

How SpringBoot uses Caffeine to implement caching

Why add caching to your application
Before diving into how to add caching to your application, the first question that comes to mind is why we need to use caching in our application.
Suppose there is an application containing customer data, and the user makes two requests to get the customer's data (id=100).
This is what happens when there is no cache.
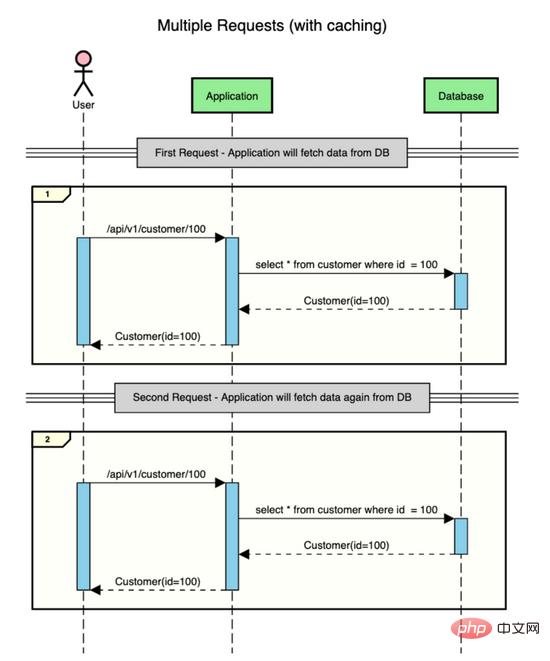
#As you can see, for every request, the application goes to the database to get the data. Getting data from the database is a costly operation as it involves IO.
However, if there is a cache store in the middle where the data can be temporarily stored for a short period of time, these round trips can be saved to the database and saved at IO time.
This is what the above interaction looks like when using caching.
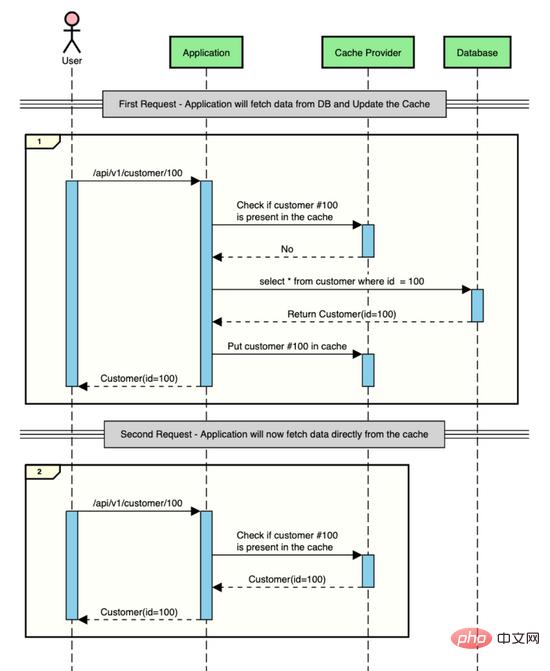
Implementing Caching in Spring Boot Applications
What caching support does SpringBoot provide?
SpringBoot only provides a cache abstraction that you can use to transparently and easily add cache to your Spring application.
It does not provide actual cache storage.
However, it can work with different types of cache providers such as Ehcache, Hazelcast, Redis, Caffee, etc.
SpringBoot's caching abstraction can be added to methods (using annotations)
Basically, the Spring framework will check the method before executing it Is the data already cached?
If yes, then it will get the data from cache.
Otherwise it will execute the method and cache the data
It also provides an abstraction to update or delete data from the cache.
In our current blog, we will learn how to add caching using Caffeine, a high-performance, near-optimal caching library based on Java 8.
You can specify which cache provider to use in the application.yaml file by setting the spring.cache.type property.
However, if no attribute is provided, Spring will automatically detect the cache provider based on the added library.
Add Build Dependencies
Now assuming you have a basic Spring boot application up and running, let’s add the cache dependency.
Open the build.gradle file and add the following dependencies to enable Spring Boot’s cache
compile('org.springframework.boot:spring-boot-starter-cache')
Next we will add a dependency on Caffeine
compile group: 'com.github.ben-manes.caffeine', name: 'caffeine', version: '2.8.5'
Cache Configuration
Now we need to enable caching in the Spring Boot application.
To do this, we need to create a configuration class and provide the annotation @EnableCaching.
@Configuration
@EnableCaching
public class CacheConfig {
}Right now this class is an empty class, but we can add more configuration to it if needed.
Now that we have enabled the cache, let’s provide the cache name and configuration of the cache properties such as cache size, cache expiration time, etc.
The easiest way to do this is in application.yaml Add configuration in
spring:
cache:
cache-names: customers, users, roles
caffeine:
spec: maximumSize=500, expireAfterAccess=60sThe above configuration performs the following operations
Limits the available cache names to customers, users, and roles. Set the maximum cache size to 500.
When the number of objects in the cache reaches this limit, the objects will be removed from the cache according to the cache eviction policy. Set the cache expiration time to 1 minute.
This means that items will be removed from the cache 1 minute after being added to the cache.
There is another way to configure the cache instead of configuring the cache in the application.yaml file.
You can add and provide a CacheManager Bean in the cache configuration class, which can complete the exact same job as the above configuration in application.yaml
@Bean
public CacheManager cacheManager() {
Caffeine<Object, Object> caffeineCacheBuilder =
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterAccess(
1, TimeUnit.MINUTES);
CaffeineCacheManager cacheManager =
new CaffeineCacheManager(
"customers", "roles", "users");
cacheManager.setCaffeine(caffeineCacheBuilder);
return cacheManager;
}In our code examples, we will use Java configuration.
We can do more things in Java, such as configuring RemovalListener to be executed when an item is removed from the cache, or enabling cache statistics logging, etc. Caching method results
In the sample Spring boot application we are using, we already have the following API GET
/API/v1/customer/{id} Retrieve customer records.
 We will add caching to the
We will add caching to the
method of the CustomerService class. To do this, we only need to do two things
1. Add the comment
@CacheConfig(cacheNames="customers") to CustomerService Classes Providing this option will ensure that all cacheable methods of
will use the cache name "customers" <p>2. 向方法 <code>Optional getCustomerById(Long customerId) 添加注释 @Cacheable
@Service
@Log4j2
@CacheConfig(cacheNames = "customers")
public class CustomerService {
@Autowired
private CustomerRepository customerRepository;
@Cacheable
public Optional<Customer> getCustomerById(Long customerId) {
log.info("Fetching customer by id: {}", customerId);
return customerRepository.findById(customerId);
}
}另外,在方法 getCustomerById() 中添加一个 LOGGER 语句,以便我们知道服务方法是否得到执行,或者值是否从缓存返回。
代码如下:log.info("Fetching customer by id: {}", customerId);测试缓存是否正常工作
这就是缓存工作所需的全部内容。现在是测试缓存的时候了。
启动您的应用程序,并点击客户获取url
http://localhost:8080/api/v1/customer/
在第一次API调用之后,您将在日志中看到以下行—“ Fetching customer by id ”。
但是,如果再次点击API,您将不会在日志中看到任何内容。这意味着该方法没有得到执行,并且从缓存返回客户记录。
现在等待一分钟(因为缓存过期时间设置为1分钟)。
一分钟后再次点击GETAPI,您将看到下面的语句再次被记录——“通过id获取客户”。
这意味着客户记录在1分钟后从缓存中删除,必须再次从数据库中获取。
为什么缓存有时会很危险
缓存更新/失效
通常我们缓存 GET 调用,以提高性能。
但我们需要非常小心的是缓存对象的更新/删除。
@CachePut @cacheexecute
如果未将 @CachePut/@cacheexecute 放入更新/删除方法中,GET调用中缓存返回的对象将与数据库中存储的对象不同。考虑下面的示例场景。
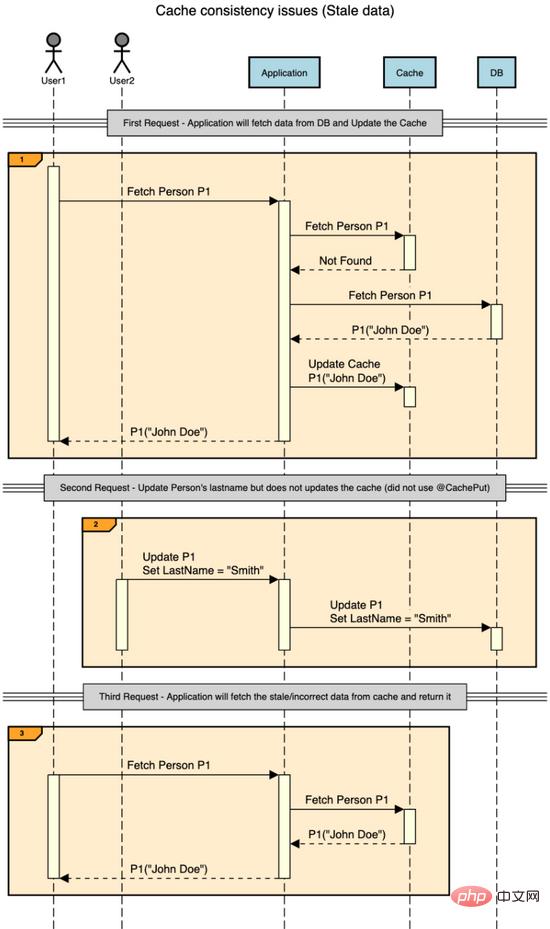
如您所见,第二个请求已将人名更新为“ John Smith ”。但由于它没有更新缓存,因此从此处开始的所有请求都将从缓存中获取过时的个人记录(“ John Doe ”),直到该项在缓存中被删除/更新。
缓存复制
大多数现代web应用程序通常有多个应用程序节点,并且在大多数情况下都有一个负载平衡器,可以将用户请求重定向到一个可用的应用程序节点。
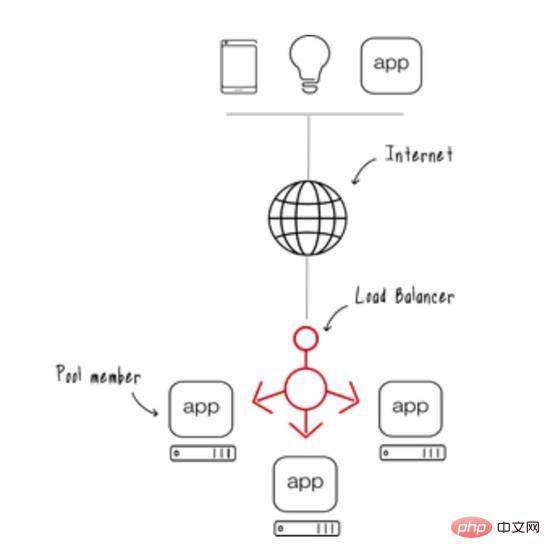
这种类型的部署为应用程序提供了可伸缩性,任何用户请求都可以由任何一个可用的应用程序节点提供服务。
在这些分布式环境(具有多个应用服务器节点)中,缓存可以通过两种方式实现
应用服务器中的嵌入式缓存(正如我们现在看到的)
远程缓存服务器
嵌入式缓存
嵌入式缓存驻留在应用程序服务器中,它随应用程序服务器启动/停止。由于每台服务器都有自己的缓存副本,因此对其缓存的任何更改/更新都不会自动反映在其他应用程序服务器的缓存中。
考虑具有嵌入式缓存的多节点应用服务器的下面场景,其中用户可以根据应用服务器为其请求服务而得到不同的结果。
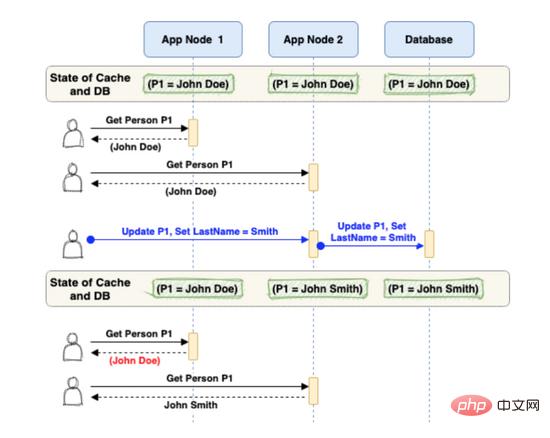
正如您在上面的示例中所看到的,更新请求更新了 Application Node2 的数据库和嵌入式缓存。
但是, Application Node1 的嵌入式缓存未更新,并且包含过时数据。因此, Application Node1 的任何请求都将继续服务于旧数据。
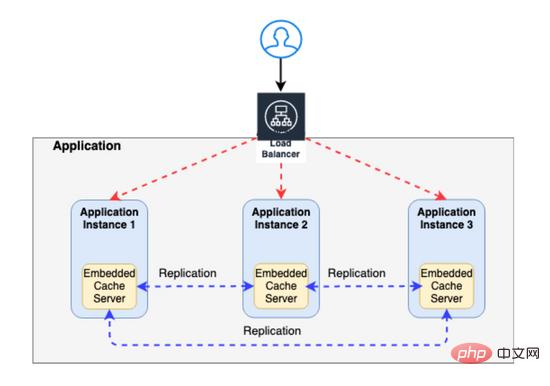
要解决这个问题,您需要实现 CACHE REPLICATION —其中任何一个缓存中的任何更新都会自动复制到其他缓存(下图中显示为蓝色虚线)
远程缓存服务器
解决上述问题的另一种方法是使用远程缓存服务器(如下所示)。

然而,这种方法的最大缺点是增加了响应时间——这是由于从远程缓存服务器获取数据时的网络延迟(与内存缓存相比)
缓存自定义
到目前为止,我们看到的缓存示例是向应用程序添加基本缓存所需的唯一代码。
然而,现实世界的场景可能不是那么简单,可能需要进行一些定制。在本节中,我们将看到几个这样的例子
缓存密钥
我们知道缓存是密钥、值对的存储。
示例1:默认缓存键–具有单参数的方法
最简单的缓存键是当方法只有一个参数,并且该参数成为缓存键时。在下面的示例中, Long customerId 是缓存键

示例2:默认缓存键–具有多个参数的方法
在下面的示例中,缓存键是所有三个参数的SimpleKey– countryId 、 regionId 、 personId 。

示例3:自定义缓存密钥
在下面的示例中,我们将此人的 emailAddress 指定为缓存的密钥

示例4:使用 KeyGenerator 的自定义缓存密钥
让我们看看下面的示例–如果要缓存当前登录用户的所有角色,该怎么办。

该方法中没有提供任何参数,该方法在内部获取当前登录用户并返回其角色。
为了实现这个需求,我们需要创建一个如下所示的自定义密钥生成器

然后我们可以在我们的方法中使用这个键生成器,如下所示。

条件缓存
在某些用例中,我们只希望在满足某些条件的情况下缓存结果
示例1(支持 java.util.Optional –仅当存在时才缓存)
仅当结果中存在 person 对象时,才缓存 person 对象。
@Cacheable( value = "persons", unless = "#result?.id") public Optional<Person> getPerson(Long personId)
示例2(如果需要,by-pass缓存)
@Cacheable(value = "persons", condition="#fetchFromCache") public Optional<Person> getPerson(long personId, boolean fetchFromCache)
仅当方法参数“ fetchFromCache ”为true时,才从缓存中获取人员。通过这种方式,方法的调用方有时可以决定绕过缓存并直接从数据库获取值。
示例3(基于对象属性的条件计算)
仅当价格低于500且产品有库存时,才缓存产品。
@Cacheable( value="products", condition="#product.price<500", unless="#result.outOfStock") public Product findProduct(Product product)
@CachePut
我们已经看到 @Cacheable 用于将项目放入缓存。
但是,如果该对象被更新,并且我们想要更新缓存,该怎么办?
我们已经在前面的一节中看到,不更新缓存post任何更新操作都可能导致从缓存返回错误的结果。
@CachePut(key = "#person.id") public Person update(Person person)
但是如果 @Cacheable 和 @CachePut 都将一个项目放入缓存,它们之间有什么区别?
主要区别在于实际的方法执行
@Cacheable @CachePut
缓存失效
缓存失效与将对象放入缓存一样重要。
当我们想要从缓存中删除一个或多个对象时,有很多场景。让我们看一些例子。
例1
假设我们有一个用于批量导入个人记录的API。
我们希望在调用此方法之前,应该清除整个 person 缓存(因为大多数 person 记录可能会在导入时更新,而缓存可能会过时)。我们可以这样做如下
@CacheEvict( value = "persons", allEntries = true, beforeInvocation = true) public void importPersons()
例2
我们有一个Delete Person API,我们希望它在删除时也能从缓存中删除 Person 记录。
@CacheEvict( value = "persons", key = "#person.emailAddress") public void deletePerson(Person person)
默认情况下 @CacheEvict 在方法调用后运行。
The above is the detailed content of How SpringBoot uses Caffeine to implement caching. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 How Springboot integrates Jasypt to implement configuration file encryption
Jun 01, 2023 am 08:55 AM
How Springboot integrates Jasypt to implement configuration file encryption
Jun 01, 2023 am 08:55 AM
Introduction to Jasypt Jasypt is a java library that allows a developer to add basic encryption functionality to his/her project with minimal effort and does not require a deep understanding of how encryption works. High security for one-way and two-way encryption. , standards-based encryption technology. Encrypt passwords, text, numbers, binaries... Suitable for integration into Spring-based applications, open API, for use with any JCE provider... Add the following dependency: com.github.ulisesbocchiojasypt-spring-boot-starter2. 1.1Jasypt benefits protect our system security. Even if the code is leaked, the data source can be guaranteed.
 How SpringBoot integrates Redisson to implement delay queue
May 30, 2023 pm 02:40 PM
How SpringBoot integrates Redisson to implement delay queue
May 30, 2023 pm 02:40 PM
Usage scenario 1. The order was placed successfully but the payment was not made within 30 minutes. The payment timed out and the order was automatically canceled. 2. The order was signed and no evaluation was conducted for 7 days after signing. If the order times out and is not evaluated, the system defaults to a positive rating. 3. The order is placed successfully. If the merchant does not receive the order for 5 minutes, the order is cancelled. 4. The delivery times out, and push SMS reminder... For scenarios with long delays and low real-time performance, we can Use task scheduling to perform regular polling processing. For example: xxl-job Today we will pick
 How to use Redis to implement distributed locks in SpringBoot
Jun 03, 2023 am 08:16 AM
How to use Redis to implement distributed locks in SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implements distributed lock principle and why distributed locks are needed. Before talking about distributed locks, it is necessary to explain why distributed locks are needed. The opposite of distributed locks is stand-alone locks. When we write multi-threaded programs, we avoid data problems caused by operating a shared variable at the same time. We usually use a lock to mutually exclude the shared variables to ensure the correctness of the shared variables. Its scope of use is in the same process. If there are multiple processes that need to operate a shared resource at the same time, how can they be mutually exclusive? Today's business applications are usually microservice architecture, which also means that one application will deploy multiple processes. If multiple processes need to modify the same row of records in MySQL, in order to avoid dirty data caused by out-of-order operations, distribution needs to be introduced at this time. The style is locked. Want to achieve points
 How to solve the problem that springboot cannot access the file after reading it into a jar package
Jun 03, 2023 pm 04:38 PM
How to solve the problem that springboot cannot access the file after reading it into a jar package
Jun 03, 2023 pm 04:38 PM
Springboot reads the file, but cannot access the latest development after packaging it into a jar package. There is a situation where springboot cannot read the file after packaging it into a jar package. The reason is that after packaging, the virtual path of the file is invalid and can only be accessed through the stream. Read. The file is under resources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot and SpringMVC are both commonly used frameworks in Java development, but there are some obvious differences between them. This article will explore the features and uses of these two frameworks and compare their differences. First, let's learn about SpringBoot. SpringBoot was developed by the Pivotal team to simplify the creation and deployment of applications based on the Spring framework. It provides a fast, lightweight way to build stand-alone, executable
 How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
When Springboot+Mybatis-plus does not use SQL statements to perform multi-table adding operations, the problems I encountered are decomposed by simulating thinking in the test environment: Create a BrandDTO object with parameters to simulate passing parameters to the background. We all know that it is extremely difficult to perform multi-table operations in Mybatis-plus. If you do not use tools such as Mybatis-plus-join, you can only configure the corresponding Mapper.xml file and configure The smelly and long ResultMap, and then write the corresponding sql statement. Although this method seems cumbersome, it is highly flexible and allows us to
 How SpringBoot customizes Redis to implement cache serialization
Jun 03, 2023 am 11:32 AM
How SpringBoot customizes Redis to implement cache serialization
Jun 03, 2023 am 11:32 AM
1. Customize RedisTemplate1.1, RedisAPI default serialization mechanism. The API-based Redis cache implementation uses the RedisTemplate template for data caching operations. Here, open the RedisTemplate class and view the source code information of the class. publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations, BeanClassLoaderAware{//Declare key, Various serialization methods of value, the initial value is empty @NullableprivateRedisSe
 How to get the value in application.yml in springboot
Jun 03, 2023 pm 06:43 PM
How to get the value in application.yml in springboot
Jun 03, 2023 pm 06:43 PM
In projects, some configuration information is often needed. This information may have different configurations in the test environment and the production environment, and may need to be modified later based on actual business conditions. We cannot hard-code these configurations in the code. It is best to write them in the configuration file. For example, you can write this information in the application.yml file. So, how to get or use this address in the code? There are 2 methods. Method 1: We can get the value corresponding to the key in the configuration file (application.yml) through the ${key} annotated with @Value. This method is suitable for situations where there are relatively few microservices. Method 2: In actual projects, When business is complicated, logic
