

How to get a handle on SpringBoot log files

SpringBoot log file
1. What is the use of logs
The log is an important part of the program. Imagine if the program reports an error and does not allow you to open the console to view the log, can you find the cause of the error?
For us, the main purpose of logs is to troubleshoot and locate problems. In addition to discovering and locating problems, we can also achieve the following functions through logs:
Record user login logs to facilitate analysis of whether the user logs in normally or maliciously cracks the user
Record the operation log of the system to facilitate data recovery and locate the operator
Record the execution time of the program to facilitate future optimization programs to provide data support
2. How to use logs
The Spring Boot project will have log output by default when it is started, as shown below:

Through the above information we can find:
Spring Boot has a built-in logging framework
By default, the output log is not defined by the developer and printing, so how do developers define print logs in the program?
The log is printed on the console by default, but the console log cannot be saved. How to save the log permanently?
3. Customized log printing
Implementation steps for developers to customize log printing:
Get it in the program Log
Use the relevant syntax of the log object to output the content to be printed
3.1 Get the log object in the program
private static final Logger log = LoggerFactory.getLogger(UserController.class);
The log factory needs to pass the type of each class in, so that we can know the ownership class of the log, and locate the problem more conveniently and intuitively
Note: The logger object belongs to the org.slf4j package, do not import it Wrong

3.2 Use the log object to print the log
There are many ways to print the log object. We can use the info method to output the log,
@Controller
@ResponseBody
public class UserController {
private static final Logger log = LoggerFactory.getLogger(UserController.class);
@RequestMapping("/sayhi")
public void sayHi() {
log.trace("trace");
log.debug("debug");
log.info("info");
log.warn("warn");
log.error("error");
}
}
4. Log level
4.1 What is the use of log level?
The log level can help you filter out important information. For example, if you set the log level to error, you can only see the error log of the program. For ordinary debugging logs and business logs It can be ignored. This saves developers time in screening
The log level can control whether a program needs to print logs in different environments. For example, in the development environment we need very detailed information, and in the production environment in order to maintain performance and security will output a small amount of logs, and such requirements can be achieved through log levels
4.2 Classification and use of log levels
Log levels are divided into:
trace: trace, meaning a little, the lowest level
debug: print key information when debugging is required
info: Ordinary print information (default log level)
warn: Warning: Does not affect use, but needs attention
error: error message, higher level error log message
fatal: fatal, an event that causes the program to exit execution due to code exception
The order of log levels:
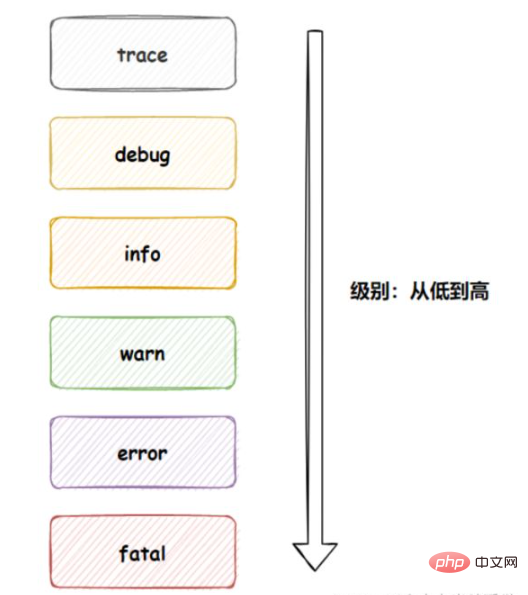
The higher up, the less information is received. If warn is set, only warn and the levels above it can be received.
Log level settings
logging:
level:
root: errorDefault log output level
Clear the log settings in the configuration file and observe the console output The log level
comes to the conclusion that the default log output level is info
When there are local log level and global log level settings, then when accessing the local log, the local log is used level. That is, the priority of local logs is higher than the priority of global logs
5. Log persistence
The above logs are output on the console, but in the production environment we need Save the log so that you can trace the problem after a problem occurs. The process of saving the log is called persistence
If you want to persist the date, you only need to specify the storage directory of the log in the configuration file or specify the log. Save the file name, Spring Boot will write the console log to the corresponding directory or file
Configure the saving path of the log file:
logging:
file:
path: D:\rizhiThe saved path, which contains escape characters For aspect settings, we can use this / as a separator.
If you insist on using the delimiter under Windows, we need to use the \ escape character to escape
配置日志文件的文件名:
logging:
file:
name: D:/rizhi/logger/spring.log6. 更简单的日志输出–lombok
每次使用LoggerFactory.getLogger很繁琐,且每个类都添加一遍,也很麻烦。这里的lombok是一种更好的日志输出方式
添加lombok框架支持
使用@slf4j注解输出日志
6.1 添加 lombok 依赖
首先要安装一个插件:
然后再pom.xml页面右键、
最后重新添加依赖就可以了
6.2 输出日志
使用@Slf4j注解,在程序中使用log对象即可输入日志并且只能使用log对象才能输出,这是lombok提供的对象名
6.3 lombok原理解释
lombok 能够打印⽇志的密码就在 target ⽬录⾥⾯,target 为项⽬最终执⾏的代码,查看 target ⽬录我们可以发现:
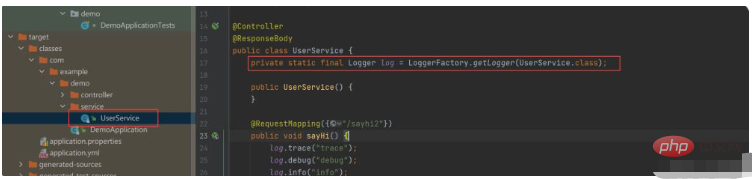
这里的@Slf4j注解变成了一个对象。
下面是java程序的运行原理:
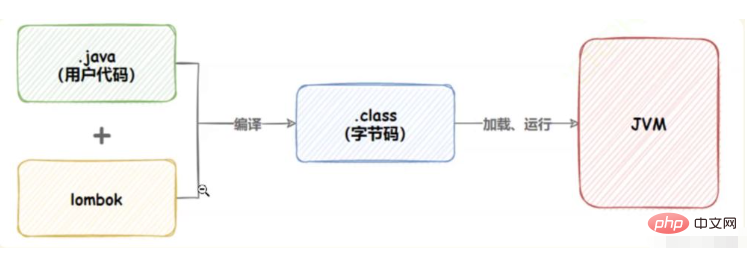
6.4 lombok更多注解说明
基本注解
| 注解 | 作用 |
|---|---|
| @Getter | 自动添加get方法 |
| @Setter | 自动添加set方法 |
| @ToString | 自动添加toString方法 |
| @EqualsAndHashCode | 自动添加equals和hasCode方法 |
| @NoArgsConstructor | 自动添加无参构造方法 |
| @AllArgsConstructor | 自动添加全属性构造方法,顺序按照属性的定义顺序 |
| @NonNull | 属性不能为null |
| @RequiredArgsConstructor | 自动添加必须属性的构造方法,final + @NonNull的属性为需 |
组合注解:
| 注解 | 作用 |
|---|---|
| @Data | @Getter+@Setter+EqualsAndHashCode+@RequiredArgsConstructor+@NoArgsConstructor |
日志注解
| 注解 | 作用 |
|---|---|
| @Slf4j | 添加一个名为log的对象 |
The above is the detailed content of How to get a handle on SpringBoot log files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How Springboot integrates Jasypt to implement configuration file encryption
Jun 01, 2023 am 08:55 AM
How Springboot integrates Jasypt to implement configuration file encryption
Jun 01, 2023 am 08:55 AM
Introduction to Jasypt Jasypt is a java library that allows a developer to add basic encryption functionality to his/her project with minimal effort and does not require a deep understanding of how encryption works. High security for one-way and two-way encryption. , standards-based encryption technology. Encrypt passwords, text, numbers, binaries... Suitable for integration into Spring-based applications, open API, for use with any JCE provider... Add the following dependency: com.github.ulisesbocchiojasypt-spring-boot-starter2. 1.1Jasypt benefits protect our system security. Even if the code is leaked, the data source can be guaranteed.
 How SpringBoot integrates Redisson to implement delay queue
May 30, 2023 pm 02:40 PM
How SpringBoot integrates Redisson to implement delay queue
May 30, 2023 pm 02:40 PM
Usage scenario 1. The order was placed successfully but the payment was not made within 30 minutes. The payment timed out and the order was automatically canceled. 2. The order was signed and no evaluation was conducted for 7 days after signing. If the order times out and is not evaluated, the system defaults to a positive rating. 3. The order is placed successfully. If the merchant does not receive the order for 5 minutes, the order is cancelled. 4. The delivery times out, and push SMS reminder... For scenarios with long delays and low real-time performance, we can Use task scheduling to perform regular polling processing. For example: xxl-job Today we will pick
 How to use Redis to implement distributed locks in SpringBoot
Jun 03, 2023 am 08:16 AM
How to use Redis to implement distributed locks in SpringBoot
Jun 03, 2023 am 08:16 AM
1. Redis implements distributed lock principle and why distributed locks are needed. Before talking about distributed locks, it is necessary to explain why distributed locks are needed. The opposite of distributed locks is stand-alone locks. When we write multi-threaded programs, we avoid data problems caused by operating a shared variable at the same time. We usually use a lock to mutually exclude the shared variables to ensure the correctness of the shared variables. Its scope of use is in the same process. If there are multiple processes that need to operate a shared resource at the same time, how can they be mutually exclusive? Today's business applications are usually microservice architecture, which also means that one application will deploy multiple processes. If multiple processes need to modify the same row of records in MySQL, in order to avoid dirty data caused by out-of-order operations, distribution needs to be introduced at this time. The style is locked. Want to achieve points
 How to solve the problem that springboot cannot access the file after reading it into a jar package
Jun 03, 2023 pm 04:38 PM
How to solve the problem that springboot cannot access the file after reading it into a jar package
Jun 03, 2023 pm 04:38 PM
Springboot reads the file, but cannot access the latest development after packaging it into a jar package. There is a situation where springboot cannot read the file after packaging it into a jar package. The reason is that after packaging, the virtual path of the file is invalid and can only be accessed through the stream. Read. The file is under resources publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
How to implement Springboot+Mybatis-plus without using SQL statements to add multiple tables
Jun 02, 2023 am 11:07 AM
When Springboot+Mybatis-plus does not use SQL statements to perform multi-table adding operations, the problems I encountered are decomposed by simulating thinking in the test environment: Create a BrandDTO object with parameters to simulate passing parameters to the background. We all know that it is extremely difficult to perform multi-table operations in Mybatis-plus. If you do not use tools such as Mybatis-plus-join, you can only configure the corresponding Mapper.xml file and configure The smelly and long ResultMap, and then write the corresponding sql statement. Although this method seems cumbersome, it is highly flexible and allows us to
 Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
Comparison and difference analysis between SpringBoot and SpringMVC
Dec 29, 2023 am 11:02 AM
SpringBoot and SpringMVC are both commonly used frameworks in Java development, but there are some obvious differences between them. This article will explore the features and uses of these two frameworks and compare their differences. First, let's learn about SpringBoot. SpringBoot was developed by the Pivotal team to simplify the creation and deployment of applications based on the Spring framework. It provides a fast, lightweight way to build stand-alone, executable
 How SpringBoot customizes Redis to implement cache serialization
Jun 03, 2023 am 11:32 AM
How SpringBoot customizes Redis to implement cache serialization
Jun 03, 2023 am 11:32 AM
1. Customize RedisTemplate1.1, RedisAPI default serialization mechanism. The API-based Redis cache implementation uses the RedisTemplate template for data caching operations. Here, open the RedisTemplate class and view the source code information of the class. publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations, BeanClassLoaderAware{//Declare key, Various serialization methods of value, the initial value is empty @NullableprivateRedisSe
 How to get the value in application.yml in springboot
Jun 03, 2023 pm 06:43 PM
How to get the value in application.yml in springboot
Jun 03, 2023 pm 06:43 PM
In projects, some configuration information is often needed. This information may have different configurations in the test environment and the production environment, and may need to be modified later based on actual business conditions. We cannot hard-code these configurations in the code. It is best to write them in the configuration file. For example, you can write this information in the application.yml file. So, how to get or use this address in the code? There are 2 methods. Method 1: We can get the value corresponding to the key in the configuration file (application.yml) through the ${key} annotated with @Value. This method is suitable for situations where there are relatively few microservices. Method 2: In actual projects, When business is complicated, logic
