
 Technology peripherals
AI
Even the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters
Technology peripherals
AI
Even the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters
Even the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters

I can’t keep up with the volume of the big model without sleeping...
No, Microsoft Asia The institute has just released a multimodal large language model (MLLM) - KOSMOS-1.

Paper address: https://arxiv.org/pdf/2302.14045.pdf
The title of the paper, Language Is Not All You Need, comes from a famous saying.
There is a sentence in the article, "The limitations of my language are the limitations of my world. - Austrian philosopher Ludwig Wittgenstein"

##Then the question comes...
Can you figure it out by asking KOSMOS-1 "Is it a duck or a rabbit" while holding the picture? This meme with a history of more than 100 years just can’t fix Google AI.
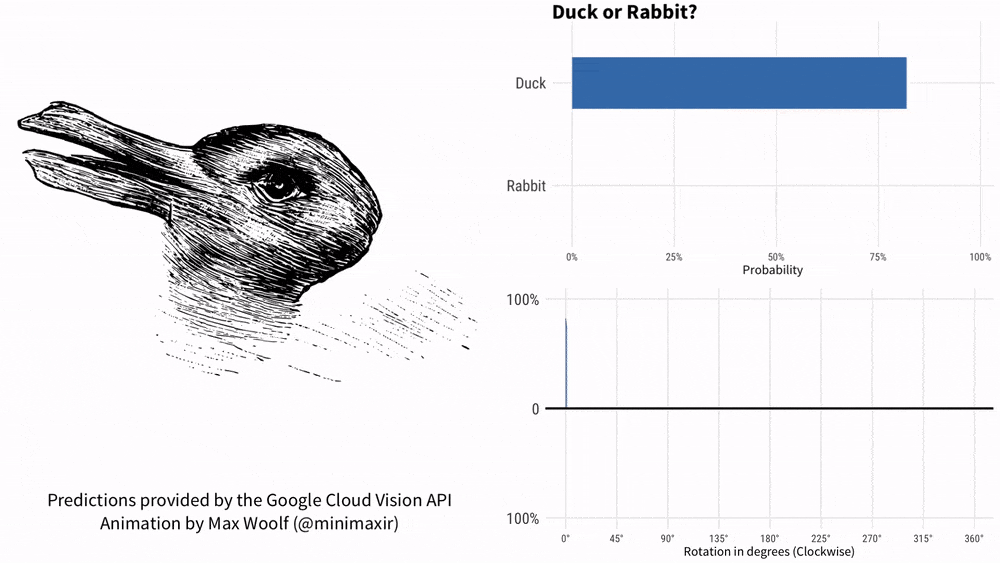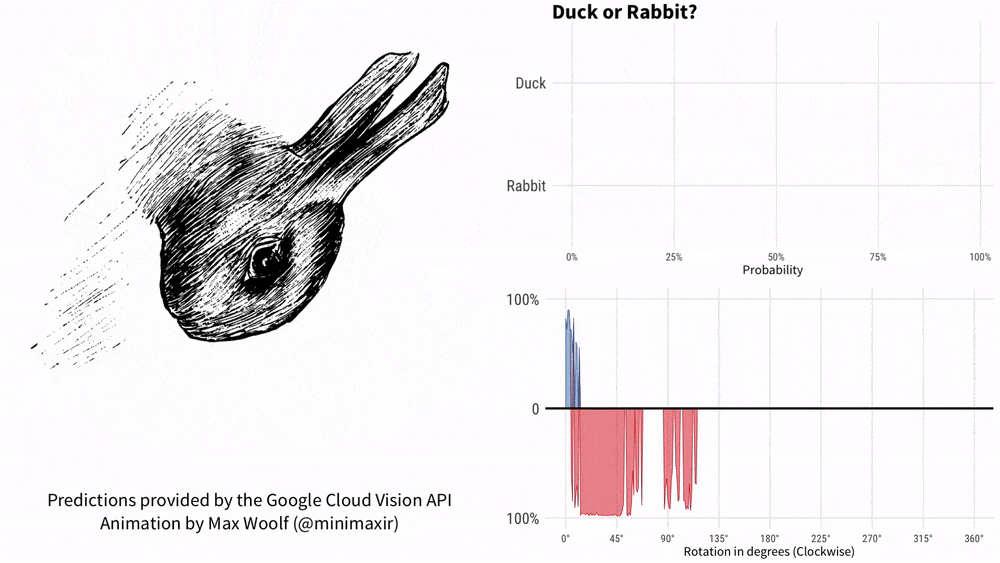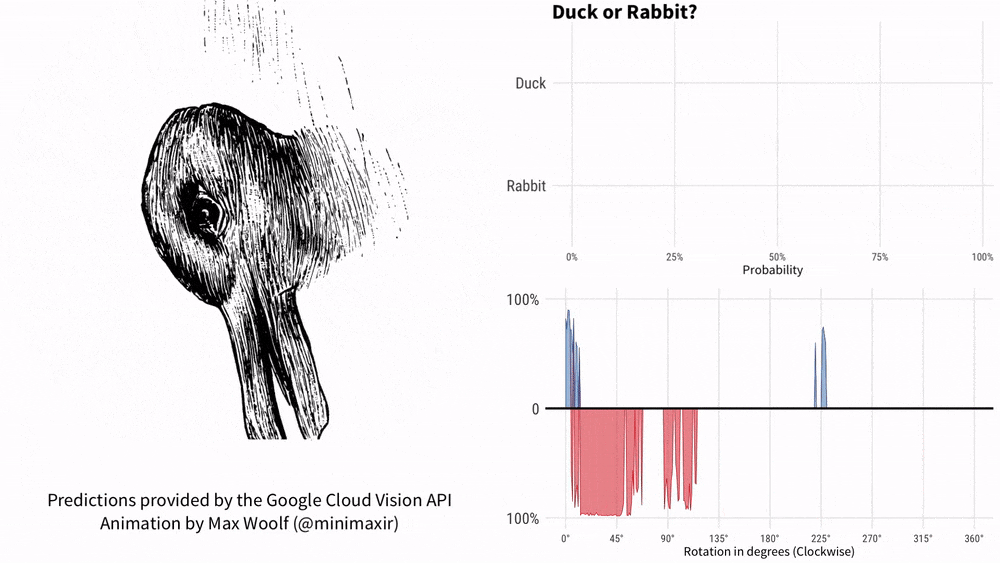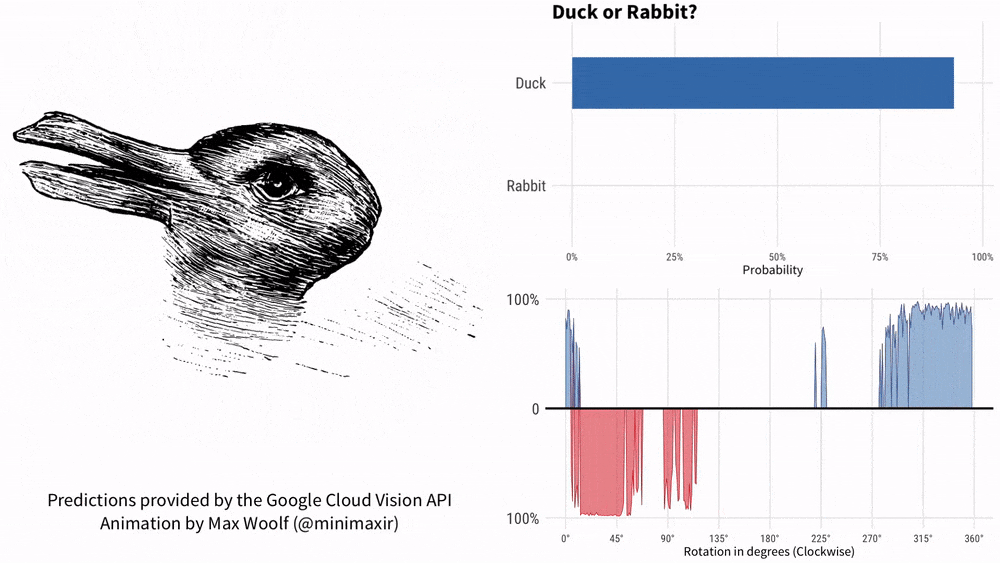
In 1899, American psychologist Joseph Jastrow first used the "Duck and Rabbit Chart" to It shows that perception is not only what people see, but also a mental activity.
#Now, KOSMOS-1 can combine this kind of perception and language model.
#-What’s in the picture?
#-Like a duck.
#-If not a duck, what is it?
#-Looks more like a rabbit.
-Why?
#-It has bunny ears.
#If you ask this question, KOSMOS-1 is really a bit like Microsoft’s version of ChatGPT.

Not only that, Kosmos-1 can also understand images, text, and text with text. Images, OCR, image captions, visual QA.
# Even IQ tests are not a problem.
"Universe" is omnipotentKosmos comes from the Greek word cosmos, which means "universe".
#According to the paper, the latest Kosmos-1 model is a multi-modal large-scale language model.
The backbone is a causal language model based on Transformer. In addition to text, other modalities, such as vision and audio, can be embedded in the model.
The Transformer decoder serves as a universal interface for multi-modal inputs, so it can perceive general modalities, perform context learning, and follow instructions.
Kosmos-1 achieves impressive performance on language and multimodal tasks without fine-tuning, including image recognition with text instructions, visual question answering, and multimodal dialogue .
#The following are some example styles generated by Kosmos-1.
Picture explanation, picture question and answer, web page question answer, simple number formula, and number recognition.

So, on which data sets is Kosmos-1 pre-trained?
The database used for training includes text corpus, image-subtitle pairs, image and text cross data sets.
Text corpus taken from The Pile and Common Crawl (CC);
Images -The sources of subtitle pairs are English LAION-2B, LAION-400M, COYO-700M and Conceptual Captions;
The source of text cross data set is Common Crawl snapshot .
#Now that the database is available, the next step is to pre-train the model.
The MLLM component has 24 layers, 2,048 hidden dimensions, 8,192 FFNs and 32 attention heads, resulting in approximately 1.3B parameters.
In order to ensure the stability of the optimization, Magneto initialization is used; in order to converge faster, the image representation is derived from a pre-trained image with 1024 feature dimensions. Obtained from CLIP ViT-L/14 model. During the training process, images are preprocessed to 224×224 resolution, and the parameters of the CLIP model are frozen except for the last layer.
#The total number of parameters of KOSMOS-1 is approximately 1.6 billion.
To better align KOSMOS-1 with instructions, language-only instruction adjustments were made [LHV 23, HSLS22], i.e. The model continues to be trained on instruction data, which is the only language data, mixed with the training corpus.
The tuning process is carried out according to the language modeling method, and the selected instruction data sets are Unnatural Instructions [HSLS22] and FLANv2 [LHV 23].
#The results show that the improvement in command following ability can be transferred across modes.
In short, MLLM can benefit from cross-modal transfer, transferring knowledge from language to multimodality and vice versa;
10 tasks in 5 categories, all figured out
You will know if a model is easy to use or not, just take it out and play around.
The research team conducted experiments from multiple angles to evaluate the performance of KOSMOS-1, including ten tasks in 5 categories:
1 Language tasks (language understanding, language generation, text classification without OCR)
2 Multi-modal transfer (common sense Reasoning)
3 Nonverbal Reasoning (IQ Test)
4 Perception - Verbal Tasks (image description, visual Q&A, web Q&A)
5 Vision tasks (zero-shot image classification, zero-shot image classification with description)
No OCR Text Classification
This is a text and image-focused understanding task that does not rely on optical character recognition (OCR).
The accuracy of KOSMOS-1 on HatefulMemes and on the Rendered SST-2 test set is higher than other models.
Although Flamingo explicitly provides OCR text into the prompt, KOSMOS-1 does not access any external tools or resources, which demonstrates that KOSMOS-1 reads and understands the rendering The inherent ability of text within images.
IQ Test
Raven Intelligence Test is an assessment One of the most commonly used tests of non-verbal.
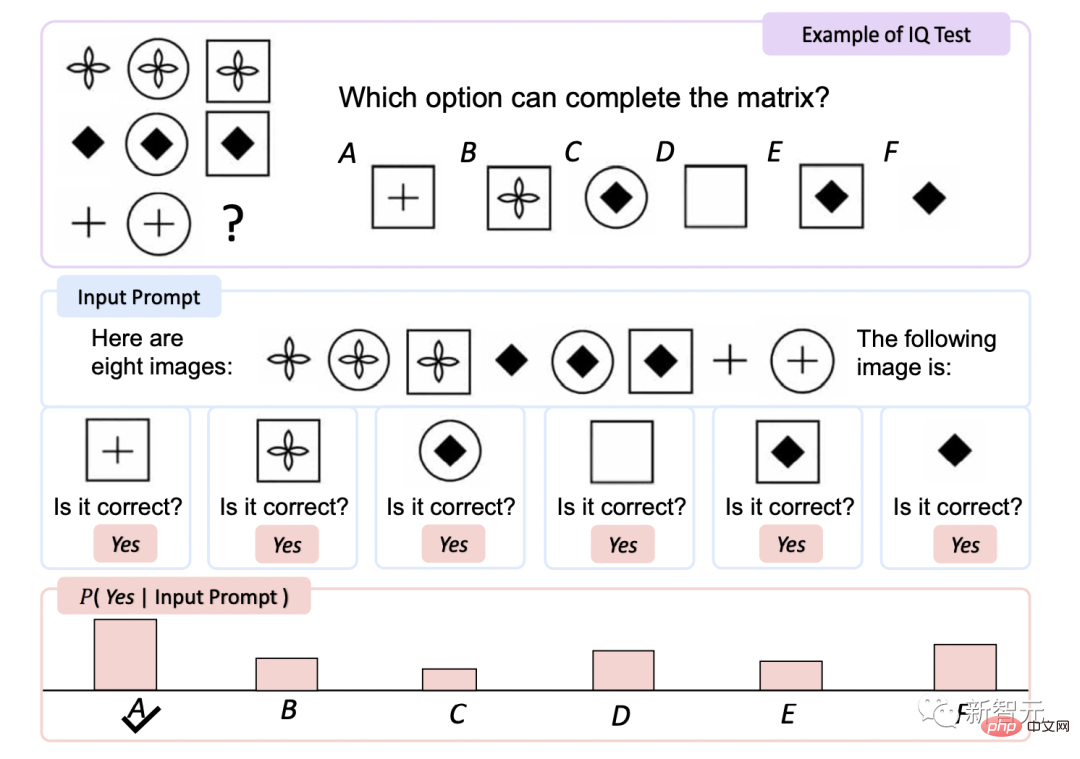
KOSMOS-1 improves accuracy by 5.3% compared to random selection without fine-tuning , after fine-tuning, it increased by 9.3%, indicating its ability to perceive abstract concept patterns in non-linguistic environments.
This is the first time a model has been able to complete the zero-shot Raven test, demonstrating the potential of MLLMs for zero-shot non-verbal reasoning by combining perception and language models.

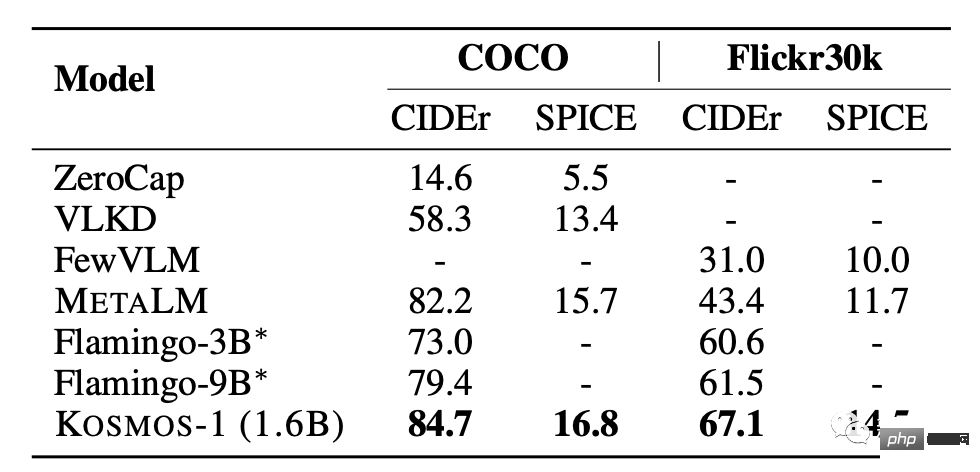
##Image description
KOSMOS-1 has excellent zero-sample performance in both COCO and Flickr30k tests. Compared with other models, it scores higher but uses a smaller number of parameters.
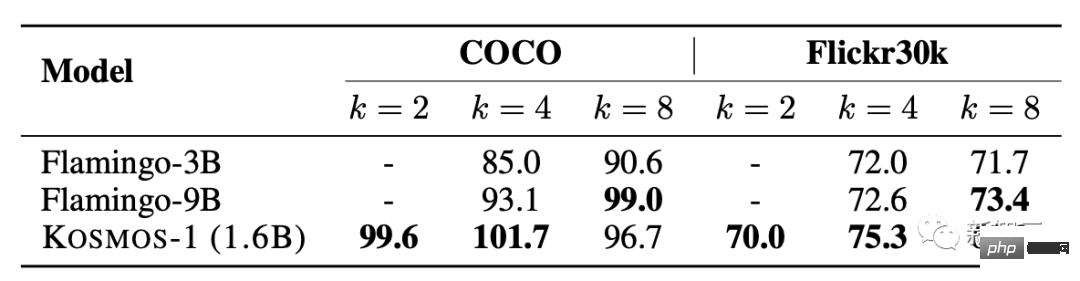
In the few-sample performance test, the score increases as the k value increases .
##Zero-shot image classification
Given an input image, connect the image with the prompt "The photo of the". Then, feed the model to get the class name of the image.

By evaluating the model on ImageNet [DDS 09], both with and without constraints Under constrained conditions, the image classification effect of KOSMOS-1 is significantly better than that of GIT [WYH 22], demonstrating its powerful ability to complete visual tasks.

## Common sense reasoning Visual common sense reasoning tasks require models to understand the properties of everyday objects in the real world, such as color, size, and shape. These tasks are challenging because they may require more information about them than in text. Information about object properties. The results show that the reasoning ability of KOSMOS-1 is significantly better than the LLM model in terms of size and color. This is mainly because KOSMOS-1 has multi-modal transfer capabilities, which enables it to apply visual knowledge to language tasks without having to rely on textual knowledge and clues for reasoning like LLM. 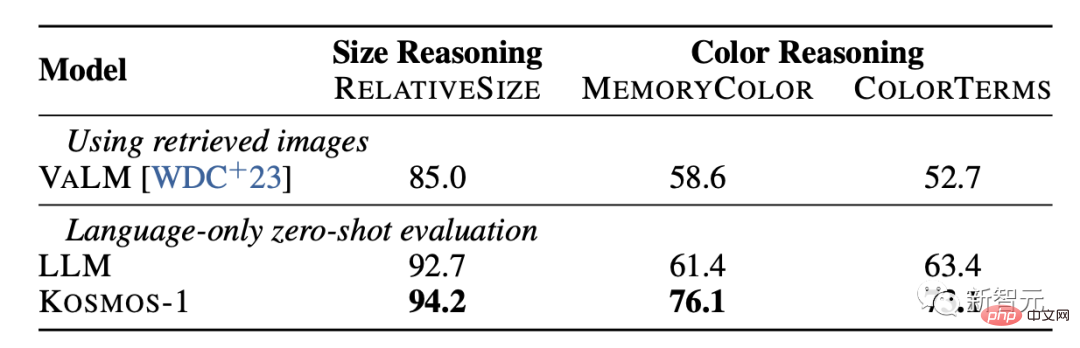
##For Microsoft Kosmos-1, netizens praised Dao, in the next 5 years, I can see an advanced robot browsing the web and working based on human text input only through visual means. Such interesting times.

The above is the detailed content of Even the century-old meme is clear! Microsoft's multi-modal 'Universe' handles IQ testing with only 1.6 billion parameters. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
