in DeepFM. The FM model learns the pairwise cross results of features and directly calculates the pairwise cross results through mathematical formulas to avoid dimension explosion during calculation. However, it makes it impossible to trace back the feature importance. Therefore, CNN is introduced in the cross model to replace the original structure: N The features are multiplied to achieve feature intersection, and then the corresponding operations of CNN are performed. This allows the feature values to be traced back after pooling, concat and other operations after input.
In addition to the above advantages, this method also has another advantage: although the current version only converts a single feature into a single description text, it is still hoped to achieve the conversion of multi-feature interaction in the future. For example, if a user is accustomed to buying low-price products of 100 yuan, but if a product with an original price of 50,000 yuan is discounted to 500 yuan and the user purchases the product, the model may therefore define him as a high-spending user. However, in practice, users may place orders due to the dual factors of high-end brands and high discounts, so combination logic needs to be considered. For the CNN-FM model, the feature map can be directly used to output the feature combination in the later stage.
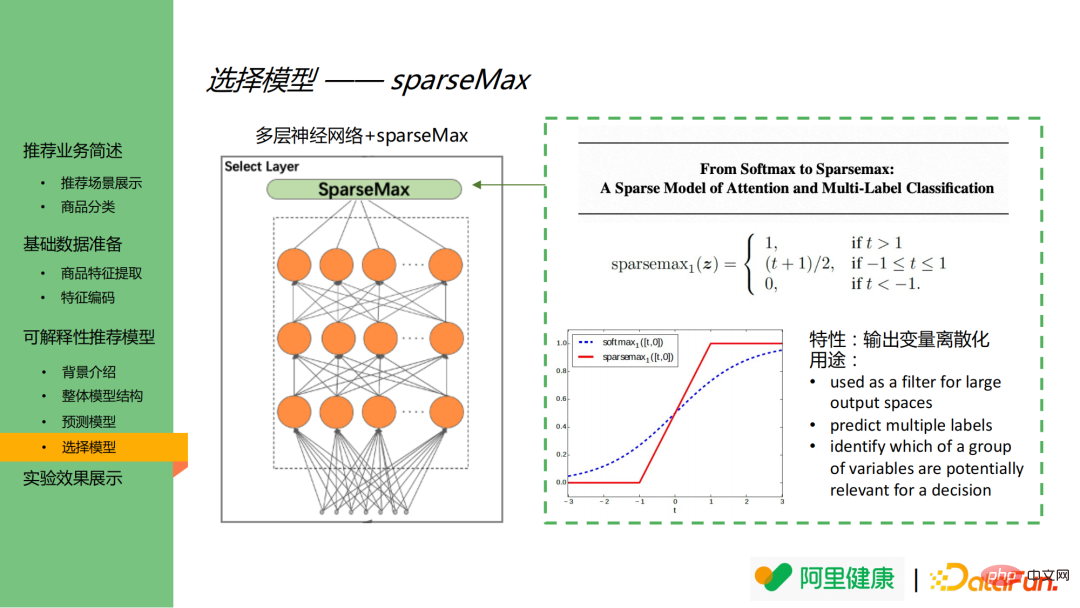
The selection model consists of MLP and sparseMax. It is worth mentioning that the activation function in the selection model is sparsemax instead of the more common softmax. On the right side of the image are the function definition of sparsemax and the function comparison chart of softmax and sparsemax.
As can be seen from the picture on the lower right, softmax will still assign smaller values to output nodes with lower importance. In this scenario, it will cause the feature dimension to explode, and it is easy to cause important features to become unimportant. The output between features is indistinguishable. SparseMax can discretize the output and ultimately output only the more important features.
Online effect The data mainly comes from the exposure-click data on the homepage of large pharmacies. In order to avoid over-fitting, some other scene exposure-click data are also introduced, and the data ratio is 4:1.
In the offline scenario, the AUC of this model is 0.74.
Since the online scene already has a CTR model, consider that the new version of the algorithm will not only replace the model, but also display the corresponding The explanatory text does not control variables, so this experiment did not directly use AB test. Instead, the text of the recommendation reasons will be displayed if and only if the predicted values of the online CTR model and the new version of the algorithm are higher than a specific threshold. After going online, the PCTR of the new algorithm increased by 9.13%, and the UCTR increased by 3.4%.
#A1: When synonyms are merged, the model will be used to learn text standards and provide a basic vocabulary library. But in fact, manual verification takes a larger proportion. Because the health/pharmaceutical business scenario has higher requirements for algorithm accuracy, deviations in individual words may cause large deviations in the actual meaning. Overall, the proportion of manual verification will be greater than that of algorithms.
A2: Yes. There are many other models that can do explainable recommendations. Because the sharer is generally familiar with GMM, the above model was selected.
A3: Assuming that there are N sets of feature groups, both the prediction model and the selection model will generate 1*N-dimensional vectors, and finally the results of the prediction model and the selection model will be compared. Multiply (multiple) to achieve linkage.
A#4: There is currently no suitable machine learning model for text generation, and manual methods are mainly used. If price is the core feature that users care about, they will choose to analyze historical data and recommend products with high cost performance. But for now, it's mainly manual work. It is hoped that there will be a suitable model for text generation in the future, but considering the particularity of the business scenario, the text generated by the model still needs to be manually verified.
A5: For the selection of GMM neutron distribution, the distribution is mainly learned through Mk in GMM, and filtered based on the high and low values of Mk.
A6: Meet the standards for attribute words, such as diseases, functions, taboos, etc. in product descriptions.
A7: Yes, the current actual usage is slot filling.
That’s it for today’s sharing, thank you all.
The above is the detailed content of Application of Alibaba's explainable recommendation algorithm. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



