

How to optimize Nginx and Node.js for high-load networks

Network Tuning
If you don’t first understand the underlying transmission mechanisms of nginx and node.js and carry out targeted optimization, no matter how detailed the tuning of the two is, it may be in vain. . Normally, nginx connects the client and upstream applications through tcp socket.
Our system has many thresholds and restrictions for tcp, which are set through kernel parameters. The default values of these parameters are often set for general purposes and cannot meet the high traffic and short life requirements of web servers.
Here are some parameters for tuning tcp. To make them effective, you can put them in the /etc/sysctl.conf file, or put them in a new configuration file, such as /etc/sysctl.d/99-tuning.conf, and then run sysctl -p to let the kernel load they. We use sysctl-cookbook to do this physical work.
It should be noted that the values listed here are safe to use, but it is still recommended that you study the meaning of each parameter in order to choose a more appropriate value based on your load, hardware and usage.
Copy code The code is as follows:
net.ipv4. ip_local_port_range='1024 65000'
net.ipv4.tcp_tw_reuse='1'
net.ipv4.tcp_fin_timeout='15'
net.core.netdev_max_backlog='4096'
net.core.rmem_max ='16777216'
net.core.somaxconn='4096'
net.core.wmem_max='16777216'
net.ipv4.tcp_max_syn_backlog='20480'
net.ipv4.tcp_max_tw_buckets=' 400000'
net.ipv4.tcp_no_metrics_save='1'
net.ipv4.tcp_rmem='4096 87380 16777216'
net.ipv4.tcp_syn_retries='2'
net.ipv4.tcp_synack_retries=' 2'
net.ipv4.tcp_wmem='4096 65536 16777216'
vm.min_free_kbytes='65536'
Highlight some of the important ones.
net.ipv4.ip_local_port_range
In order to serve the downstream client for the upstream application, nginx must open two tcp connections, one to connect to the client and one to connect to the application. When a server receives many connections, the system's available ports will quickly be exhausted. By modifying the net.ipv4.ip_local_port_range parameter, you can increase the range of available ports. If such an error is found in /var/log/syslog: "possible syn flooding on port 80. sending cookies", it means that the system cannot find an available port. Increasing the net.ipv4.ip_local_port_range parameter can reduce this error.
net.ipv4.tcp_tw_reuse
When the server needs to switch between a large number of tcp connections, a large number of connections in the time_wait state will be generated. time_wait means that the connection itself is closed, but the resources have not been released. Setting net_ipv4_tcp_tw_reuse to 1 lets the kernel try to recycle connections when it is safe, which is much cheaper than re-establishing new connections.
net.ipv4.tcp_fin_timeout
This is the minimum time that a connection in the time_wait state must wait before recycling. Making it smaller can speed up recycling.
How to check the connection status
Use netstat:
netstat -tan | awk '{print $6}' | sort | uniq -c
or use ss:
ss - s
nginx
ss -s
total: 388 (kernel 541)
tcp: 47461 (estab 311, closed 47135, orphaned 4, synrecv 0, timewait 47135/0), ports 33938
transport total ip ipv6
* 541 - -
raw 0 0 0
udp 13 10 3
tcp 326 325 1
inet 339 335 4
frag 0 0 0
As the load on the web server gradually increases, we will start to encounter some strange limitations of nginx. The connection is dropped and the kernel keeps reporting syn flood. At this time, the load average and CPU usage are very small, and the server can obviously handle more connections, which is really frustrating.
After investigation, it was found that there are many connections in the time_wait state. This is the output from one of the servers:
There are 47135 time_wait connections! Moreover, it can be seen from ss that they are all closed connections. This indicates that the server has consumed most of the available ports, and also implies that the server is allocating new ports for each connection. Tuning the network helped a little with the problem, but there were still not enough ports.
After further research, I found a document about the upstream connection keepalive directive, which wrote:
Set the maximum number of idle keepalive connections to the upstream server. These connections will be retained in the cache of the worker process. .
interesting. In theory, this setup minimizes wasted connections by passing requests over cached connections. The documentation also mentions that we should set proxy_http_version to "1.1" and clear the "connection" header. After further research, I found that this is a good idea, because http/1.1 greatly optimizes the usage of tcp connections compared to http1.0, and nginx uses http/1.0 by default.
After modification according to the recommendations of the document, our uplink configuration file becomes like this:
Copy the code The code is as follows:
upstream backend_nodejs {
server nodejs-3:5016 max_fails=0 fail_timeout=10s;
server nodejs-4:5016 max_fails=0 fail_timeout=10s;
server nodejs-5:5016 max_fails=0 fail_timeout=10s;
server nodejs-6:5016 max_fails=0 fail_timeout=10s;
keepalive 512;
}
I also modified the proxy settings in the server section according to its suggestions . At the same time, a proxy_next_upstream was added to skip failed servers, the client's keepalive_timeout was adjusted, and the access log was turned off. The configuration becomes like this:
Copy code The code is as follows:
server {
listen 80;
server_name fast.gosquared.com;
client_max_body_size 16m;
keepalive_timeout 10;
location / {
proxy_next_upstream error timeout http_500 http_502 http_503 http_504;
proxy_set_header connection "";
proxy_http_version 1.1;
proxy_pass http://backend_nodejs;
}
access_log off;
error_log /dev/null crit;
}
After adopting the new configuration, I found that the sockets occupied by the servers were reduced by 90%. Requests can now be transmitted using far fewer connections. The new output is as follows:
ss -s
total: 558 (kernel 604)
tcp: 4675 (estab 485, closed 4183, orphaned 0, synrecv 0, timewait 4183/0), ports 2768
transport total ip ipv6
* 604 - -
raw 0 0 0
udp 13 10 3
tcp 492 491 1
inet 505 501 4
node.js
got Thanks to its event-driven design that handles I/O asynchronously, Node.js can handle large numbers of connections and requests out of the box. Although there are other tuning methods, this article will focus mainly on the process aspect of node.js.
Node is single-threaded and will not automatically use multiple cores. In other words, the application cannot automatically obtain the full capabilities of the server.
Achieving clustering of node processes
We can modify the application so that it forks multiple threads and receives data on the same port, thereby enabling the load to span multiple cores. Node has a cluster module that provides all the tools necessary to achieve this goal, but adding them to the application requires a lot of manual labor. If you are using express, eBay has a module called cluster2 that can be used.
Prevent context switching
When running multiple processes, you should ensure that each CPU core is only busy with one process at the same time. Generally speaking, if the CPU has n cores, we should generate n-1 application processes. This ensures that each process gets a reasonable time slice, leaving one core free for the kernel scheduler to run other tasks. We also need to ensure that basically no other tasks other than node.js are executed on the server to prevent CPU contention.
We once made a mistake and deployed two node.js applications on the server, and then each application opened n-1 processes. As a result, they compete for the CPU with each other, causing the system load to rise sharply. Although our servers are all 8-core machines, the performance overhead caused by context switching can still be clearly felt. Context switching refers to the phenomenon where the CPU suspends the current task in order to perform other tasks. When switching, the kernel must suspend all state of the current process and then load and execute another process. In order to solve this problem, we reduced the number of processes started by each application so that they can share the CPU fairly. As a result, the system load was reduced: 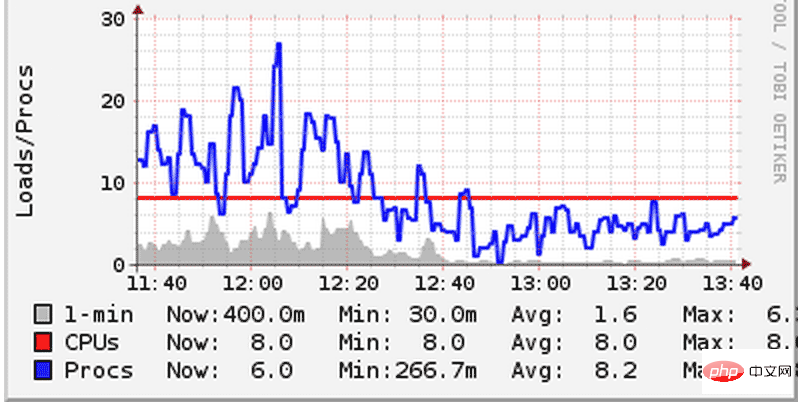
Please pay attention to the picture above and look at the system How does the load (blue line) drop below the number of cpu cores (red line). On other servers, we saw the same thing. Since the total workload remains the same, the performance improvements in the graph above can only be attributed to the reduction in context switches.
In no particular order:
1. When performance problems are encountered, if calculation and processing can be performed at the application layer, then take it from the database layer come out. Sorting and grouping are classic examples. It is always easier to improve performance at the application layer than at the database layer. Just like MySQL, sqlite is easier to control.
2. Regarding parallel computing, try to avoid it if you can. If it cannot be avoided, remember that with great power comes great responsibility. If possible, try to avoid operating directly on threads. Operate at a higher level of abstraction whenever possible. For example, in iOS, GCD, distribution and queue operations are your friends. The human brain is not designed to analyze infinite temporary states - I learned this the hard way.
3. Simplify the state as much as possible and localize it as much as possible. Applicability comes first.
4. Short and combinable methods are your friends.
5. Code comments are dangerous because they can easily be out of date or misleading, but this is no reason not to write comments. Don't comment on trivial things, but if necessary, long strategic comments are needed in some special places. Your memory will betray you, maybe tomorrow morning, maybe after a cup of coffee.
6. If you think a use case scenario might be "okay," it might be where you fail miserably in your released product a month later. Be a skeptic, test, verify.
7. When in doubt, talk to everyone on the team.
8. Do the right thing—you usually know what that means.
9. Your users are not stupid, they just don’t have the patience to understand your shortcuts.
10. If a developer is not scheduled to maintain the system you develop for a long time, be wary of him. 80% of the blood, sweat, and tears are shed in the time after the software is released - then you will become a misanthrope, but also a smarter "connoisseur".
11. To-do lists are your best friend.
12. Take the initiative to make your job more fun, sometimes this requires effort on your part.
13. Silent meltdowns that I still wake up from nightmares about. Monitoring, logging, alerting. Be aware of the various false alarms and inevitable sensory dulling. Keep your system alert to failures and timely.
The above is the detailed content of How to optimize Nginx and Node.js for high-load networks. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to configure nginx in Windows
Apr 14, 2025 pm 12:57 PM
How to configure nginx in Windows
Apr 14, 2025 pm 12:57 PM
How to configure Nginx in Windows? Install Nginx and create a virtual host configuration. Modify the main configuration file and include the virtual host configuration. Start or reload Nginx. Test the configuration and view the website. Selectively enable SSL and configure SSL certificates. Selectively set the firewall to allow port 80 and 443 traffic.
 How to check the name of the docker container
Apr 15, 2025 pm 12:21 PM
How to check the name of the docker container
Apr 15, 2025 pm 12:21 PM
You can query the Docker container name by following the steps: List all containers (docker ps). Filter the container list (using the grep command). Gets the container name (located in the "NAMES" column).
 How to start containers by docker
Apr 15, 2025 pm 12:27 PM
How to start containers by docker
Apr 15, 2025 pm 12:27 PM
Docker container startup steps: Pull the container image: Run "docker pull [mirror name]". Create a container: Use "docker create [options] [mirror name] [commands and parameters]". Start the container: Execute "docker start [Container name or ID]". Check container status: Verify that the container is running with "docker ps".
 How to check whether nginx is started
Apr 14, 2025 pm 01:03 PM
How to check whether nginx is started
Apr 14, 2025 pm 01:03 PM
How to confirm whether Nginx is started: 1. Use the command line: systemctl status nginx (Linux/Unix), netstat -ano | findstr 80 (Windows); 2. Check whether port 80 is open; 3. Check the Nginx startup message in the system log; 4. Use third-party tools, such as Nagios, Zabbix, and Icinga.
 How to create containers for docker
Apr 15, 2025 pm 12:18 PM
How to create containers for docker
Apr 15, 2025 pm 12:18 PM
Create a container in Docker: 1. Pull the image: docker pull [mirror name] 2. Create a container: docker run [Options] [mirror name] [Command] 3. Start the container: docker start [Container name]
 How to check nginx version
Apr 14, 2025 am 11:57 AM
How to check nginx version
Apr 14, 2025 am 11:57 AM
The methods that can query the Nginx version are: use the nginx -v command; view the version directive in the nginx.conf file; open the Nginx error page and view the page title.
 How to configure cloud server domain name in nginx
Apr 14, 2025 pm 12:18 PM
How to configure cloud server domain name in nginx
Apr 14, 2025 pm 12:18 PM
How to configure an Nginx domain name on a cloud server: Create an A record pointing to the public IP address of the cloud server. Add virtual host blocks in the Nginx configuration file, specifying the listening port, domain name, and website root directory. Restart Nginx to apply the changes. Access the domain name test configuration. Other notes: Install the SSL certificate to enable HTTPS, ensure that the firewall allows port 80 traffic, and wait for DNS resolution to take effect.
 How to start nginx server
Apr 14, 2025 pm 12:27 PM
How to start nginx server
Apr 14, 2025 pm 12:27 PM
Starting an Nginx server requires different steps according to different operating systems: Linux/Unix system: Install the Nginx package (for example, using apt-get or yum). Use systemctl to start an Nginx service (for example, sudo systemctl start nginx). Windows system: Download and install Windows binary files. Start Nginx using the nginx.exe executable (for example, nginx.exe -c conf\nginx.conf). No matter which operating system you use, you can access the server IP
