

DDD practice for phone robot team

Introduction
DDD is a set of methodology and a set of ideas. A wide variety of metamodels and nominal concepts. Their essence is "one" of the solutions corresponding to the guiding ideology, and beginners are easily trapped by the appearance. You should always keep a clear understanding that "all DDD meta-models are created to solve certain types of problems in actual development." When coming into contact with various meta-models, you should conduct verification based on the problems faced by your own business. This will help avoid being trapped by conceptual representations and return to the essence of solving problems.
Background
The data architecture team started developing the phone robot driven by business needs in 2018, and it has been nearly five years since then. At present, 100 different types of robots have been built under this platform to provide outbound call capabilities for the company's dealers, used cars, OEMs, finance and other BU businesses, with hundreds of thousands of outbound calls per day. The phone robot project has begun to take shape, but it has also encountered many challenges in the process. In order to cope with these challenges, our team finally adopted DDD thinking for reconstruction and development.
In the process of applying DDD, the data architecture team implemented some of its own development specifications. Here I would like to share some experiences and ideas with you, hoping that they can serve as a starting point. Let me explain here. Many multivariate models are not discussed in this article, and no specific cases are given. First, consider the issue of length. The second is to understand the DDD idea and implement it by combining the respective businesses. It is not meaningful to give examples in my business. In addition, such cases are easy to find. At the same time, I feel that it would be more valuable for everyone to share the problems and solutions encountered by our team, the implementation process and the development specifications we have formed. Students who are interested in DDD, want to know more or have questions about this article are welcome to contact me for discussion.
Below, I will share from these parts: challenges encountered in the robot project, why DDD is DDD, steps to implement DDD, improvements to the team, conflicts encountered from theory to practice, and the future Improvements and summaries in DDD applications.
1. Challenges encountered
Challenge 1: The business logic is highly complex. With the access of various services, new logic is constantly added to cope with specific services in different scenarios.
For example: Intention recognition logic in the process.
Intent recognition requires the recognition of multiple models of AI. The intentions recognized by multiple models may conflict, and it is necessary to make trade-offs between conflicting intent configuration rules. At the same time, for some cold start or emergency optimization scenarios, it is necessary to support intent identification by configuring rules to take effect in real time. And matching word slots need to be supported in the intent recognition of rules. There are many types of word slots. Global word slots with scenarios and word slots with processes are distinguished in terms of priority. From the source of data identification, it can be divided into those identified by AI, those matched by dictionary rules, or those passed in by the business party. After the business has been carried out for a period of time, different attributes are added to different types of slots. For example, the slots for car series include product, business scope, non-operation, etc.;
Challenge 2: The code architecture structure is not clear. As business requirements are added, the code size increases. Coupled with the complexity of the logic and the different codes of team developers, various logical boundaries gradually become confusing.
For example: Our usual development method is to disassemble it according to functional modules, and the business process is connected in series to coordinate each module to jointly complete the business requirements. However, when dealing with the complex logic of this type of business, this solution design has great drawbacks, and module boundaries are easily penetrated.
The relationships among the modules call each other. The original isolation design of the modules was actually completely broken during the implementation process. The originally ideal vertically split modules become a mesh-like structure.
The attributes or methods developed by the module manager in the middle are dependent on other external modules, causing the functions to diverge. This leads to increased risks when requirements change later, or it may be found that methods that can be changed at will cannot be changed, and additional logic code has to be added to implement it. This makes already complex code even more complex.
The dismantling of business requirements is unreasonable. The required functions are developed nearby when implemented. The disassembly is not strictly in accordance with the modules, and there is a lack of unified thinking as guidance.
Challenge 3: There are many demands for products, and it is difficult to distinguish whether they have real value.
Challenge 4: Logic changes rapidly, and many demands require code logic redesign.
Challenge 5: There are many businesses, inconsistent descriptions of each business, and high communication costs.
Vertical boundaries are broken, code complexity increases, and business processes are frequently adjusted. These multiple dimensions are superimposed on each other, making development and maintenance exponentially more difficult. The stability of the first-level application system of telephone robot is difficult to guarantee. Even if the technical classmates are all senior engineers, they have designed according to the microservice ideas they can understand and disassembled the project according to modules. Even if the code logic has quoted many design patterns to build and expand, even if it has been connected to various parts of the company, Platform quality tools, written a lot of unit tests. However, when the new requirements of the project were iterated, many "surprises" still appeared, causing headaches for the entire team.
2.Why DDD
Why DDD? There are so many technology stacks and so many ideas every day, why is DDD used to deal with them? First of all, DDD modifies "how to deal with the core complexity of software" very well, which makes many people want to find out. So let’s take a look at how DDD solves the challenges encountered in the project.
First, let’s take a look at DDD’s classification of complexity and figure out whether the complexity that DDD has to deal with is a challenge I face. In DDD related materials, the causes of complexity are explored and analyzed from the two dimensions of understanding ability and prediction ability.
Understanding ability (that is, the software system is complex and difficult for developers to understand):
First scale: The first factor that affects understanding ability. There are hundreds of millions of lines of code, and the relationship between each demand point affects each other. Modifying one area will affect the whole body.
Second structure: An unreasonable or even chaotic structure makes it difficult for developers to maintain functions.
Predictive ability (that is, the development of the business is difficult to predict):
When requirements change, it is difficult to predict the direction of software implementation, and problems of over-design and under-design will occur. Over-design, many interfaces were reserved, and many patterns were constructed to increase the implementation complexity of the code, but later it was found that they were not used. The design is insufficient, and the realization of requirements does not take into account later development. When changes come, the existing design needs to be overturned and redeveloped. Products complain about poor design capabilities.
DDD’s causes of complexity are summarized as: scale, structure, and change; scale and structure create obstacles to understanding, changes create obstacles to prediction, and the two add up to form a complexity problem.
Secondly, DDD is not just a theory of the code design phase, but also includes full-process design guidance from requirements analysis, architecture mapping, modeling and implementation.
In the demand analysis stage, we can accurately understand the business value in advance through relevant guiding ideology and capture the direction of future changes. In the architecture mapping stage, the guiding ideology of the process from requirements to architecture is given, and the design weight and specifications are added. Through sub-domain splitting, system layering and bounded context business classification, guidance specifications are provided to ensure the clarity of the system architecture and reduce system complexity. In the modeling and implementation stage, domain-driven design-related meta-models are given to make the functional division of each part clear and respond quickly to business needs and future functional changes.
Again, let’s look at the guiding ideology given by DDD:
Scale issue: breaking down boundaries. Divide and conquer disassembly with subdomains and bounded contexts.
In view of the divide and conquer idea, DDD provides two important design meta-models: bounded context and context mapping.
Structural issues: layered architecture and bounded isolation.
Layering plays a role in isolating business logic and technical implementation complexity issues. The layered architecture introduced by DDD encapsulates business logic into the domain layer, and places the technical implementation that supports business logic into the infrastructure layer. The application layer above the domain layer encapsulates application services and glues the two together for collaboration.
Change issues: Proactively design for change.
Changes cannot be controlled, we can only embrace them. In the demand analysis stage, 5W thinking is used to identify change patterns and control business changes. DDD uses model-driven design meta-models to model the domain of bounded contexts, forming a domain model that combines analysis, design, and implementation.
Finally, let’s look at the solution given by DDD. It introduces a set of design meta-models that are refined into patterns, enabling business software to control scale, split structures, and proactively respond to changes.
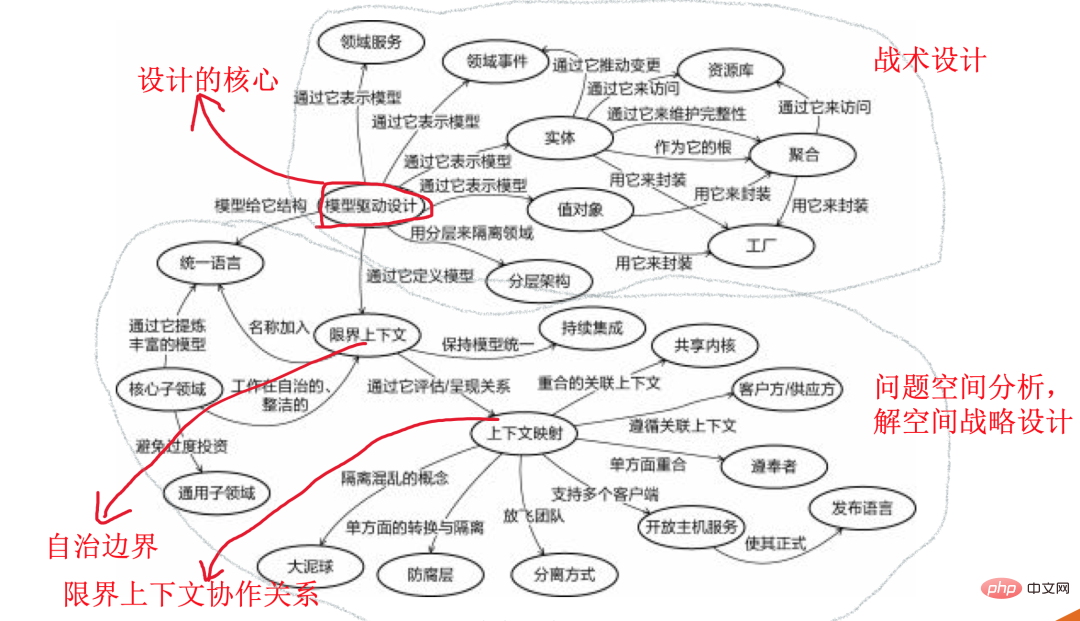
Let me briefly introduce this picture, which is divided into two parts. The first part is the part circled with dots below and does not involve specific technical implementation. Some meta-model solutions to deal with the problem space are carried out during the requirements analysis stage. In the other part, based on the first part, we will do the specific system architecture layering, object abstraction and aggregation, and service disassembly. At this stage, we will implement the corresponding design.
My understanding is this. This set of design metamodels provides a complete solution from demand analysis, design and implementation. System dismantling in the requirements analysis stage (corresponding to the sub-domain meta model in the figure). Then split it into the bounded context of update granularity. And the collaborative relationship scheme of each limit is given (corresponding to the context mapping meta-model in the figure). The design implementation phase provides the design element plan of model-driven design, through the granular design of the system's hierarchical architecture, domain services, aggregation, etc. Provide a set of complete, theoretically supported, implementable and standard solutions.
The above-mentioned DDD analysis and positioning of the complexity of the problem is completely the pain point in the phone robot system. The solutions given also perfectly solve various challenges faced by the business. After realizing its value, the team quickly reached a consensus to implement it in subsequent projects.
3. DDD implementation steps
I won’t go into detail about the meta-model details and business boundaries, but will directly give the actual steps and products of our team.
3.1 The first step of pre-research stage
Our experience in this part is that someone in the team acts as a forerunner, first spending energy on in-depth study of DDD-related concepts, and then synchronizing it to the entire team. As far as our team is concerned, the research phase is fragmented and it is difficult to estimate how long it will take. The team science popularization phase lasted 4 times and took 8 hours. After that, students in the team have the ability to learn quickly and deeply based on conceptual guidance. And organize team members to discuss with each other to confirm understanding.
3.2 The second step is to introduce guiding ideology and implementation specifications
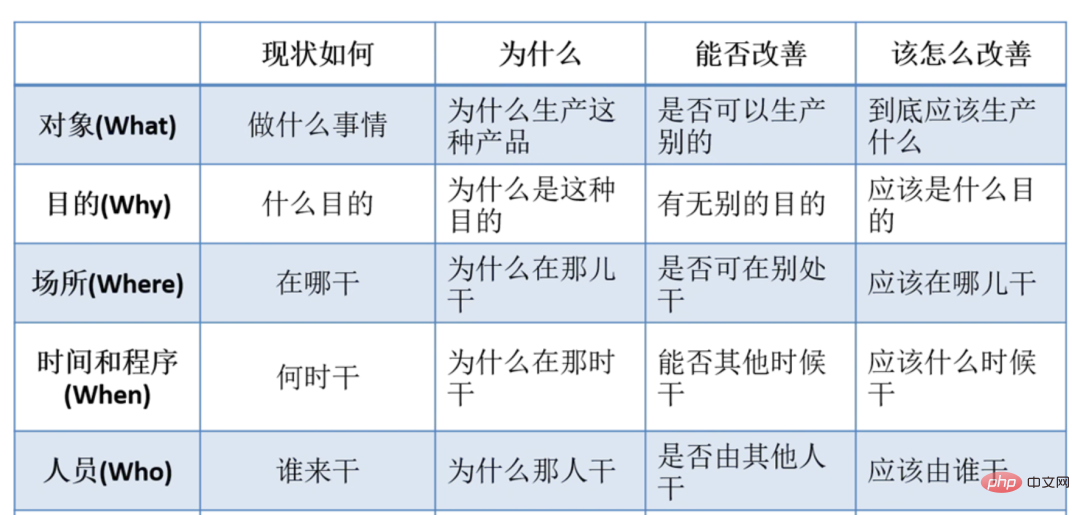
3.2.1 In the demand analysis stage, the theoretical support of the 5W model is introduced to help identify real needs and proactively control the direction of change and Eliminate meaningless requirements.
This part is the 5W theory as a theoretical support for product analysis needs. It is very helpful to identify real needs and better analyze the development direction of the business. Invalid requirements can also be reduced from the source, directly as shown in the figure above;
3.2.2 Introduce service specifications and implement document-based code business functions. It is helpful for development and subsequent requirements sorting, and can also be used as a consideration for unit test coverage.
- 3.2.2.1 The consensus among team members is that the service specification needs to be written first and then developed. The time spent writing the service specification is actually a matter of sorting out the technical understanding of the requirements and clarifying the ideas. This part of the time can be earned back when writing code later.
- 3.2.2.2 Service specification and requirements. The service specification corresponds to the single test. By the way, it solves the problem that there was no standard for single testing before (the code and method coverage that I understand cannot be called standards).
Here is the service specification template adopted by our team:
Number: a unique number that marks the business service.
Name: Business service name in the form of a verb phrase.
Description:
As
I want
so that
triggers the event:
The business service event actively triggered by the role can be a click on a UI control, a specific strategy, or a message sent by the companion system, etc.
Basic process:
It is used to express the main process of business services, that is, the business scenario of successful execution. It can also be called the "main success scenario".
Alternative process:
Extended process used to express business services, that is, business scenarios where execution fails.
Acceptance criteria:
A series of acceptable conditions or business rules, listed in bullet point form.
3.3 The third step is to determine the architecture solution
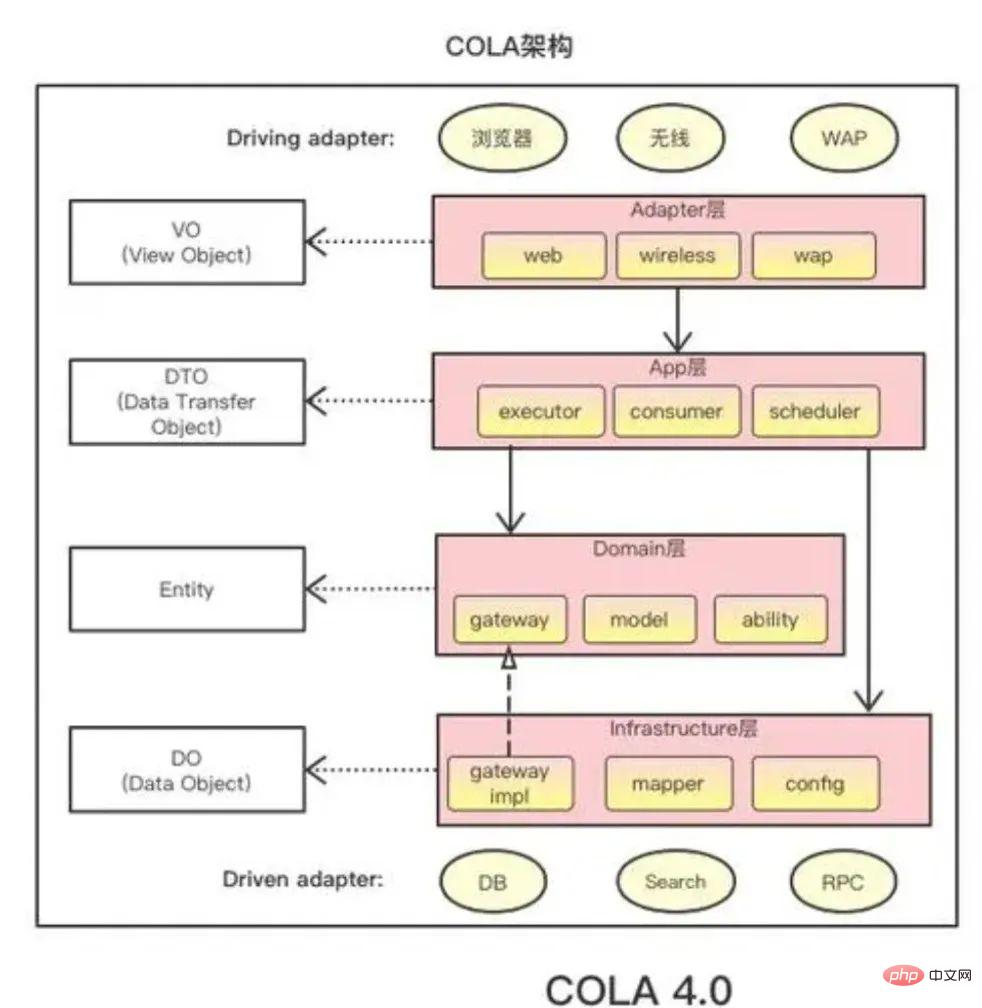
Learn the solution of the model-driven design metamodel in DDD. The main purpose is to divide the boundaries of responsibilities, that is, the bounded context, to change the traditional network structure relationship into a vertical segmentation relationship and reduce mutual dependence. The overall use of limited online text disassembly and diamond drive design forms the overall ideological guidance. The system adopts a layered architecture COLA 4.0
3.4 Step 4: Consensus naming standards form team coding specifications
Consensus on package naming, class naming, input and output within the team Reference message contract and other specifications. What I want to say here is that there is no reference standard. I hope everyone can first understand the idea of DDD, and then refer to the naming scheme with high consensus in the industry. At the same time, you need to take into account the programming style preferences of the team members, and ultimately formulate your own team's coding standards.
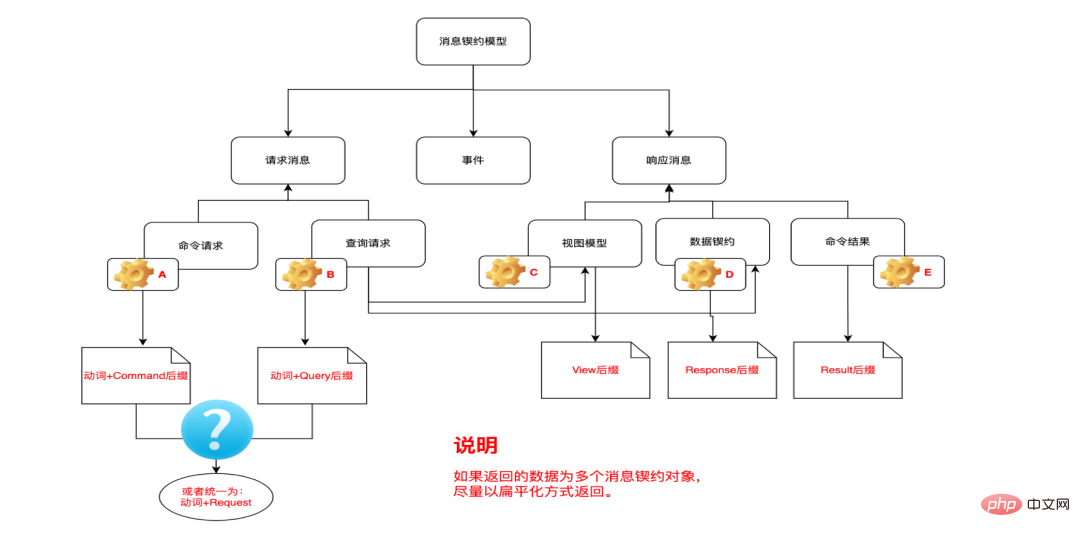
Let’s use the naming of our input and output messages as an example. After considering all parties, we did not adopt the particularly fine-grained naming method shown above. Instead, the simple consensus within the team is that the input parameter *request, the output parameter *reponse naming standard.
3.5 The fifth step is to identify the bounded context based on business characteristics
Based on the DDD idea, conduct event storming on the business, conduct global demand analysis and architecture mapping design under the guidance of a unified language, and identify The bounded context of the business.
Technical students design it based on their own business. It is relatively easy to find it by referring to the Demo information, so I won’t go into details here. Here is a guidance process for identifying bounded context, the V-shaped mapping process.
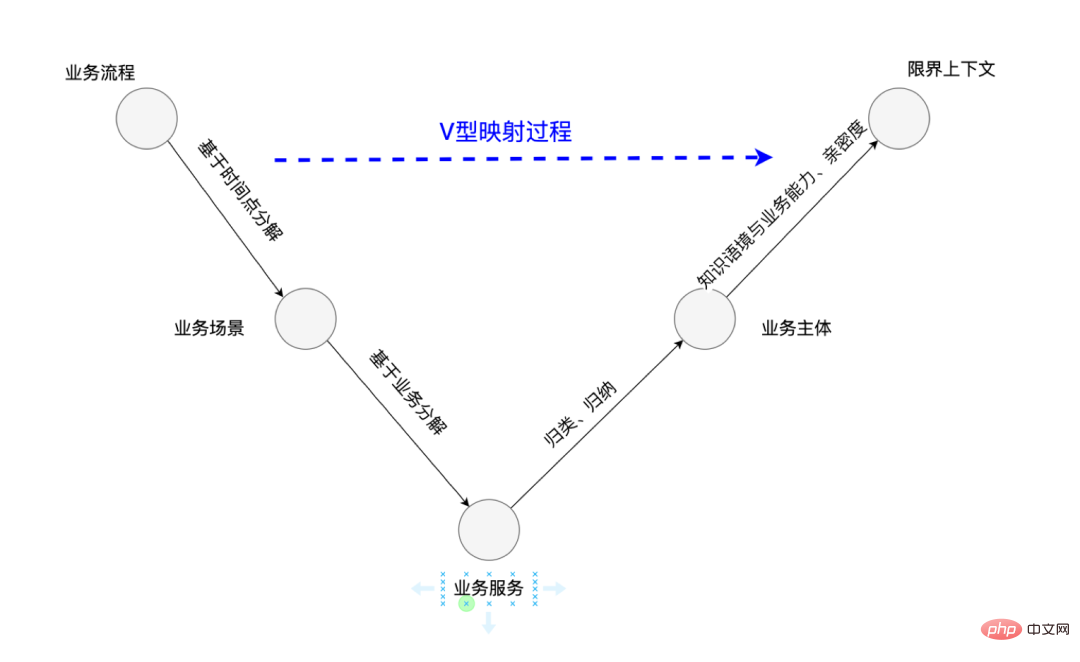
3.6 Finally enter the implementation stage of modeling
It is recommended to use test-driven development for coding, that is, use red, green and yellow drivers;
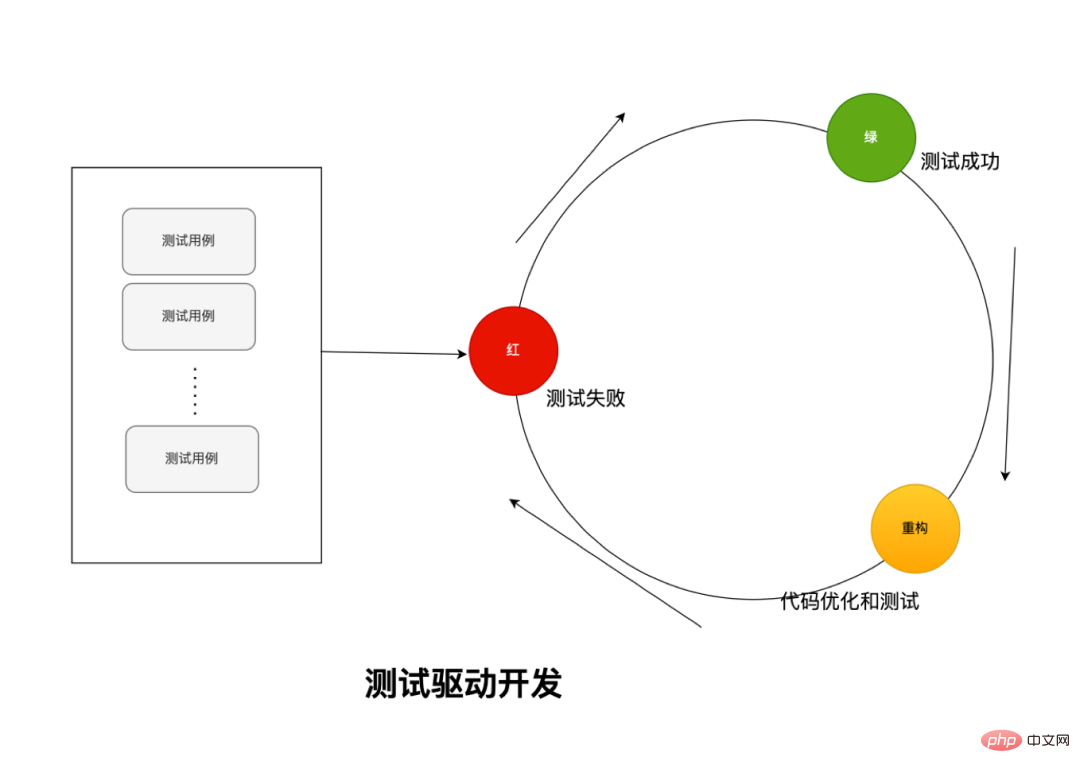
This method follows its three laws, which can improve the problem of under-design and over-design of requirements.
Law 1 |
Write only one test that happens to fail at a time. As a description of newly added functionality. |
Law 2 |
Don’t write any production code unless it just makes the failing test pass. |
Law Three |
Only do code refactoring or start adding new functions if all tests pass . |
4. Improvement brought to the team
4.1 From passively receiving needs to actively responding
During the needs analysis stage, apply the 5W principle. Analyze the rationality of demands and be able to proactively control the changing direction of the project. Solve "Challenge Three" to identify demand value and improve "Challenge Four" to control the direction of business development changes.
4.2 Reduce communication costs
Use unified language and ideological communication to reduce collaboration costs in all aspects of "Challenge Five".
4.3 Architecture design improvement
Reasonably dismantle the code scale by designing the sub-domain model and bounded context of the meta model. Through the layered thinking of DDD, the complexity of business logic and technical dimensions are isolated, and the code structure is clear. At the same time, the project adopts a diamond-shaped symmetrical structure and interacts with the outside through north-south gateways to avoid the occurrence of a network of modules. Solved the problem of "Challenge 2" and reduced the complexity of "Challenge 1".
4.4 Technical Implementation Improvement
When developing business functions, the team will consider the reasonable limits of the requirements. During the implementation process, we will consider whether to place it in the domain layer or the business service layer, and whether to use an anemia model or congestion in implementing functions.
4.5 Improvement of document specifications
In terms of document specifications, the service specification mechanism is introduced. It can be used as a tool to sort out requirements and as a basis for single testing. At the same time, service description documents are also provided for later use.
4.6 Code Implementation Improvement
In terms of code implementation, from architecture to coding implementation and naming, a set of marked specifications has been formed.
In general, under this model, the team's way of thinking has changed. By applying various meta-models, we can meet the challenges brought by different aspects from demand analysis to system architecture and code implementation.
5. Conflicts encountered from theory to practice
5.1 Anemia model PK congestion model
Anemia model: In layman’s terms, it is a domain object that only has getter/setter methods for attributes. Pure data classes, business logic and application logic are all placed in the service layer. The domain object under this model is called "anemic domain object" by Martin Fowler.
Congestion model: On the contrary, the congestion model not only contains the properties of the object, but also the behavior of the object, including business logic.
From an object-oriented perspective, objects contain attributes and behaviors, so the congestion model should be used, and DDD also recommends using the congestion model in principle. But when it comes to the specific development status, even though the anemia model has many problems, it has been in the industry for so many years and is so commonly used, and it still has its value. In addition, most JAVA applications use the Mybatis technology stack, and many objects are anemic entities automatically generated by plug-ins. So the question is, adopting the hyperemia model means abandoning some convenient tools. There are big differences within the team on this issue. In the end, our approach is that there is no hard standard for this part, but it is recommended to use the hyperemia mode.
5.2 Strictly abide by data conversion constraints
PK streamlined and efficient external data use directly
In the thinking of DDD, in order to ensure the reliability of domain services. The data that domain services rely on is required to be entities and aggregate data in the domain, and direct use of external message contract data is not allowed. The conversion of data obtained from north-south gateways corresponding to the diamond symmetrical architecture will bring additional workload. Some team members suggested that certain relatively stable structures do not need to comply with this principle. The reason is that it can increase development speed, and they believe that 90% of the data may be resources with relatively stable structures such as databases. But in the end, the team was still strictly required to abide by this guiding ideology.
5.3 Cache processing allows shared PK boundary isolation
Cache processing in different boundaries of the same system: allows shared PK boundary isolation.
Judging from the scenario at that time, allowing sharing can reduce some workload and save resources in the short term. But the reason why we need to draw boundaries is to break up the relationship and prevent it from getting too big. The suggestion given here is to first consider whether it is reasonable to merge services that share data into one boundary. If merging is not possible, the data must be isolated.
5.4 The service specification compares the front-end PK back-end of the requirements
The guiding theoretical ideas are very beautiful, and the technical implementation thinking is required to be shielded during the requirements analysis. But after all, it has to be implemented in the technology stack. When it comes to technology implementation, it will be interfered by technology implementation. A prominent issue at that time was that the implementation of functions could be placed on the front end or implemented as a back-end service.
Example 1: The requirement requires "id name" combination display, but the two fields of id and name returned by the back-end interface are combined by the actual front-end technology stack, so the service specifications for the front-end and back-end are inconsistent.
Example 2: The requirement requires verification that the parameters are not empty. In some internal systems, our team's technical team consists of front-end and back-end full-stack engineers, who divide the work and develop modules according to needs. Often they are not so rigorous as to verify both ends. It also leads to conflicts in which end the service specification is oriented.
Our final choice: the team adopts a back-end service layer. But at the same time, we will make some improvements, such as moving verification and other functions to the interface level.
5.5 Who will ensure that the service specification is written correctly? Product PK Technology
In the initial stage, the ideal state is to be verified by demand-side products, based on the principle of whoever needs it confirms it. However, due to the differences in 4.4, our actual implementation is reviewed by the technical person in charge.
6. Future improvements and summary in DDD application
The team has currently implemented the application of DDD from the perspective of architecture and specifications. But some details, such as the design of aggregate classes, entities, and value objects, are not particularly detailed. We will further advance these fine-grained improvements in the future. At the same time, some old projects in use will be transformed and reconstructed according to DDD ideas.
Some people think that applying DDD will reduce development efficiency. This is also a concern of many teams. This is how we look at this problem. The scenario of applying DDD is to solve complex business problems, which will indeed increase the amount of code. But it does not mean reducing development efficiency. A clear architectural structure, aggregated domain services, and standardized standards will bring benefits far greater than the investment in later demand upgrades, code maintenance, and complexity control. Moreover, according to data given by the software industry, 80% of the time is spent on demand analysis and design, while development time only accounts for 20%. Therefore this part of the loss is not the focus.
Finally, let me describe my feelings about using DDD. There are many types of DDD meta-models, and everyone can learn and adopt them purposefully based on the pain points faced by the business. In the actual business environment, our domain models have more or less "specialities". If it is 100% compliant with the DDD specification, the cost may be relatively high, so the most important thing is to understand the DDD idea and make the final choice A solution that suits your business.
About the author

Li Xiaohua
- Dealer Business Department-Dealer Technology Department.
- Joined Autohome in 2016 and currently works in the dealer data architecture team, responsible for the phone robot project.
The above is the detailed content of DDD practice for phone robot team. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Why can't I make calls on my mobile phone?
Nov 23, 2023 pm 04:04 PM
Why can't I make calls on my mobile phone?
Nov 23, 2023 pm 04:04 PM
Reasons why mobile phone calls cannot be made: 1. Signal problem; 2. Mobile phone account problem; 3. Mobile phone setting problem; 4. SIM card problem; 5. Operator network problem; 6. Mobile phone hardware problem; 7. Software problem; 8 , specific area or time period issues; 9. Service provider issues; 10. Other issues. Detailed introduction: 1. Signal problems may be one of the most common reasons why mobile phones cannot make calls. If the mobile phone does not have enough signal, it may not be possible to make calls; 2. Mobile phone account problems, if the mobile phone account is in arrears or has been suspended from service, etc. .
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 How can AI make robots more autonomous and adaptable?
Jun 03, 2024 pm 07:18 PM
How can AI make robots more autonomous and adaptable?
Jun 03, 2024 pm 07:18 PM
In the field of industrial automation technology, there are two recent hot spots that are difficult to ignore: artificial intelligence (AI) and Nvidia. Don’t change the meaning of the original content, fine-tune the content, rewrite the content, don’t continue: “Not only that, the two are closely related, because Nvidia is expanding beyond just its original graphics processing units (GPUs). The technology extends to the field of digital twins and is closely connected to emerging AI technologies. "Recently, NVIDIA has reached cooperation with many industrial companies, including leading industrial automation companies such as Aveva, Rockwell Automation, Siemens and Schneider Electric, as well as Teradyne Robotics and its MiR and Universal Robots companies. Recently,Nvidiahascoll
 After 2 months, the humanoid robot Walker S can fold clothes
Apr 03, 2024 am 08:01 AM
After 2 months, the humanoid robot Walker S can fold clothes
Apr 03, 2024 am 08:01 AM
Editor of Machine Power Report: Wu Xin The domestic version of the humanoid robot + large model team completed the operation task of complex flexible materials such as folding clothes for the first time. With the unveiling of Figure01, which integrates OpenAI's multi-modal large model, the related progress of domestic peers has been attracting attention. Just yesterday, UBTECH, China's "number one humanoid robot stock", released the first demo of the humanoid robot WalkerS that is deeply integrated with Baidu Wenxin's large model, showing some interesting new features. Now, WalkerS, blessed by Baidu Wenxin’s large model capabilities, looks like this. Like Figure01, WalkerS does not move around, but stands behind a desk to complete a series of tasks. It can follow human commands and fold clothes
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
 Ten humanoid robots shaping the future
Mar 22, 2024 pm 08:51 PM
Ten humanoid robots shaping the future
Mar 22, 2024 pm 08:51 PM
The following 10 humanoid robots are shaping our future: 1. ASIMO: Developed by Honda, ASIMO is one of the most well-known humanoid robots. Standing 4 feet tall and weighing 119 pounds, ASIMO is equipped with advanced sensors and artificial intelligence capabilities that allow it to navigate complex environments and interact with humans. ASIMO's versatility makes it suitable for a variety of tasks, from assisting people with disabilities to delivering presentations at events. 2. Pepper: Created by Softbank Robotics, Pepper aims to be a social companion for humans. With its expressive face and ability to recognize emotions, Pepper can participate in conversations, help in retail settings, and even provide educational support. Pepper's
 Cloud Whale Xiaoyao 001 sweeping and mopping robot has a 'brain'! | Experience
Apr 26, 2024 pm 04:22 PM
Cloud Whale Xiaoyao 001 sweeping and mopping robot has a 'brain'! | Experience
Apr 26, 2024 pm 04:22 PM
Sweeping and mopping robots are one of the most popular smart home appliances among consumers in recent years. The convenience of operation it brings, or even the need for no operation, allows lazy people to free their hands, allowing consumers to "liberate" from daily housework and spend more time on the things they like. Improved quality of life in disguised form. Riding on this craze, almost all home appliance brands on the market are making their own sweeping and mopping robots, making the entire sweeping and mopping robot market very lively. However, the rapid expansion of the market will inevitably bring about a hidden danger: many manufacturers will use the tactics of sea of machines to quickly occupy more market share, resulting in many new products without any upgrade points. It is also said that they are "matryoshka" models. Not an exaggeration. However, not all sweeping and mopping robots are
 The humanoid robot can do magic, let the Spring Festival Gala program team find out more
Feb 04, 2024 am 09:03 AM
The humanoid robot can do magic, let the Spring Festival Gala program team find out more
Feb 04, 2024 am 09:03 AM
In the blink of an eye, robots have learned to do magic? It was seen that it first picked up the water spoon on the table and proved to the audience that there was nothing in it... Then it put the egg-like object in its hand, then put the water spoon back on the table and started to "cast a spell"... …Just when it picked up the water spoon again, a miracle happened. The egg that was originally put in disappeared, and the thing that jumped out turned into a basketball... Let’s look at the continuous actions again: △ This animation shows a set of actions at 2x speed, and it flows smoothly. Only by watching the video repeatedly at 0.5x speed can it be understood. Finally, I discovered the clues: if my hand speed were faster, I might be able to hide it from the enemy. Some netizens lamented that the robot’s magic skills were even higher than their own: Mag was the one who performed this magic for us.
