


Let's go!
We use the parameter adjustment process in machine learning to practice. There are three ways to choose from. The first option is to use argparse, which is a popular Python module dedicated to command line parsing; the other is to read a JSON file where we can put all the hyperparameters; the third is also less known The solution is to use YAML files! Curious, let’s get started!
In the code below, I will use Visual Studio Code, which is a very efficient integrated Python development environment. The beauty of this tool is that it supports every programming language by installing extensions, integrates the terminal and allows working with a large number of Python scripts and Jupyter notebooks simultaneously.
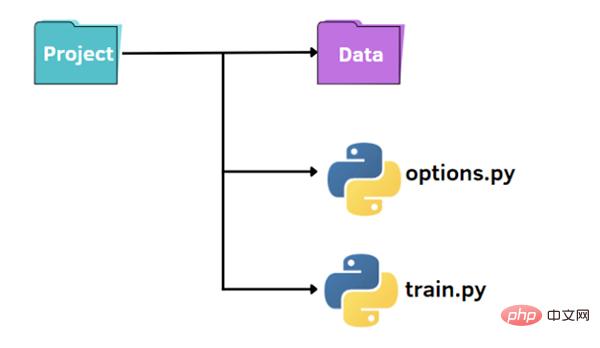
As shown in the picture above, we have a standard structure to organize our small project:
First, we can create a file train.py in which we have the imported data, the training data Basic procedure for training a model and evaluating it on the test set:
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('datahour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)In the code, we also imported the train_options function contained in the options.py file. The latter file is a Python file from which we can change the hyperparameters considered in train.py:
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optIn this example, we use the argparse library, which is very popular when parsing command line arguments. First, we initialize the parser, then, we can add the parameters we want to access.
Here is an example of running code:
python train.py

To change the default values of hyperparameters, there are two ways. The first option is to set different default values in the options.py file. Another option is to pass the hyperparameter value from the command line:
python train.py --n_estimators 200
We need to specify the name of the hyperparameter we want to change and the corresponding value.
python train.py --n_estimators 200 --max_depth 7
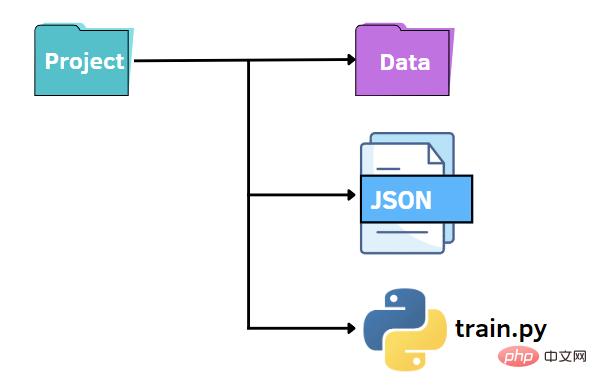
As before, we can keep a similar file structure. In this case, we replace the options.py file with a JSON file. In other words, we want to specify the values of the hyperparameters in a JSON file and pass them to the train.py file. JSON files can be a fast and intuitive alternative to the argparse library, leveraging key-value pairs to store data. Next we create an options.json file that contains the data we need to pass to other code later.
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}As you can see above, it is very similar to a Python dictionary. But unlike a dictionary, it contains data in text/string format. Additionally, there are some common data types with slightly different syntax. For example, Boolean values are false/true, while Python recognizes False/True. Other possible values in JSON are arrays, which are represented as Python lists using square brackets.
The beauty of working with JSON data in Python is that it can be converted into a Python dictionary via the load method:
f = open("options.json", "rb")
parameters = json.load(f)To access a specific item, we just need to quote it within square brackets Key name:
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
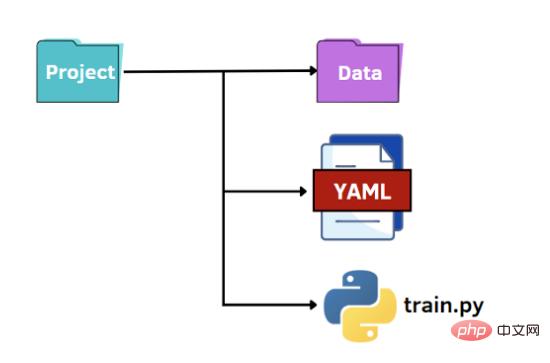
The last option is to take advantage of the potential of YAML. As with JSON files, we read the YAML file in Python code as a dictionary to access the values of the hyperparameters. YAML is a human-readable data representation language in which hierarchies are represented using double-space characters instead of parentheses like in JSON files. Below we show what the options.yaml file will contain:
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
In train.py, we open the options.yaml file, which will always be converted to a Python dictionary using the load method, this time from the yaml library Imported in:
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)As before, we can access the value of the hyperparameter using the syntax required by the dictionary.
Configuration files compile very quickly, whereas argparse requires writing a line of code for each argument we want to add.
So we should choose the most appropriate method according to our different situations
For example, if we need to add comments to parameters, JSON is not suitable because it does not allow comments, and YAML and argparse might be a good fit.
The above is the detailed content of Three ways to parse parameters in Python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



