

How to implement regular expressions in Python

Python regular expression
Regular expression itself is knowledge independent of programming language, but it is also dependent on programming language. Basically, the programming language we use provides Of course, there are some differences in its implementation. Some support more functions and some support less.
Because regular expressions are a widely used tool in practice, I think it is unreliable to learn without language.
Introduction to regular expression functions
Regular expression main API relationship diagram
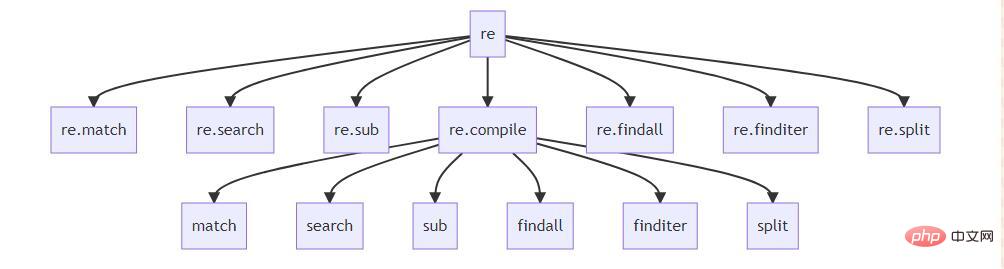
This diagram is mine Personally, I think I have basically clarified the relationship between the functions here. Their functions are:
match matches the regular expression from the beginning of the text and returns the matching object. If not, return None
#search matches the regular expression in the entire text and returns the first matching object. If not, return None.
sub Use regular expressions for text replacement (function of regular expressions: search and replace)
findall matches regular expressions from the entire text An expression that returns all matching results as a list.
finditer matches a regular expression from the entire text, returning all matching results as an iterator.
split Use regular expressions to split text
As you can see here, ·re· there are many functions that can be used immediately, Then re.compile There are many functions with the same name below. Directly under the ·re· module are officially provided functions for easy use. The most orthodox way to use them is through re.compile. So, for the next content, I basically use re.compile and the methods below to achieve it.
re.compile function
compile The function is used to compile regular expressions and generate a regular expression (Pattern) object for match( ) and search() and other functions.
Syntax:
re.compile(pattern[, flags])
pattern: a regular expression in the form of a string
flags optional, indicating matching pattern , such as ignoring case, multi-line mode, etc., the specific parameters are:
re.I Ignore case
re. L multi-line mode
re.S is '.' and any character including newline ('.' does not include newline)
re.U represents the special character set \w, \W, \b, \B, \d, \D, \s, \S and relies on the Unicode character attribute database
re. ##Learning Template
Next we will gradually learn the content of regular expressions, which is very interesting! Interesting and Excited!
Here is a sample template that will be used all the time. This template is the most important thing in this blog, and subsequent content will be expanded based on it. So, please understand it well.
import re
s = 'runoob 123 google 456'
result1 = re.findall(r'\d+', s)
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall(s)
result3 = pattern.findall(s, 0, 20)
print(result1)
print(result2)
print(result3)
"""
output:
[‘123', ‘456']
[‘123', ‘456']
[‘123', ‘45']
"""
Copy after login
import re s = 'runoob 123 google 456' result1 = re.findall(r'\d+', s) pattern = re.compile(r'\d+') # 查找数字 result2 = pattern.findall(s) result3 = pattern.findall(s, 0, 20) print(result1) print(result2) print(result3) """ output: [‘123', ‘456'] [‘123', ‘456'] [‘123', ‘45'] """
Note: The regular expression regexp will use the
r prefix before starting. The purpose of this is In order to avoid using a lot of escape characters in regular expressions, which destroys the overall readability. 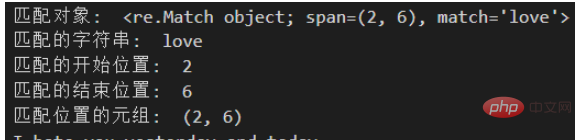
The matching object can obtain information about the regular expression. Its most important methods and properties are:
Methods/Properties
Purpose
| group() | Return the regular matching string |
| Return the starting position of the match | |
| Return the end position of the match | |
| Return a tuple containing the matching (start, end) position | |
The above is the detailed content of How to implement regular expressions in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1381
1381
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
Efficient training of PyTorch models on CentOS systems requires steps, and this article will provide detailed guides. 1. Environment preparation: Python and dependency installation: CentOS system usually preinstalls Python, but the version may be older. It is recommended to use yum or dnf to install Python 3 and upgrade pip: sudoyumupdatepython3 (or sudodnfupdatepython3), pip3install--upgradepip. CUDA and cuDNN (GPU acceleration): If you use NVIDIAGPU, you need to install CUDATool
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MinIO Object Storage: High-performance deployment under CentOS system MinIO is a high-performance, distributed object storage system developed based on the Go language, compatible with AmazonS3. It supports a variety of client languages, including Java, Python, JavaScript, and Go. This article will briefly introduce the installation and compatibility of MinIO on CentOS systems. CentOS version compatibility MinIO has been verified on multiple CentOS versions, including but not limited to: CentOS7.9: Provides a complete installation guide covering cluster configuration, environment preparation, configuration file settings, disk partitioning, and MinI
 How to choose the PyTorch version under CentOS
Apr 14, 2025 pm 02:51 PM
How to choose the PyTorch version under CentOS
Apr 14, 2025 pm 02:51 PM
When selecting a PyTorch version under CentOS, the following key factors need to be considered: 1. CUDA version compatibility GPU support: If you have NVIDIA GPU and want to utilize GPU acceleration, you need to choose PyTorch that supports the corresponding CUDA version. You can view the CUDA version supported by running the nvidia-smi command. CPU version: If you don't have a GPU or don't want to use a GPU, you can choose a CPU version of PyTorch. 2. Python version PyTorch
 How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
CentOS Installing Nginx requires following the following steps: Installing dependencies such as development tools, pcre-devel, and openssl-devel. Download the Nginx source code package, unzip it and compile and install it, and specify the installation path as /usr/local/nginx. Create Nginx users and user groups and set permissions. Modify the configuration file nginx.conf, and configure the listening port and domain name/IP address. Start the Nginx service. Common errors need to be paid attention to, such as dependency issues, port conflicts, and configuration file errors. Performance optimization needs to be adjusted according to the specific situation, such as turning on cache and adjusting the number of worker processes.
