
 Technology peripherals
AI
Latest research, GPT-4 exposes shortcomings! Can't quite understand the language ambiguity!
Technology peripherals
AI
Latest research, GPT-4 exposes shortcomings! Can't quite understand the language ambiguity!
Latest research, GPT-4 exposes shortcomings! Can't quite understand the language ambiguity!

Natural Language Inference (NLI) is an important task in natural language processing. Its goal is to determine whether the hypothesis can be inferred from the premises based on the given premises and assumptions. However, since ambiguity is an intrinsic feature of natural language, dealing with ambiguity is also an important part of human language understanding. Due to the diversity of human language expressions, ambiguity processing has become one of the difficulties in solving natural language reasoning problems. Currently, various natural language processing algorithms are applied in scenarios such as question and answer systems, speech recognition, intelligent translation, and natural language generation, but even with these technologies, completely resolving ambiguity is still an extremely challenging task.
For NLI tasks, large natural language processing models such as GPT-4 do face challenges. One problem is that language ambiguity makes it difficult for models to accurately understand the true meaning of sentences. In addition, due to the flexibility and diversity of natural language, various relationships may exist between different texts, which makes the data set in the NLI task extremely complex. It also affects the universality and versatility of the natural language processing model. Generalization capabilities pose significant challenges. Therefore, in dealing with ambiguous language, it will be crucial if large models are successful in the future, and large models have been widely used in fields such as conversational interfaces and writing aids. Dealing with ambiguity will help adapt to different contexts, improve the clarity of communication, and the ability to identify misleading or deceptive speech.
The title of this paper discussing ambiguity in large models uses a pun, "We're Afraid...", which not only expresses the current concerns about the difficulty of language models in accurately modeling ambiguity, but also implies that the paper The language structure described. This article also shows that people are working hard to develop new benchmarks to truly challenge powerful new large models in order to understand and generate natural language more accurately and achieve new breakthroughs in models.
Paper title: We're Afraid Language Models Aren't Modeling Ambiguity
Paper link: https://arxiv.org/abs/2304.14399
Code and data address : https://github.com/alisawuffles/ambient
The author of this article plans to study whether the pre-trained large model has the ability to recognize and distinguish sentences with multiple possible interpretations, and evaluate how the model distinguishes different readings and interpretations . However, existing benchmark data often does not contain ambiguous examples, so one needs to build one's own experiments to explore this issue.
The traditional NLI three-way annotation scheme refers to a labeling method used for natural language inference (NLI) tasks. It requires the annotator to choose one label among three labels to represent the original text and the hypothesis. relationship between. The three labels are usually "entailment", "neutral" and "contradiction".
The authors used the format of the NLI task to conduct experiments, adopting a functional approach to characterize ambiguity through the impact of ambiguity in premises or assumptions on implication relationships. The authors propose a benchmark called AMBIENT (Ambiguity in Entailment) that covers a variety of lexical, syntactic, and pragmatic ambiguities, and more broadly covers sentences that may convey multiple different messages.
As shown in Figure 1, ambiguity can be an unconscious misunderstanding (top of Figure 1) or it can be deliberately used to mislead the audience (bottom of Figure 1). For example, if a cat gets lost after leaving home, then it is lost in the sense that it cannot find its way home (implication edge); if it has not returned home for several days, then it is lost in the sense that others cannot find it. In a sense, it is also lost (neutral side).
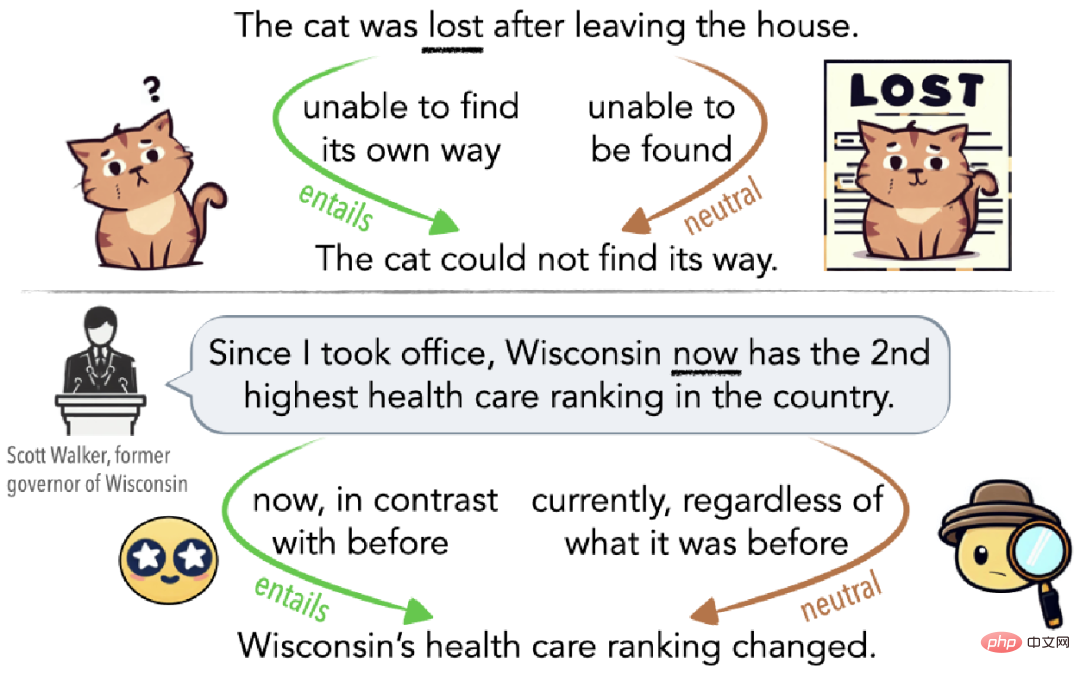
▲Figure 1 Example of ambiguity explained by Cat Lost
AMBIENT Dataset Introduction
Selected Example
The authors provide 1645 sentence examples covering multiple types of ambiguity, including handwriting samples and from existing NLI datasets and linguistics textbooks. Each example in AMBIENT contains a set of labels corresponding to various possible understandings, and a disambiguation rewrite for each understanding, as shown in Table 1.
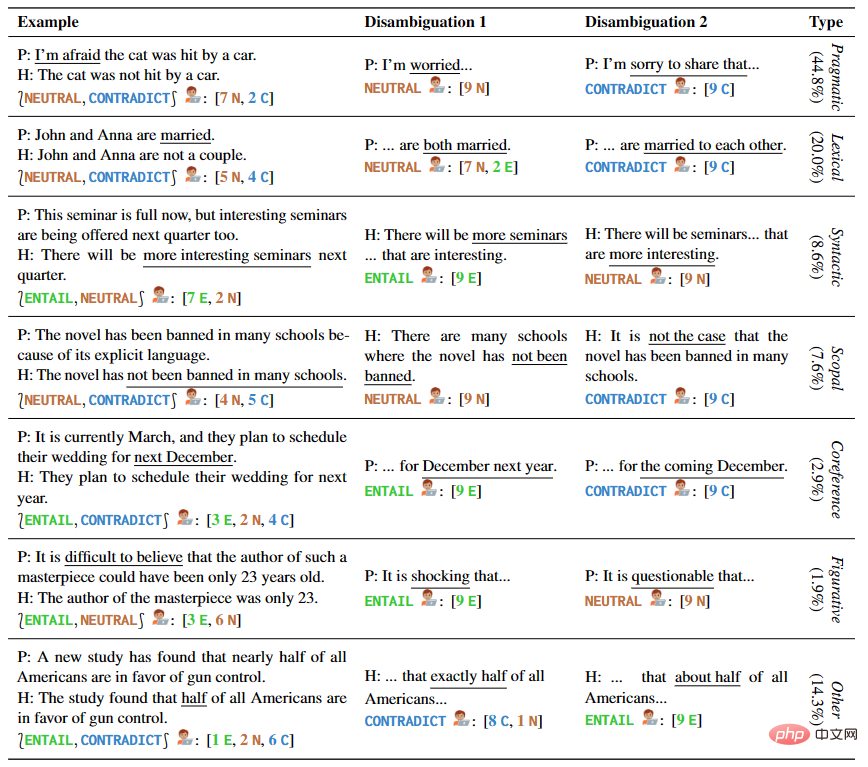
▲Table 1 Premises and Assumptions in Selected Examples
Generated Examples
The researchers also used overgeneration and filtering approach to build a large corpus of unlabeled NLI examples to more comprehensively cover different ambiguity situations. Inspired by previous work, they automatically identify pairs of premises that share reasoning patterns and enhance the quality of the corpus by encouraging the creation of new examples with the same patterns.
Comments and Verification
Annotations and annotations are required for the examples obtained in the previous steps. This process involved annotation by two experts, verification and summary by one expert, and verification by some authors. Meanwhile, 37 linguistics students selected a set of labels for each example and provided disambiguation rewrites. All these annotated examples were filtered and verified, resulting in 1503 final examples.
The specific process is shown in Figure 2: First, use InstructGPT to create unlabeled examples, and then two linguists independently annotate them. Finally, through integration by an author, the final annotations and annotations are obtained.
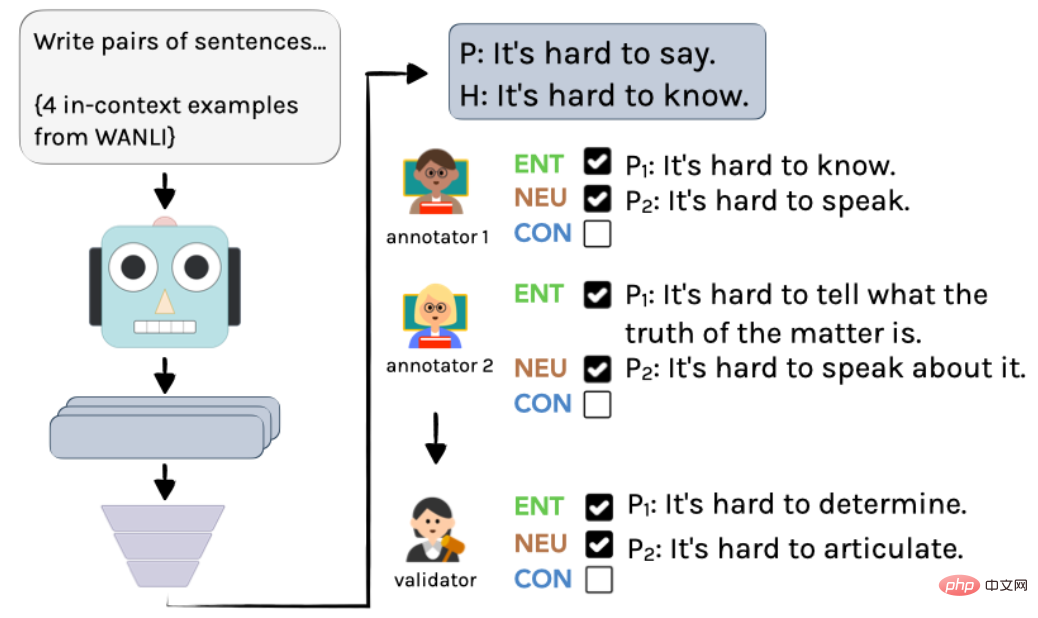
▲Figure 2 Annotation process of generating examples in AMBIENT
In addition, the issue of consistency of annotation results between different annotators is also discussed here, as well as AMBIENT The type of ambiguity present in the data set. The author randomly selected 100 samples in this data set as the development set, and the remaining samples were used as the test set. Figure 3 shows the distribution of set labels, and each sample has a corresponding inference relationship label. Research shows that in the case of ambiguity, the annotation results of multiple annotators are consistent, and using the joint results of multiple annotators can improve annotation accuracy.
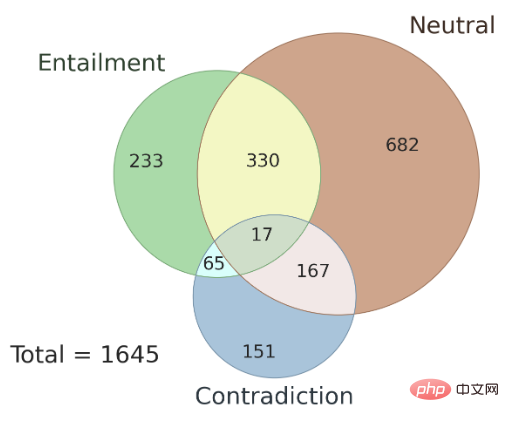
▲Figure 3 Distribution of collection labels in AMBIENT
Does ambiguity illustrate "disagree"?
This study analyzes the behavior of annotators when annotating ambiguous input under the traditional NLI three-way annotation scheme. The study found that annotators can be aware of ambiguity and that ambiguity is a major cause of labeling differences, thus challenging the popular assumption that "disagreement" is the source of uncertainty in simulated examples.
In the study, the AMBIENT data set was used and 9 crowdsourcing workers were hired to annotate each ambiguous example.
The task is divided into three steps:
- Annotate ambiguous examples
- Identify possible different interpretations
- Annotate disambiguated examples
Among them, in step 2, the three possible explanations include two possible meanings and a similar but not identical sentence. Finally, for each possible explanation, it is substituted into the original example to obtain three new NLI examples, and the annotator is asked to choose a label respectively.
The results of this experiment support the hypothesis: under a single labeling system, the original fuzzy examples will produce highly inconsistent results, that is, in the process of labeling sentences, people are prone to ambiguous sentences. Different judgments lead to inconsistent results. However, when a disambiguation step was added to the task, annotators were generally able to identify and verify multiple possibilities for a sentence, and the inconsistencies in the results were largely resolved. Therefore, disambiguation is an effective way to reduce the impact of annotator subjectivity on the results.
Evaluate the performance on large models
Q1. Can content related to disambiguation be directly generated
The focus of this part is to test the language model to directly generate disambiguation in context and the learning ability of the corresponding label. To this end, the authors built a natural cue and validated the model's performance using automatic and manual evaluation, as shown in Table 2.

▲Table 2 A few-shot template for generating disambiguation tasks when the premise is unclear
In the test, each example has 4 other test examples serve as context, and scores and correctness are calculated using the EDIT-F1 metric and human evaluation. The experimental results shown in Table 3 show that GPT-4 performed best in the test, achieving an EDIT-F1 score of 18.0% and a human evaluation accuracy of 32.0%. In addition, it has been observed that large models often adopt the strategy of adding additional context during disambiguation to directly confirm or deny hypotheses. However, it is important to note that human evaluation may overestimate the model's ability to accurately report sources of ambiguity.
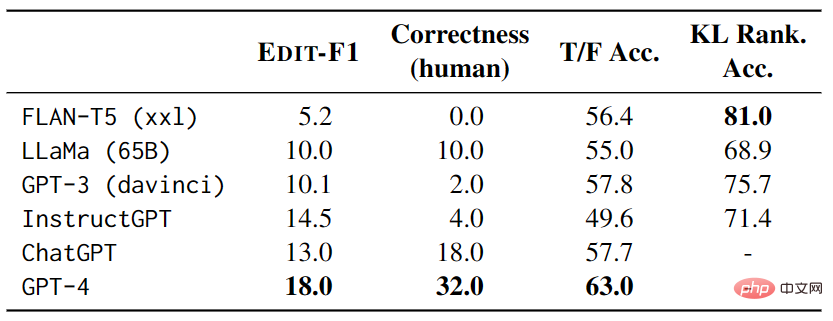
▲Table 3 Performance of large models on AMBIENT
Q2. Can the validity of reasonable explanations be identified?
This part mainly studies the performance of large models in identifying ambiguous sentences. By creating a series of templates of true and false statements and zero-shot testing the model, the researchers evaluated how well the large model performed in choosing predictions between true and false. Experimental results show that the best model is GPT-4, however, when ambiguity is taken into account, GPT-4 performs worse than random guessing in answering ambiguous interpretations of all four templates. In addition, large models have consistency problems in terms of questions. For different interpretation pairs of the same ambiguous sentence, the model may have internal contradictions.
These findings suggest that we need further research on how to improve the understanding of ambiguous sentences by large models and better evaluate the performance of large models.
Q3. Simulate open-ended continuous generation through different interpretations
This part mainly studies the ambiguity understanding ability based on language models. Language models are tested given context and compare their predictions of text continuation under different possible interpretations. In order to measure the model's ability to handle ambiguity, the researchers used KL divergence to measure the "surprise" of the model by comparing the probability and expectation differences produced by the model under a given ambiguity and a given correct context in the corresponding context. , and introduced "interference sentences" that randomly replace nouns to further test the model's ability.
The experimental results show that FLAN-T5 has the highest accuracy, but the performance results of different test suites (LS involves synonym replacement, PC involves correction of spelling errors, and SSD involves correction of grammatical structures) and different models are inconsistent, indicating that Ambiguity remains a serious challenge for models.
Multi-label NLI model experiment
As shown in Table 4, there is still much room for improvement in fine-tuning the NLI model on existing data with label changes, especially in multi-label NLI tasks. .
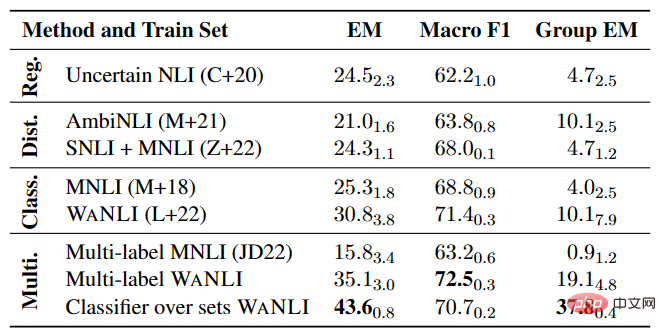
▲Table 4 Performance of multi-label NLI model on AMBIENT
Detecting misleading political speech
This experiment studied Different ways of understanding political speech demonstrate that models that are sensitive to different ways of understanding can be effectively exploited. The research results are shown in Table 5. For ambiguous sentences, some explanatory interpretations can naturally eliminate the ambiguity, because these interpretations can only retain the ambiguity or clearly express a specific meaning.
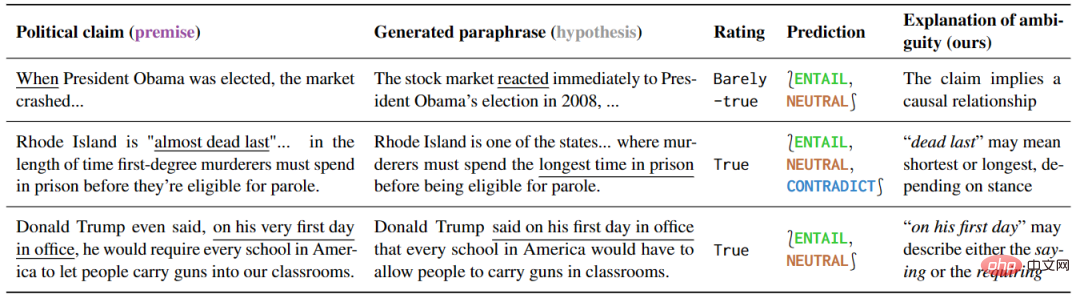
▲Table 5 The political speech marked as ambiguous by the detection method of this article
In addition, the interpretation of this prediction can reveal the source of the ambiguity. By further analyzing the results of false positives, the authors also found many ambiguities that were not mentioned in fact checks, illustrating the great potential of these tools in preventing misunderstandings.
Summary
As pointed out in this article, the ambiguity of natural language will be a key challenge in model optimization. We expect that in the future technological development, natural language understanding models will be able to more accurately identify the context and key points in texts, and show higher sensitivity when processing ambiguous texts. Although we have established a benchmark for evaluating natural language processing models for identifying ambiguity and are able to better understand the limitations of models in this domain, this remains a very challenging task.
Xi Xiaoyao Technology Talk Original
Author | IQ dropped all over the place, Python
The above is the detailed content of Latest research, GPT-4 exposes shortcomings! Can't quite understand the language ambiguity!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
In natural language generation tasks, sampling method is a technique to obtain text output from a generative model. This article will discuss 5 common methods and implement them using PyTorch. 1. GreedyDecoding In greedy decoding, the generative model predicts the words of the output sequence based on the input sequence time step by time. At each time step, the model calculates the conditional probability distribution of each word, and then selects the word with the highest conditional probability as the output of the current time step. This word becomes the input to the next time step, and the generation process continues until some termination condition is met, such as a sequence of a specified length or a special end marker. The characteristic of GreedyDecoding is that each time the current conditional probability is the best
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
Regarding Llama3, new test results have been released - the large model evaluation community LMSYS released a large model ranking list. Llama3 ranked fifth, and tied for first place with GPT-4 in the English category. The picture is different from other benchmarks. This list is based on one-on-one battles between models, and the evaluators from all over the network make their own propositions and scores. In the end, Llama3 ranked fifth on the list, followed by three different versions of GPT-4 and Claude3 Super Cup Opus. In the English single list, Llama3 overtook Claude and tied with GPT-4. Regarding this result, Meta’s chief scientist LeCun was very happy and forwarded the tweet and
 The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The volume is crazy, the volume is crazy, and the big model has changed again. Just now, the world's most powerful AI model changed hands overnight, and GPT-4 was pulled from the altar. Anthropic released the latest Claude3 series of models. One sentence evaluation: It really crushes GPT-4! In terms of multi-modal and language ability indicators, Claude3 wins. In Anthropic’s words, the Claude3 series models have set new industry benchmarks in reasoning, mathematics, coding, multi-language understanding and vision! Anthropic is a startup company formed by employees who "defected" from OpenAI due to different security concepts. Their products have repeatedly hit OpenAI hard. This time, Claude3 even had a big surgery.
 Jailbreak any large model in 20 steps! More 'grandma loopholes' are discovered automatically
Nov 05, 2023 pm 08:13 PM
Jailbreak any large model in 20 steps! More 'grandma loopholes' are discovered automatically
Nov 05, 2023 pm 08:13 PM
In less than a minute and no more than 20 steps, you can bypass security restrictions and successfully jailbreak a large model! And there is no need to know the internal details of the model - only two black box models need to interact, and the AI can fully automatically defeat the AI and speak dangerous content. I heard that the once-popular "Grandma Loophole" has been fixed: Now, facing the "Detective Loophole", "Adventurer Loophole" and "Writer Loophole", what response strategy should artificial intelligence adopt? After a wave of onslaught, GPT-4 couldn't stand it anymore, and directly said that it would poison the water supply system as long as... this or that. The key point is that this is just a small wave of vulnerabilities exposed by the University of Pennsylvania research team, and using their newly developed algorithm, AI can automatically generate various attack prompts. Researchers say this method is better than existing
 How to do basic natural language generation using PHP
Jun 22, 2023 am 11:05 AM
How to do basic natural language generation using PHP
Jun 22, 2023 am 11:05 AM
Natural language generation is an artificial intelligence technology that converts data into natural language text. In today's big data era, more and more businesses need to visualize or present data to users, and natural language generation is a very effective method. PHP is a very popular server-side scripting language that can be used to develop web applications. This article will briefly introduce how to use PHP for basic natural language generation. Introducing the natural language generation library The function library that comes with PHP does not include the functions required for natural language generation, so
 What ChatGPT and generative AI mean in digital transformation
May 15, 2023 am 10:19 AM
What ChatGPT and generative AI mean in digital transformation
May 15, 2023 am 10:19 AM
OpenAI, the company that developed ChatGPT, shows a case study conducted by Morgan Stanley on its website. The topic is "Morgan Stanley Wealth Management deploys GPT-4 to organize its vast knowledge base." The case study quotes Jeff McMillan, head of analytics, data and innovation at Morgan Stanley, as saying, "The model will be an internal-facing Powered by a chatbot that will conduct a comprehensive search of wealth management content and effectively unlock Morgan Stanley Wealth Management’s accumulated knowledge.” McMillan further emphasized: "With GPT-4, you basically immediately have the knowledge of the most knowledgeable person in wealth management... Think of it as our chief investment strategist, chief global economist
