
 Technology peripherals
AI
Application of continuous transfer learning cross-domain recommendation ranking model in Taobao recommendation system
Technology peripherals
AI
Application of continuous transfer learning cross-domain recommendation ranking model in Taobao recommendation system
Application of continuous transfer learning cross-domain recommendation ranking model in Taobao recommendation system

This article explores how to implement a cross-domain recommendation model under the framework of continuous learning in the industry, and proposes a new cross-domain recommendation paradigm of continuous transfer learning, using the intermediate layer representation results of the continuously pre-trained source domain model as Based on the additional knowledge of the target domain model, a lightweight Adapter module was designed to realize the migration of cross-domain knowledge, and achieved significant business results in the ranking of recommended products.
Background
In recent years, with the application of deep models, the recommendation effect of recommendation systems in the industry has been significantly improved. With the continuous optimization of models, only It becomes more difficult to optimize model structure and features relying on in-scenario data. On large-scale e-commerce platforms like Taobao, in order to meet the diverse needs of different users, there are a series of recommendation scenarios of different sizes, such as information flow recommendation (you may like it on the home page), good products, post-purchase recommendations, and gathering These scenarios share the Taobao product system, but there are significant differences in specific product selection pools, core users, and business goals, and the scale of different scenarios varies greatly. Our scenario of "Good Goods" is a shopping guide scenario for Taobao's selected products. Compared with information flow recommendation, main search and other scenarios, the scale is relatively small. Therefore, how to use transfer learning, cross-domain recommendation and other methods to improve the model effect has always been It is one of the key points in optimizing the good goods sorting model. Although products and users in Taobao’s different business scenarios overlap, due to the significant differences in scenarios, the ranking model for large scenarios such as information flow recommendations does not work well when directly applied to scenarios where good products are available. Therefore, the team has made considerable attempts in the direction of cross-domain recommendation, including using a series of existing methods such as pre-training and fine-tuning, multi-scenario joint training, and global learning. These methods are either not effective enough or have quite a few problems in actual online applications. The continuous transfer learning project proposes a simple and effective new cross-domain recommendation method for a series of problems in the application of these methods in business. This method
uses the intermediate layer representation results of the continuously pre-trained source domain model as additional knowledge of the target domain model, and has achieved significant business results in the ranking of good product recommendations on Taobao.
The detailed version of this article Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao has been published on ArXiv https://arxiv.org/abs/2208.05728.Method
▐ Existing work and its shortcomingsAnalysis of existing cross-domain work in academia and industry Cross-Domain Recommendation (CDR) related work can be mainly divided into two categories: Joint Learning and Pre-training & Fine-tuning. Among them, the joint training method simultaneously optimizes the source domain (Source Domain) and target domain (Target Domain) models. However, this type of method requires the introduction of source domain data in training, and source domain samples are usually large in size, thus consuming huge computing and storage resources. Many smaller businesses cannot afford such a large resource overhead. On the other hand, this type of method needs to optimize multiple scene goals at the same time, and differences between scenes may also bring negative effects of goal conflicts. Therefore, pre-training-fine-tuning methods have wider applications in many scenes in the industry.
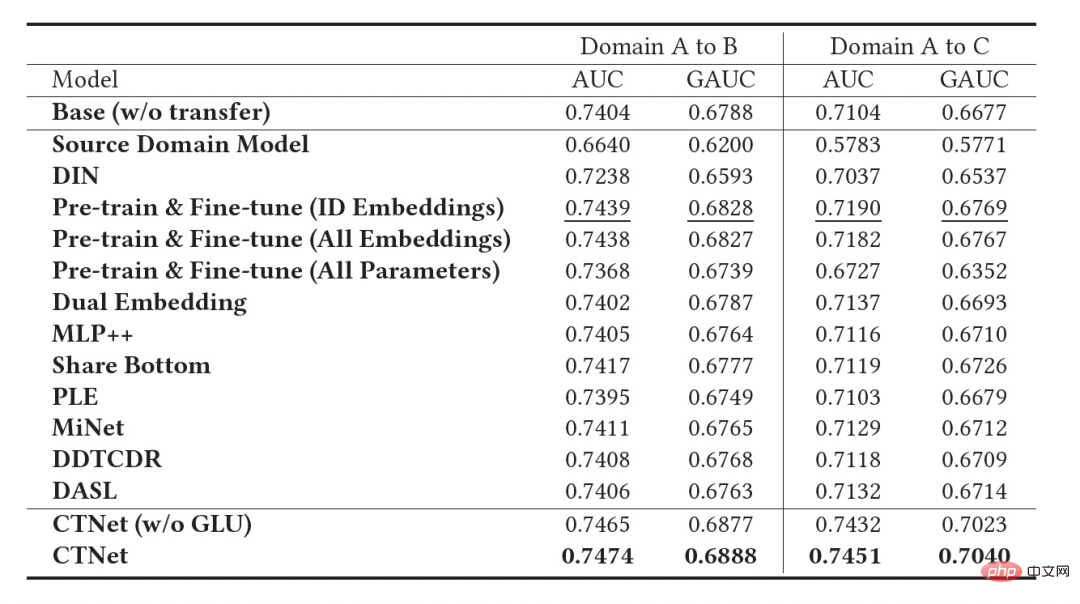
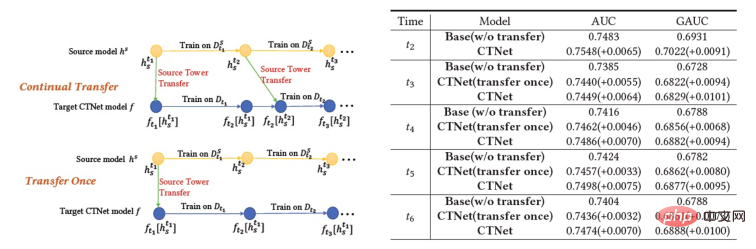
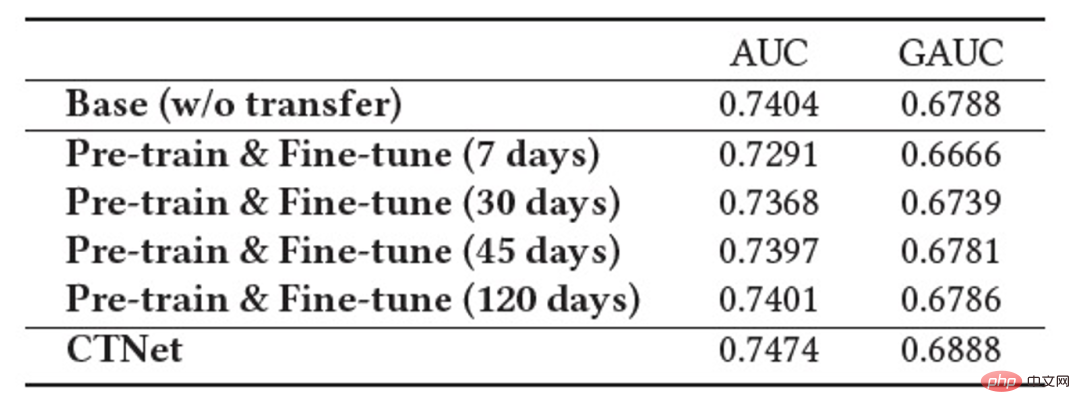
An important feature of the industrial recommendation system is that model training follows the Continual Learning (Continual Learning) paradigm, that is, the model needs to use the latest samples and utilize offline incremental updates (Incremental Learning) or Online Learning and other methods to learn the latest data distribution. For the cross-domain recommendation task studied in this article, the models in the source domain and the target domain both follow the continuous learning training method. We thus propose a new problem that will be widely used in academic and industrial applications: Continual Transfer Learning, defined as moving from one domain that changes over time to another that also changes over time. Domain knowledge transfer. We believe that the application of existing cross-domain recommendation and transfer learning methods in industrial recommendation systems, search engines, computational advertising, etc. should follow the continuous transfer learning paradigm, that is, the transfer process should be continuous and multiple times. The reason is that the data distribution changes rapidly, and only continuous migration can ensure a stable migration effect. Combined with the characteristics of this industrial recommendation system, we can find problems in the practical application of pre-training and fine-tuning. Due to the scene differences between the source domain and the target domain, it is usually necessary to use a large number of samples to obtain a better result by fine-tuning the source domain model. In order to achieve continuous transfer learning, we need to use the latest source domain model to re-fine-tune it every once in a while, resulting in a very huge training cost. This training method is also difficult to go online. In addition, using these large number of samples for fine-tuning may also cause the source domain model to forget the retained useful knowledge, avoiding the catastrophic forgetting problem in the model; using the source domain model parameters to replace the original parameters that have been learned in the target domain can also Useful knowledge gained historically from the original model is discarded. Therefore, we need to design a more efficient continuous transfer learning model suitable for industrial recommendation scenarios. This article proposes a simple and effective model CTNet (Continual Transfer Network, continuous migration network) to solve the above problems. Different from traditional pre-training-fine-tuning methods, the core idea of CTNet is that cannot forget and discard all the knowledge acquired by the model in history, and retains all parameters of the original source domain model and target domain model . These parameters store knowledge gained through very long historical data learning (for example, Taobao's fine ranking model has been continuously incrementally trained for more than two years). CTNet adopts a simple twin-tower structure and uses a lightweight Adapter layer to map the intermediate layer representation results of the continuously pre-trained source domain model as additional knowledge of the target domain model. Unlike pre-training-fine-tuning methods that require backtracking data to achieve continuous transfer learning, CTNet only requires incremental data to be updated, thereby achieving efficient continuous transfer learning. method No need to use a large number of source domain samples Not affected by source domain scenario targets Only incremental data is needed to achieve Continuous transfer learning Joint training No No Yes Pre-training-Fine-tuning Yes Yes No The CTNet proposed in this article is is yes Table 1: Comparison between CTNet and existing cross-domain recommendation models This article explores the new issue of continuous transfer learning: Given the source domain and target domain that continue to change over time, continuous transfer learning (Continual Transfer Learning) hopes to be able to Use historical or currently acquired source domain and target domain knowledge to improve prediction accuracy in the future target domain. We apply the problem of continuous transfer learning to Taobao's cross-domain recommendation task. This task has the following characteristics: Figure 1: Schematic diagram of model deployment Above picture Shows the deployment of our method online. Before the Figure 2: Continuous migration network CTNet As shown in Figure 2, the Continuous Transfer Network (CTNet) model we proposed embeds all the source domain models in the original fine-ranking model of the target domain. The features and their network parameters form a two-tower structure, in which the left tower of CTNet is the Source Tower and the right tower is the Target Tower. Different from the common methods that only use the final scoring score of the source domain model or only use some shallow representations (such as Embedding), we use a lightweight Adapter network to combine all the intermediate hidden layers of the source domain modelMLP (Especially the high-order feature interaction information of user and item contained deeply in the source domain MLP), the representation result The key to improving the effect of CTNet is to utilize the migration of deep representation information in MLP. Drawing on the idea of Gated Linear Units (GLU), the Adapter network uses a gated linear layer, which can effectively implement adaptive feature selection of source domain features. Useful knowledge in the model will be migrated, and information that is inconsistent with the scene characteristics will be transferred. can be filtered out. Since the source domain model continues to use the latest source domain supervision data for continuous pre-training, during our training process, Source Tower will also continue to load the latest updated source domain model parameters and remain fixed during the backpropagation process. , ensuring the efficient progress of continuous transfer learning. Therefore, the CTNet model is very suitable for the continuous learning paradigm, allowing the target domain model to continuously learn the latest knowledge provided by the source domain model to adapt to the latest data distribution changes. At the same time, because the model is only trained on the target domain data, it is ensured that the model is not affected by the source domain training objectives, and does not require source domain data training at all, avoiding a large amount of storage and computing overhead. In addition, such a network structure adopts an additive design method, so that the dimensions of the MLP layer of the original model do not need to be changed during the migration process. Target Tower is completely initialized by the original target domain online model, avoiding random re-initialization of the MLP layer. It can be It ensures that the effect of the original model is not damaged to the greatest extent, and only requires less incremental data to obtain good results, realizing hot start of the model. We define the source domain model as ##Figure 3: CTNet training Table 2: Offline experimental results As shown in the table above, we have the corresponding production data sets in the two sub-scenarios (Domain B and C in the table) with good goods business A series of offline experiments were conducted on the website, in which the source domain (Domain A in the table) is the homepage information flow recommendation scenario. It can be seen that the direct use of information flow recommendations (you may like it on the homepage) ranking model scoring results (Source Domain Model in the table) is not effective in the business of good goods. Compared with the online full volume model, the absolute value is GAUC-5.88. % and GAUC-9.06%, proving the differences between scenarios. We also compared a series of traditional cross-domain recommendation Baseline methods, including common pre-training-fine-tuning methods and joint training methods (such as MLP, PLE, MiNet, DDTCDR, DASL, etc.), and proposed CTNet significantly outperforms existing methods on both data sets. Compared with the full online main model, CTNet achieved significant improvements in GAUC of 1.0% and 3.6% on the two data sets respectively. We further analyzed the advantages of continuous transfer compared to single transfer through experiments. Under the framework of CTNet, the effect improvement brought by a single transfer will attenuate with the incremental update of the model, while continuous transfer learning can ensure the stable improvement of the model effect. Figure 4: Advantages of continuous transfer learning compared to single transfer The following table shows the effect of traditional pre-training-fine-tuning. We use the complete source domain model to train on the target domain data. Due to the differences between fields, a very large number of samples (such as 120-day samples) are needed to adjust the model's effect to a level comparable to the full online Base model. In order to achieve continuous transfer learning, we need to re-adjust using the latest source domain model at regular intervals. The huge cost of each adjustment also makes this method unsuitable for continuous transfer learning. In addition, this method does not surpass the base model without migration in terms of effect. The main reason is that the use of massive target domain sample training also causes the model to forget the original source domain knowledge, and the final model effect obtained by training is similar to a The effect of training only on target domain data. Under the pre-training-fine-tuning paradigm, loading only some Embedding parameters is better than reusing all parameters (as shown in Table 2). Table 3: Effect of training on the target domain using pre-trained source domain model CTNet will be completed by the end of 2021 at the earliest, and will be fully launched in February 2022 for the recommendation business of good products. Compared with the previous generation full model, significant improvements in business indicators have been achieved in two recommendation scenarios: Scenario B: CTR 2.5%, additional purchases 6.7%, number of transactions 3.4%, GMV 7.7%C scenario: CTR 12.3%, length of stay 8.8%, additional purchase 10.9%, number of transactions 30.9%, GMV 31.9% ##CTNet adopts a parallel network structure. To save computing resources, we share some parameters and results of the Attention layer, so that the same parts of the Attention layer in Source Tower and Target Tower only need to be calculated once. Compared with the Base model, CTNet's online response time (RT) is basically the same. This article explores how to implement a cross-domain recommendation model under the framework of continuous learning in the industry, and proposes a new cross-domain recommendation model called continuous transfer learning. The domain recommendation paradigm uses the intermediate layer representation results of the continuously pre-trained source domain model as additional knowledge of the target domain model. A lightweight Adapter module is designed to realize the transfer of cross-domain knowledge and achieves good product recommendation ranking. achieved significant business results. Although this method is implemented for the business characteristics of good goods, it is also a relatively general modeling method. The related modeling methods and ideas can be applied to the optimization of many other similar business scenarios. Since the existing continuous pre-trained source domain model of CTNet only uses information flow recommendation scenarios, in the future we will consider upgrading the continuously pre-trained source domain model to a full-domain learning pre-trained model including recommendation, search, private domain and other more scenarios. Train the model. We are the Taobao technology-content algorithm-good goods algorithm team. Good products are recommended by Taobao based on word-of-mouth, and are a shopping guide designed to help consumers discover good products. The team is responsible for optimizing the full-link algorithm for product recommendation and short video content recommendation business to improve advantageous product mining capabilities and channel shopping guide capabilities. The current main technical directions are continuous transfer learning cross-domain recommendation, unbiased learning, recommendation system full-link modeling, sequence modeling, etc. While creating business value, we have also published several papers at international conferences such as SIGIR. The main results include PDN, UMI, CDAN, etc.
##▐ Problem Definition
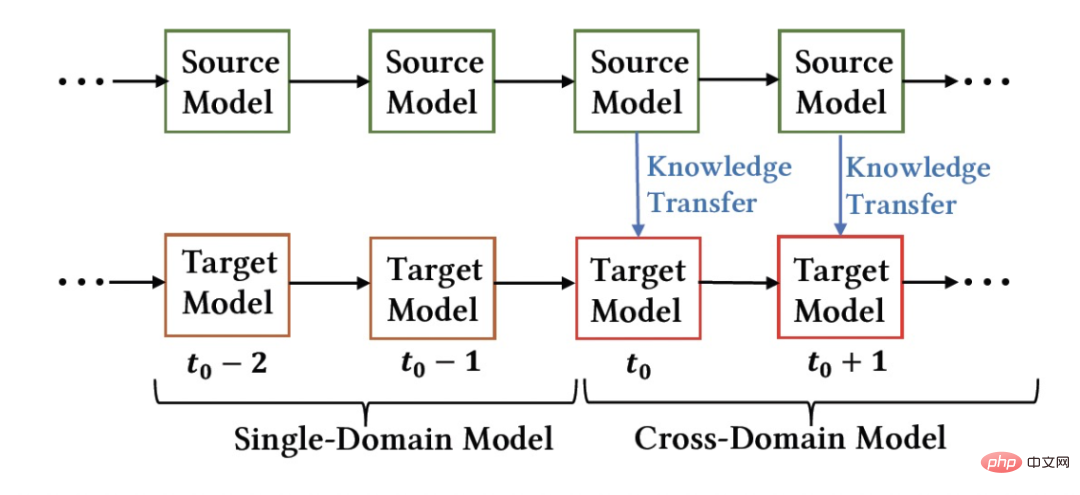
 moment, the source domain model and the target domain model were trained individually and continuously incrementally using only the supervision data of the respective scenes. Starting from the
moment, the source domain model and the target domain model were trained individually and continuously incrementally using only the supervision data of the respective scenes. Starting from the  moment, we deployed the cross-domain recommendation model CTNet on the target domain. This model will continue to increment on the target domain data without forgetting the knowledge acquired in history. training while continuously transferring knowledge from the latest source domain model.
moment, we deployed the cross-domain recommendation model CTNet on the target domain. This model will continue to increment on the target domain data without forgetting the knowledge acquired in history. training while continuously transferring knowledge from the latest source domain model. 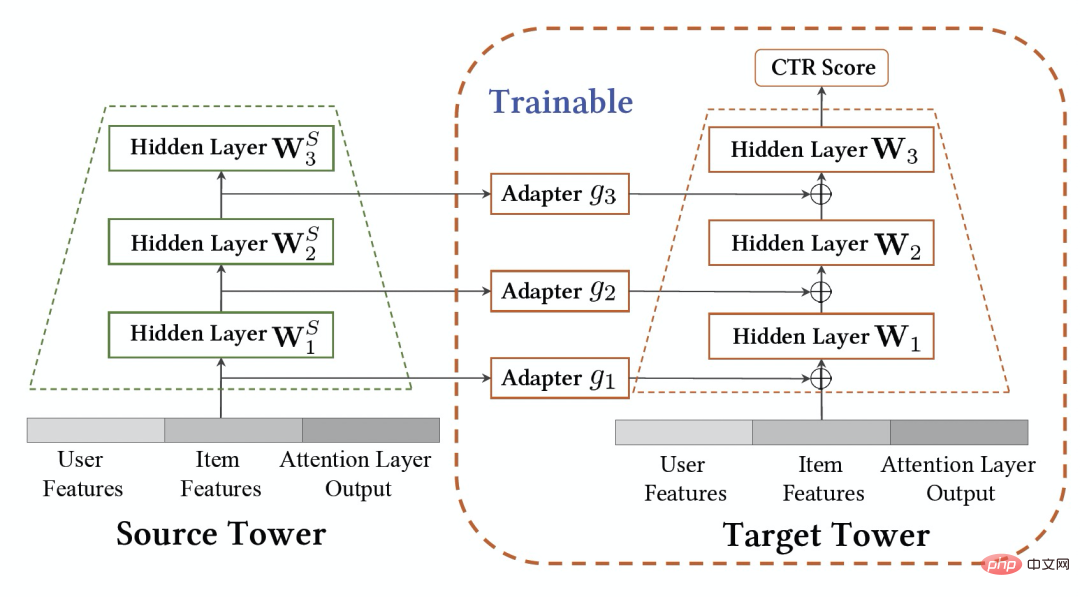
 is mapped to the target recommendation domain, and Add the result to the corresponding layer
is mapped to the target recommendation domain, and Add the result to the corresponding layer  # of Target Tower (the formula below represents the situation of
# of Target Tower (the formula below represents the situation of  ).
). 
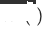 , the original single-domain recommended target domain model is
, the original single-domain recommended target domain model is 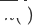 , the newly deployed target domain cross-domain recommendation model is
, the newly deployed target domain cross-domain recommendation model is 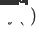 ,
, 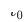 is the cross-domain recommendation model deployment online time, the The model is continuously incrementally updated to time
is the cross-domain recommendation model deployment online time, the The model is continuously incrementally updated to time 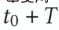 . The parameters of Adapter, Source Tower and Target Tower are
. The parameters of Adapter, Source Tower and Target Tower are 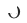 ,
, 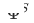 and
and 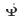 respectively. The process of CTNet training is as follows:
respectively. The process of CTNet training is as follows: 
Experiment▐ Offline effect
▐ Online effect
The above is the detailed content of Application of continuous transfer learning cross-domain recommendation ranking model in Taobao recommendation system. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Implementing Machine Learning Algorithms in C++: Common Challenges and Solutions
Jun 03, 2024 pm 01:25 PM
Common challenges faced by machine learning algorithms in C++ include memory management, multi-threading, performance optimization, and maintainability. Solutions include using smart pointers, modern threading libraries, SIMD instructions and third-party libraries, as well as following coding style guidelines and using automation tools. Practical cases show how to use the Eigen library to implement linear regression algorithms, effectively manage memory and use high-performance matrix operations.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
