
 Backend Development
Python Tutorial
Analysis of common grammar examples of Python regular expressions
Backend Development
Python Tutorial
Analysis of common grammar examples of Python regular expressions
Analysis of common grammar examples of Python regular expressions

Regular Expression Overview
A regular expression is a special sequence of characters that can help you easily check whether a string matches a certain pattern. Python has added the re module since version 1.5, which provides Perl-style regular expression patterns. The re module brings full regular expression functionality to the Python language. Regular expression is a powerful character processing tool. Its essence is a character sequence, which can easily check whether a string matches a certain pattern of the character sequence we define.
In python, regular expression It can be used through the import re module. This article will comprehensively introduce the use of regular expressions.
The ordinary characters written in the regular expressions all mean: match them directly;
But there are some special Characters, term metacharacters. They appear in regular expression strings, not to match them directly, but to express some special meanings
These special metacharacters include the following:
. * ? \ [ ] ^ $ { } | ( )
Let’s introduce their meanings respectively:
1. Dot - matches all characters
. Indicates that you want Matches any single character except a newline character
For example, you want to select all colors from the following text.
Apples are green
Oranges are orange
Banana is yellow
Crows are black
That is, to find all Israeli colors A word that ends with and includes the preceding character. You can also write a regular expression like this. The color
where the dot represents any character, please note that it is any character.
. The combination of color means to find any character followed by the word color, and the string of two words combined
Example:
# 导入re模块
import re
#输入文本内容
content='''苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的'''
p=re.compile(r'.色')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)
2. Asterisk - Repeat matching any number of times
* - Indicates matching the previous subexpression any number of times, including 0 times
For example, you want to select each line from the following text The content of the string after the comma, including the comma itself. Note that the comma here is the text comma.
Apples are green
Oranges are orange
Banana are yellow
Crows are black
Monkeys
You can write regular expressions like this, .*.
Example:
# 导入re模块
import re
#输入文本内容
content='''苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,'''
p=re.compile(r',.*')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)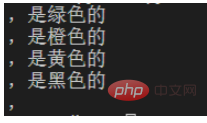
In this way, all subsequent strings including commas are matched
3. Plus sign- Repeat matching multiple times
means matching the previous subexpression one or more times, excluding 0 times
For example, still in the above example, you have to select the following subexpression from the text. String, including the comma itself. But add a condition, if there is no content after the comma, don't select it.
There is no content after the comma in the last line of the text below, so don’t select it
Apple is green
Orange is orange
Banana is yellow The
crow is a black
monkey,
you can write the regular expression like this,.
Example:
# 导入re模块
import re
#输入文本内容
content='''苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,'''
p=re.compile(r',.+')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)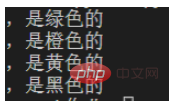
There is no content after the comma in the last line, so the last line will not match
4. Curly brackets - match the specified number of times
The curly brackets indicate that the previous characters match the specified number The number of times
For example, the following text
red, green, black, green
expression oil{3,4} is Indicates matching consecutive oil characters at least 3 times and at most 4 times
Example:
# 导入re模块
import re
#输入文本内容
content='''红彤彤,绿油油,黑乎乎,绿油油油油'''
p=re.compile(r'绿油{3,4}')#r表示不要进行python语法中对字符串的转译
for one in p.findall(content):
print(one)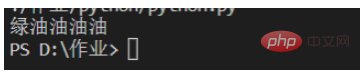
Here, match green followed by oil at least 3 times and at most 4 times Times string
5, question mark-greedy mode and non-greedy mode
We need to extract all html tags in the following string

Get such a list

# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))

为了解决整个问题,就需要使用非贪婪模式,也就是在星号后面加上?,变成这样<.*?>
代码改为
# 导入re模块 import re #输入文本内容 source='<html><head><title>Title</title>' p=re.compile(r'<.*?>')#r表示不要进行python语法中对字符串的转译 print(p.findall(source))

这样就单独去匹配出来了每一个标签
6、方括号-匹配几个字符之一
方括号表示要匹配某几种类型字符。
比如
[abc]可以匹配a,b,c里面的任意一个字符。等价于[a-c]
a-c中间的-表示一个范围从a到c
如果你想匹配所有小写字母,可以使用[a-z]
一些元字符在方括号内便失去了魔法,变得和普通字符一样了。
比如
[akm.]匹配a k m .里面的任意一个字符
在这里. 在括号不再表示匹配任意字符了,而就是表示匹配.这个字符
例如:
| 实例 | 描述 |
|---|---|
| [pP]ython | 匹配“Python”或者“python” |
| rub[ye] | 匹配“ruby”或者“rube” |
7、起始位置和单行、多行模式
^表示匹配文本的起始位置
正则表达式可以设定单行模式和多行模式
如果是单行模式,表示匹配整个文本的开头位置。
如果是多行模式,表示匹配文本每行的开头位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
范例:
# 导入re模块
import re
#输入文本内容
source='''001-苹果-60
002-橙子-70
003-香蕉-80'''
p=re.compile(r'^\d+')#r表示不要进行python语法中对字符串的转译
for one in p.findall(source):
print(one)运行结果如下

如果去掉complie的第二个参数re.M,运行结果如下

就只进行一行匹配,
因为在单行模式下,^只会匹配整个文本的开头位置
$表示匹配文本的结束位置
如果是单行模式,表示匹配整个文本的结束位置。
如果是多行模式,表示匹配文本每行的结束位置。
比如,下面的文本中,每行最前面的数字表示水果的编号,最后的数字表示价格
001-苹果价格-60,
002-橙子价格-70,
003-香蕉价格-80,
如果我们要提取所有的水果编号,用这样的正则表达式\d+$
范例:
# 导入re模块
import re
#输入文本内容
source='''001-苹果-60
002-橙子-70
003-香蕉-80'''
p=re.compile(r'^\d+$',re.M)#re.M进行多行匹配
for one in p.findall(source):
print(one)
成功匹配到每行最后的价格
8、括号-组选择
主括号称之为正则表达式的组选择。是从正则表达式匹配的内容里面扣取出其中的某些部分
前面,我们有个例子,从下面的文本中,选择每行逗号前面的字符串,也包括逗号本身。
苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的
就可以这样写正则表达式个^.*,。
但是,如果我们要求不要包括逗号呢?
当然不能直接这样写^.*
因为最后的逗号是特征所在,如果去掉它,就没法找逗号前面的了。
但是把逗号放在正则表达式中,又会包含逗号。
解决问题的方法就是使用组选择符:括号。
我们这样写^(.*),
我们把要从整个表达式中提取的部分放在括号中,这样水果的名字就被单独的放在组group中了。
对应的Python代码如下
# 导入re模块
import re
#输入文本内容
source='''苹果,苹果是绿色的
橙子,橙子是橙色的
香蕉,香蕉是黄色的'''
p=re.compile(r'^(.*),',re.M)#re.M进行多行匹配
for one in p.findall(source):
print(one)
这样我们就可以把,前的字符取出来了
9、反斜杠-对元字符的转义
反斜杠\在正则表达式中有多种用途
比如,我们要在下面的文本中搜索所有点前面的字符串,也包括点本身
苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的
如果,我们这样写正则表达式.*.,聪明的你肯定发现不对劲。
因为点是一个元字符,直接出现在正则表达式中,表示匹配任意的单个字符,不能表示.这个字符的本身的意思了
怎么办呢?
如果我们要搜索的内容本身就包含元字符,就可以使用反斜杠进行转义
这里我们就应用这样的表达式.*\.
范例:
# 导入re模块
import re
#输入文本内容
source='''苹果.是绿色的
橙子.是橙色的
香蕉.是黄色的'''
p=re.compile(r'.*\.')#r表示不要进行python语法中对字符串的转译
for one in p.findall(source):
print(one)
成功匹配!
利用反斜杠还可以匹配某种字符类型
反斜杠后面接一些字符,表示匹配某种类型的一个字符
| 字符 | 功能 |
|---|---|
| \d | 匹配0~9之间的任意一个数字字符,等价于表达式[0-9] |
| \D | 匹配任意一个不上0-9之间的数字字符,等价于表达是[^0-9] |
| \s | 匹配任意一个空白字符,包括空格、tab、换行符等、等价于[\t\n\r\f\v] |
| \S | 匹配任意一个非空白字符,等价于[^\t\tn\r\f\v] |
| \w | 匹配任意一个文字字符,包括大小写、数字、下划线、等于[a-zA-A0-9] |
| \W | 匹配任意一个非文字字符,等价于表达式[^a-zA-Z0-9] |
反斜杠也可以用在方括号里面,比如[\s,.]:表示匹配任何空白字符,或者逗号,或者点
10、修饰符-可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(I)它们来指定。如re.l | re.M被设置成Ⅰ和M标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响lw,W,Nb,\B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
11、使用正则表达式切割字符串
字符串对象的split()方法只适应于非常简单的字符串分割情形。当你需要更加灵活的切割字符串的时候,就不好用了。
比如,我们需要从下面字符串中提取武将的名字。
我们发现这些名字之间,有的是分号隔开,有的是逗号隔开,有的是空格隔开,而且分割符号周围还有不定数量的空格
names =“关羽;张飞,赵云,马超,黄忠 李逵”
这时,最好使用正则表达式里面的split方法:
范例:
# 导入re模块 import re #输入文本内容 names ="关羽;张飞,赵云,马超,黄忠 李逵" namelist=re.split(r'[;,\s]\s*',names) print(namelist)

正则表达式[;,ls]\s*指定了,分割符为分号、逗号、空格里面的任意一种均可,并且该符号周围可以有不定数量的空格。
The above is the detailed content of Analysis of common grammar examples of Python regular expressions. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1384
1384
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MiniOpen Centos compatibility
Apr 14, 2025 pm 05:45 PM
MinIO Object Storage: High-performance deployment under CentOS system MinIO is a high-performance, distributed object storage system developed based on the Go language, compatible with AmazonS3. It supports a variety of client languages, including Java, Python, JavaScript, and Go. This article will briefly introduce the installation and compatibility of MinIO on CentOS systems. CentOS version compatibility MinIO has been verified on multiple CentOS versions, including but not limited to: CentOS7.9: Provides a complete installation guide covering cluster configuration, environment preparation, configuration file settings, disk partitioning, and MinI
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
How to choose the PyTorch version on CentOS
Apr 14, 2025 pm 06:51 PM
When installing PyTorch on CentOS system, you need to carefully select the appropriate version and consider the following key factors: 1. System environment compatibility: Operating system: It is recommended to use CentOS7 or higher. CUDA and cuDNN:PyTorch version and CUDA version are closely related. For example, PyTorch1.9.0 requires CUDA11.1, while PyTorch2.0.1 requires CUDA11.3. The cuDNN version must also match the CUDA version. Before selecting the PyTorch version, be sure to confirm that compatible CUDA and cuDNN versions have been installed. Python version: PyTorch official branch
 How to update PyTorch to the latest version on CentOS
Apr 14, 2025 pm 06:15 PM
How to update PyTorch to the latest version on CentOS
Apr 14, 2025 pm 06:15 PM
Updating PyTorch to the latest version on CentOS can follow the following steps: Method 1: Updating pip with pip: First make sure your pip is the latest version, because older versions of pip may not be able to properly install the latest version of PyTorch. pipinstall--upgradepip uninstalls old version of PyTorch (if installed): pipuninstalltorchtorchvisiontorchaudio installation latest
