

How to use python beautifulsoup4 module

1. Basic knowledge supplement of BeautifulSoup4
BeautifulSoup4 is a python parsing library, mainly used to parse HTML and XML. There will be more parsing of HTML in the crawler knowledge system,
The library installation command is as follows:
pip install beautifulsoup4
BeautifulSoup When parsing data, you need to rely on a third-party parser. Commonly used parsers and The advantages are as follows:
python standard library html.parser: python has a built-in standard library with strong fault tolerance;lxml parser: fast, fault-tolerant;html5lib: the most fault-tolerant, parsing method and browsing The device is consistent.
Next, use a custom HTML code to demonstrate the basic use of the beautifulsoup4 library. The test code is as follows:
<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2>
<p>用一段自定义的 HTML 代码来演示</p>
</body>
</html>Use BeautifulSoup Perform simple operations on it, including instantiating BS objects, outputting page tags, etc.
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) # 输入网页标题 title 标签 print(soup.title) # 输入网页 head 标签 print(soup.head) # 测试输入段落标签 p print(soup.p) # 默认获取第一个
We can directly call the web page tag through the BeautifulSoup object. There is a problem here. Calling the tag through the BS object can only get the tag ranked first. As in the above code, only one is obtained p tag, if you want to get more content, please continue reading.
To learn this, we need to understand the 4 built-in objects in BeautifulSoup:
BeautifulSoup: basic object, The entire HTML object can generally be viewed as a Tag object;Tag: tag object, tags are each node in the web page, such as title, head, p;NavigableString: tag internal string;Comment: comment object, inside the crawler There are not many usage scenarios.
The following code demonstrates for you the scenarios in which these objects appear. Pay attention to the relevant comments in the code:
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") # 上述是将字符串格式化为 Beautiful Soup 对象,你可以从一个文件进行格式化 # soup = BeautifulSoup(open('test.html')) print(soup) print(type(soup)) # <class 'bs4.BeautifulSoup'> # 输入网页标题 title 标签 print(soup.title) print(type(soup.title)) # <class 'bs4.element.Tag'> print(type(soup.title.string)) # <class 'bs4.element.NavigableString'> # 输入网页 head 标签 print(soup.head)
For Tag object has two important attributes, which are name and attrs
from bs4 import BeautifulSoup text_str = """<html> <head> <title>测试bs4模块脚本</title> </head> <body> <h2 id="橡皮擦的爬虫课">橡皮擦的爬虫课</h2> <p>用1段自定义的 HTML 代码来演示</p> <p>用2段自定义的 HTML 代码来演示</p> <a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a> </body> </html> """ # 实例化 Beautiful Soup 对象 soup = BeautifulSoup(text_str, "html.parser") print(soup.name) # [document] print(soup.title.name) # 获取标签名 title print(soup.html.body.a) # 可以通过标签层级获取下层标签 print(soup.body.a) # html 作为一个特殊的根标签,可以省略 print(soup.p.a) # 无法获取到 a 标签 print(soup.a.attrs) # 获取属性
The above code demonstrates obtaining Usage of name attribute and attrs attribute. The attrs attribute is a dictionary, and the corresponding value can be obtained by key.
Get the attribute value of the tag. In BeautifulSoup, you can also use the following method:
print(soup.a["href"])
print(soup.a.get("href"))Get NavigableString Object After getting the web page tag, To get the text within the label, use the following code.
print(soup.a.string)
In addition, you can also use the text attribute and the get_text() method to get the tag content.
print(soup.a.string) print(soup.a.text) print(soup.a.get_text())
You can also get all the text in the tag by using strings and stripped_strings.
print(list(soup.body.strings)) # 获取到空格或者换行 print(list(soup.body.stripped_strings)) # 去除空格或者换行
Extended tag/node selector to traverse the document tree
Direct child node
The direct child element of the tag (Tag) object can be used contents and children attributes are obtained.
from bs4 import BeautifulSoup
text_str = """<html>
<head>
<title>测试bs4模块脚本</title>
</head>
<body>
<div id="content">
<h2 id="橡皮擦的爬虫课-span-最棒-span">橡皮擦的爬虫课<span>最棒</span></h2>
<p>用1段自定义的 HTML 代码来演示</p>
<p>用2段自定义的 HTML 代码来演示</p>
<a href="http://www.csdn.net" rel="external nofollow" rel="external nofollow" >CSDN 网站</a>
</div>
<ul class="nav">
<li>首页</li>
<li>博客</li>
<li>专栏课程</li>
</ul>
</body>
</html>
"""
# 实例化 Beautiful Soup 对象
soup = BeautifulSoup(text_str, "html.parser")
# contents 属性获取节点的直接子节点,以列表的形式返回内容
print(soup.div.contents) # 返回列表
# children 属性获取的也是节点的直接子节点,以生成器的类型返回
print(soup.div.children) # 返回 <list_iterator object at 0x00000111EE9B6340> Please note that the above two attributes obtain direct child nodes, such as the descendant tag span within the h2 tag, which will not obtained separately.
If you want to get all tags, use the descendants attribute, which returns a generator, and all tags including the text within the tags will be fetched separately.
print(list(soup.div.descendants))
Acquisition of other nodes (just understand it, check it and use it immediately)
parentandparents: directly Parent node and all parent nodes;next_sibling,next_siblings,previous_sibling,previous_siblings: Represents the next sibling node, all sibling nodes below, the previous sibling node, and all sibling nodes above. Since the newline character is also a node, when using these attributes, pay attention to the newline character;next_element,next_elements,previous_element,previous_elements: These attributes represent the previous node or the next node respectively. A node, note that they are not hierarchical, but for all nodes. For example, the next node of thedivnode in the above code ish2, and thedivnode The sibling node isul.
Document tree search related functions
The first function to learn is the find_all() function, The prototype is as follows:
find_all(name,attrs,recursive,text,limit=None,**kwargs)
name: This parameter is the name of the tag tag, for examplefind_all('p')is to find allptags, and can accept tag name strings, regular expressions and lists;attrs:传入的属性,该参数可以字典的形式传入,例如attrs={'class': 'nav'},返回的结果是 tag 类型的列表;
上述两个参数的用法示例如下:
print(soup.find_all('li')) # 获取所有的 li
print(soup.find_all(attrs={'class': 'nav'})) # 传入 attrs 属性
print(soup.find_all(re.compile("p"))) # 传递正则,实测效果不理想
print(soup.find_all(['a','p'])) # 传递列表recursive:调用find_all ()方法时,BeautifulSoup 会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数recursive=False,测试代码如下:
print(soup.body.div.find_all(['a','p'],recursive=False)) # 传递列表
text:可以检索文档中的文本字符串内容,与name参数的可选值一样,text参数接受标签名字符串、正则表达式、 列表;
print(soup.find_all(text='首页')) # ['首页']
print(soup.find_all(text=re.compile("^首"))) # ['首页']
print(soup.find_all(text=["首页",re.compile('课')])) # ['橡皮擦的爬虫课', '首页', '专栏课程']limit:可以用来限制返回结果的数量;kwargs:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作 tag 的属性来搜索。这里要按class属性搜索,因为class是 python 的保留字,需要写作class_,按class_查找时,只要一个 CSS 类名满足即可,如需多个 CSS 名称,填写顺序需要与标签一致。
print(soup.find_all(class_ = 'nav')) print(soup.find_all(class_ = 'nav li'))
还需要注意网页节点中,有些属性在搜索中不能作为kwargs参数使用,比如html5 中的 data-*属性,需要通过attrs参数进行匹配。
与
find_all()方法用户基本一致的其它方法清单如下:
find():函数原型find( name , attrs , recursive , text , **kwargs ),返回一个匹配元素;find_parents(),find_parent():函数原型find_parent(self, name=None, attrs={}, **kwargs),返回当前节点的父级节点;find_next_siblings(),find_next_sibling():函数原型find_next_sibling(self, name=None, attrs={}, text=None, **kwargs),返回当前节点的下一兄弟节点;find_previous_siblings(),find_previous_sibling():同上,返回当前的节点的上一兄弟节点;find_all_next(),find_next(),find_all_previous () ,find_previous ():函数原型find_all_next(self, name=None, attrs={}, text=None, limit=None, **kwargs),检索当前节点的后代节点。
CSS 选择器 该小节的知识点与pyquery有点撞车,核心使用select()方法即可实现,返回数据是列表元组。
通过标签名查找,
soup.select("title");通过类名查找,
soup.select(".nav");通过 id 名查找,
soup.select("#content");通过组合查找,
soup.select("div#content");通过属性查找,
soup.select("div[id='content'"),soup.select("a[href]");
在通过属性查找时,还有一些技巧可以使用,例如:
^=:可以获取以 XX 开头的节点:
print(soup.select('ul[class^="na"]'))
*=:获取属性包含指定字符的节点:
print(soup.select('ul[class*="li"]'))
二、爬虫案例
BeautifulSoup 的基础知识掌握之后,在进行爬虫案例的编写,就非常简单了,本次要采集的目标网站 ,该目标网站有大量的艺术二维码,可以供设计大哥做参考。
下述应用到了 BeautifulSoup 模块的标签检索与属性检索,完整代码如下:
from bs4 import BeautifulSoup
import requests
import logging
logging.basicConfig(level=logging.NOTSET)
def get_html(url, headers) -> None:
try:
res = requests.get(url=url, headers=headers, timeout=3)
except Exception as e:
logging.debug("采集异常", e)
if res is not None:
html_str = res.text
soup = BeautifulSoup(html_str, "html.parser")
imgs = soup.find_all(attrs={'class': 'lazy'})
print("获取到的数据量是", len(imgs))
datas = []
for item in imgs:
name = item.get('alt')
src = item["src"]
logging.info(f"{name},{src}")
# 获取拼接数据
datas.append((name, src))
save(datas, headers)
def save(datas, headers) -> None:
if datas is not None:
for item in datas:
try:
# 抓取图片
res = requests.get(url=item[1], headers=headers, timeout=5)
except Exception as e:
logging.debug(e)
if res is not None:
img_data = res.content
with open("./imgs/{}.jpg".format(item[0]), "wb+") as f:
f.write(img_data)
else:
return None
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
url_format = "http://www.9thws.com/#p{}"
urls = [url_format.format(i) for i in range(1, 2)]
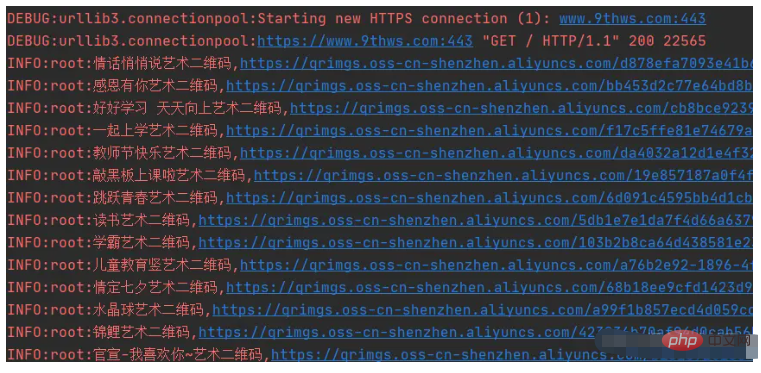
get_html(urls[0], headers)本次代码测试输出采用的 logging 模块实现,效果如下图所示。 测试仅采集了 1 页数据,如需扩大采集范围,只需要修改 main 函数内页码规则即可。 ==代码编写过程中,发现数据请求是类型是 POST,数据返回格式是 JSON,所以本案例仅作为 BeautifulSoup 的上手案例吧==
The above is the detailed content of How to use python beautifulsoup4 module. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Regarding the problem of removing the Python interpreter that comes with Linux systems, many Linux distributions will preinstall the Python interpreter when installed, and it does not use the package manager...
 How to solve the problem of Pylance type detection of custom decorators in Python?
Apr 02, 2025 am 06:42 AM
How to solve the problem of Pylance type detection of custom decorators in Python?
Apr 02, 2025 am 06:42 AM
Pylance type detection problem solution when using custom decorator In Python programming, decorator is a powerful tool that can be used to add rows...
 Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
About Pythonasyncio...
 How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
Using python in Linux terminal...
 Python 3.6 loading pickle file error ModuleNotFoundError: What should I do if I load pickle file '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 loading pickle file error ModuleNotFoundError: What should I do if I load pickle file '__builtin__'?
Apr 02, 2025 am 06:27 AM
Loading pickle file in Python 3.6 environment error: ModuleNotFoundError:Nomodulenamed...
 Do FastAPI and aiohttp share the same global event loop?
Apr 02, 2025 am 06:12 AM
Do FastAPI and aiohttp share the same global event loop?
Apr 02, 2025 am 06:12 AM
Compatibility issues between Python asynchronous libraries In Python, asynchronous programming has become the process of high concurrency and I/O...
 What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?
Apr 02, 2025 am 07:12 AM
What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?
Apr 02, 2025 am 07:12 AM
Error loading Pickle file in Python 3.6 environment: ModuleNotFoundError:Nomodulenamed...
 How to ensure that the child process also terminates after killing the parent process via signal in Python?
Apr 02, 2025 am 06:39 AM
How to ensure that the child process also terminates after killing the parent process via signal in Python?
Apr 02, 2025 am 06:39 AM
The problem and solution of the child process continuing to run when using signals to kill the parent process. In Python programming, after killing the parent process through signals, the child process still...
