

It only takes 12 seconds to use Stable Diffusion to generate an image using only the computing power of the mobile phone.
And it’s the kind that has completed 20 iterations.

You must know that current diffusion models basically exceed 1 billion parameters. If you want to quickly generate a picture, you must either rely on cloud computing or the local hardware must be powerful enough. .
As large model applications gradually become more popular, running large models on personal computers and mobile phones is likely to be a new trend in the future.
As a result, Google researchers have brought this new result, called Speed is all you need: Accelerate the inference speed of large-scale diffusion models on devices through GPU optimization .

This method is optimized for Stable Diffusion, but it can also be adapted to other diffusion models. The task is to generate images from text.
Specific optimization can be divided into three parts:
First look at the specially designed kernel, which includes group normalization and GELU activation functions.
Group normalization is implemented throughout the UNet architecture. The working principle of this normalization is to divide the channels of feature mapping into smaller groups and normalize each group independently, so that Group normalization is less dependent on batch size and can adapt to a wider range of batch sizes and network architectures.
The researchers designed a unique kernel in the form of a GPU shader that can execute all kernels in a single GPU command without any intermediate tensors.
The GELU activation function contains a large number of numerical calculations, such as penalties, Gaussian error functions, etc.
A dedicated shader is used to integrate these numerical calculations and the accompanying division and multiplication operations, so that these calculations can be placed in a simple draw call.
Draw call is an operation in which the CPU calls the image programming interface and instructs the GPU to render.
Next, when it comes to improving the efficiency of the Attention model, the paper introduces two optimization methods.
One is the partial fusion of the softmax function.
In order to avoid performing the entire softmax calculation on the large matrix A, this study designed a GPU shader to calculate the L and S vectors to reduce calculations, ultimately resulting in a tensor of size N×2. Then the softmax calculation and matrix multiplication of matrix V are merged.
This method significantly reduces the memory footprint and overall latency of the intermediate program.
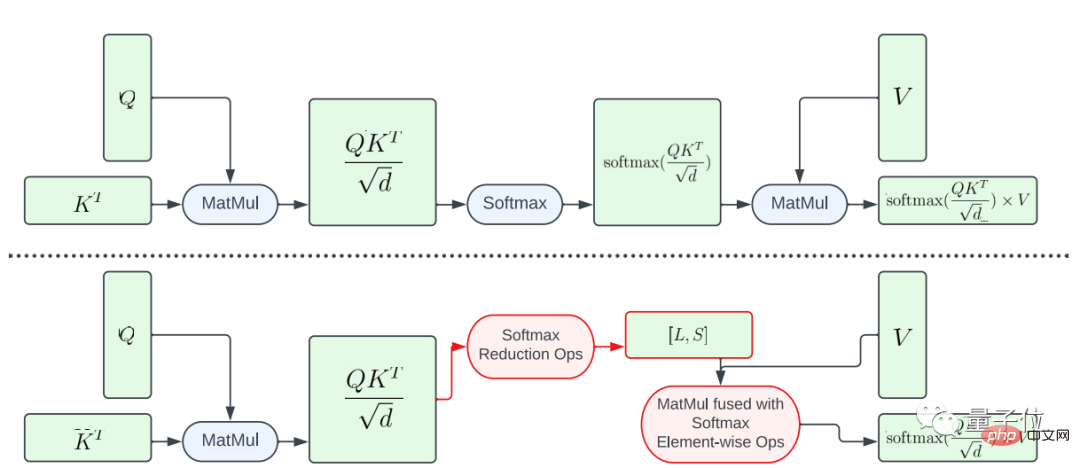
It should be emphasized that the parallelism of the computational mapping from A to L and S is limited because the number of elements in the result tensor is smaller than the number of elements in the input tensor A Much more.
In order to increase parallelism and further reduce latency, this study organized the elements in A into blocks and divided the reduction operations into multiple parts.
The calculation is then performed on each block and then reduced to the final result.
Using carefully designed threading and memory cache management, lower latency can be achieved in multiple parts using a single GPU command.
Another optimization method is FlashAttention.
This is the IO-aware precise attention algorithm that became popular last year. There are two specific acceleration technologies: incremental calculation in blocks, that is, tiling, and recalculating attention in backward pass to operate all attention Integrated into CUDA kernel.
Compared with standard Attention, this method can reduce HBM (high bandwidth memory) access and improve overall efficiency.
However, the FlashAttention core is very register-intensive, so the team uses this optimization method selectively.
They use FlashAttention on Adreno GPU and Apple GPU with attention matrix d=40, and use partial fusion softmax function in other cases.
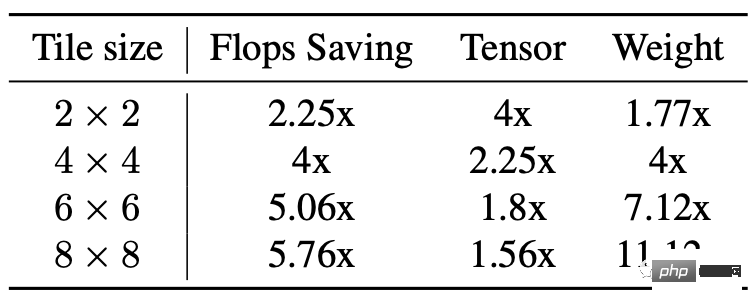
The third part is Winograd convolution acceleration.
Its principle is simply to use more addition calculations to reduce multiplication calculations, thereby reducing the amount of calculations.
But the disadvantages are also obvious, which will bring more video memory consumption and numerical errors, especially when the tile is relatively large.
The backbone of Stable Diffusion relies heavily on 3×3 convolutional layers, especially in the image decoder, where 90% of the layers are composed of 3×3 convolutional layers.
After analysis, researchers found that when using 4×4 tiles, it is the best balance point between model calculation efficiency and video memory utilization.
In order to evaluate the improvement effect, the researchers first conducted a benchmark test on a mobile phone.
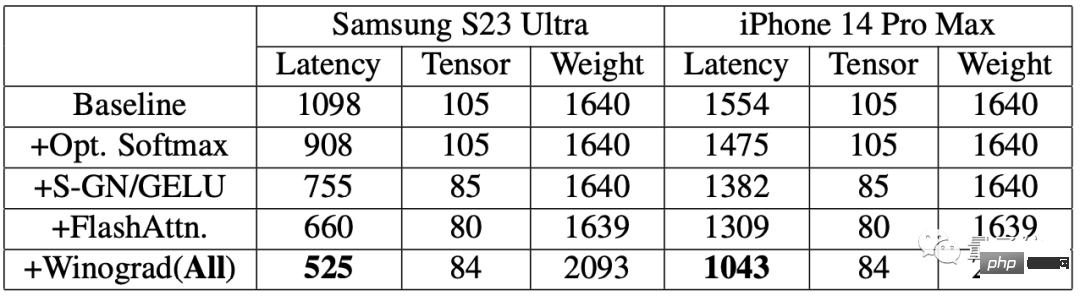
#The results show that after using the acceleration algorithm, the speed of image generation on both phones has been significantly improved.
Among them, the delay on Samsung S23 Ultra was reduced by 52.2%, and the delay on iPhone 14 Pro Max was reduced by 32.9%.
Generate a 512×512 pixel image from text end-to-end on Samsung S23 Ultra, with 20 iterations and taking less than 12 seconds.
Paper address: https://www.php.cn/link/ba825ea8a40c385c33407ebe566fa1bc
The above is the detailed content of AI completes painting on mobile phone within 12 seconds! Google proposes new method to accelerate diffusion model inference. For more information, please follow other related articles on the PHP Chinese website!
 Mobile phone root
Mobile phone root
 Projector mobile phone
Projector mobile phone
 The phone cannot connect to the Bluetooth headset
The phone cannot connect to the Bluetooth headset
 Why does my phone keep restarting?
Why does my phone keep restarting?
 The difference between official replacement phone and brand new phone
The difference between official replacement phone and brand new phone
 Why does my phone keep restarting?
Why does my phone keep restarting?
 Why can't my mobile phone make calls but not surf the Internet?
Why can't my mobile phone make calls but not surf the Internet?
 Why is my phone not turned off but when someone calls me it prompts me to turn it off?
Why is my phone not turned off but when someone calls me it prompts me to turn it off?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



