
 Technology peripherals
AI
Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens
Technology peripherals
AI
Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens
Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens

ChatGPT, or the Transformer class model, has a fatal flaw, that is, it is too easy to forget. Once the token of the input sequence exceeds the context window threshold, the subsequent output content will not match the previous logic.
ChatGPT can only support the input of 4000 tokens (about 3000 words). Even the newly released GPT-4 only supports a maximum token window of 32000. If the input sequence length continues to be increased, the computational complexity will also increase. will grow quadratically.
Recently, researchers from DeepPavlov, AIRI, and the London Institute of Mathematical Sciences released a technical report using the Recurrent Memory Transformer (RMT) to increase BERT's effective context length to "an unprecedented 2 million tokens." while maintaining high memory retrieval accuracy.
Paper link: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
This method can store and process local and global information, and use loops to allow the information to be stored in each part of the input sequence. flow between segments.
The experimental section demonstrates the effectiveness of this approach, which has extraordinary potential to enhance long-term dependency processing in natural language understanding and generation tasks, enabling large-scale context processing for memory-intensive applications.
However, there is no free lunch in the world. Although RMT can not increase memory consumption and can be extended to nearly unlimited sequence lengths, there is still the problem of memory decay in RNN and longer inference time is required.

But some netizens have proposed a solution, RMT is used for long-term memory, large context is used for short-term memory, and then model training is performed at night/during maintenance.
Cyclic Memory Transformer
In 2022, the team proposed the cyclic memory Transformer (RMT) model, by adding a special memory token to the input or output sequence, and then training the model to control Memory operations and sequence representation processing can implement a new memory mechanism without changing the original Transformer model.

Paper link: https://arxiv.org/abs/2207.06881
Published conference: NeurIPS 2022
with Transformer-XL In comparison, RMT requires less memory and can handle longer sequences of tasks.
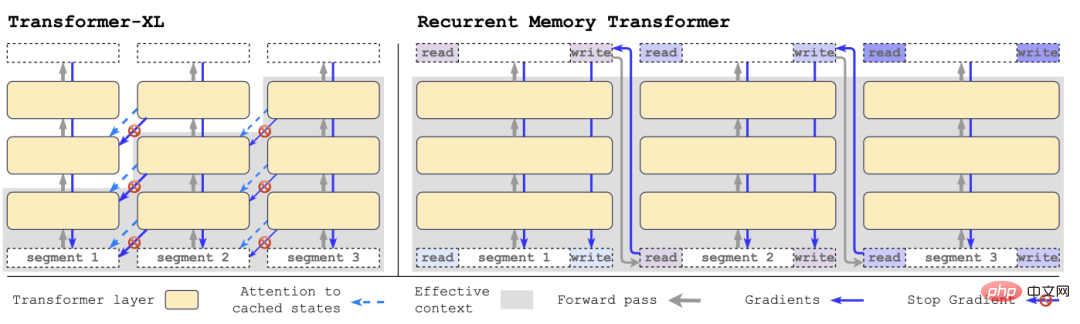
Specifically, RMT consists of m real-valued trainable vectors. The input sequence that is too long is divided into several segments, and the memory vector is preset to in the first segment embedding and processed together with the segment token.
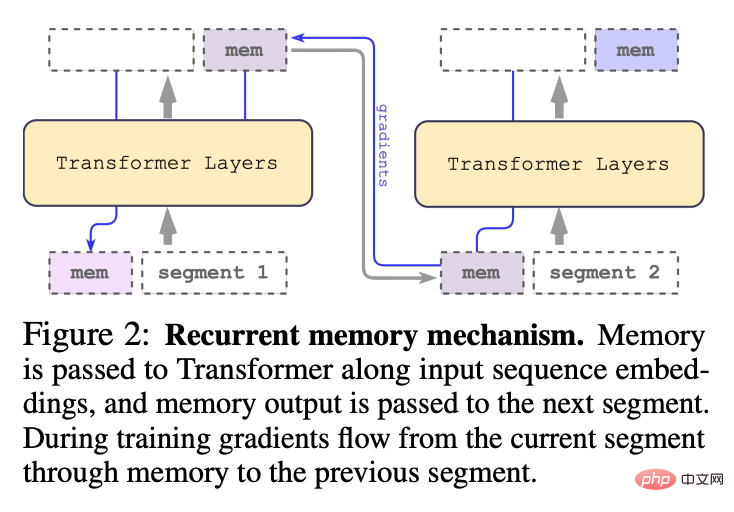
Different from the original RMT model proposed in 2022, for a pure encoder model like BERT, the memory is only added once at the beginning of the segment; the decoding model will Memory is divided into two parts: reading and writing.
In each time step and segment, loop as follows, where N is the number of Transformer layers, t is the time step, and H is the segment
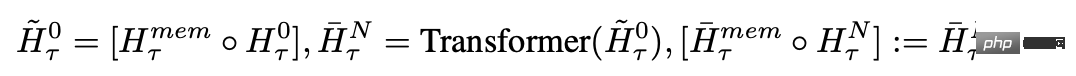
After processing the segments of the input sequence in order, in order to achieve recursive connection, the researcher passes the output of the memory token of the current segment to the input of the next segment:
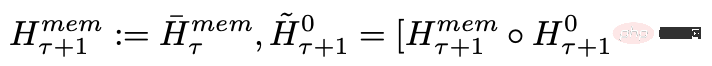
The memory and loop in RMT are only based on global memory tokens, which can keep the backbone Transformer model unchanged, making RMT's memory enhancement capability compatible with any Transformer model.
Computational efficiency
According to the formula, the FLOPs required for RMT and Transformer models of different sizes and sequence lengths can be estimated
In terms of vocabulary size, number of layers, hidden size, and intermediate Regarding the parameter configuration of the hidden size and number of attention heads, the researchers followed the configuration of the OPT model and calculated the number of FLOPs after the forward pass, taking into account the impact of the RMT cycle.
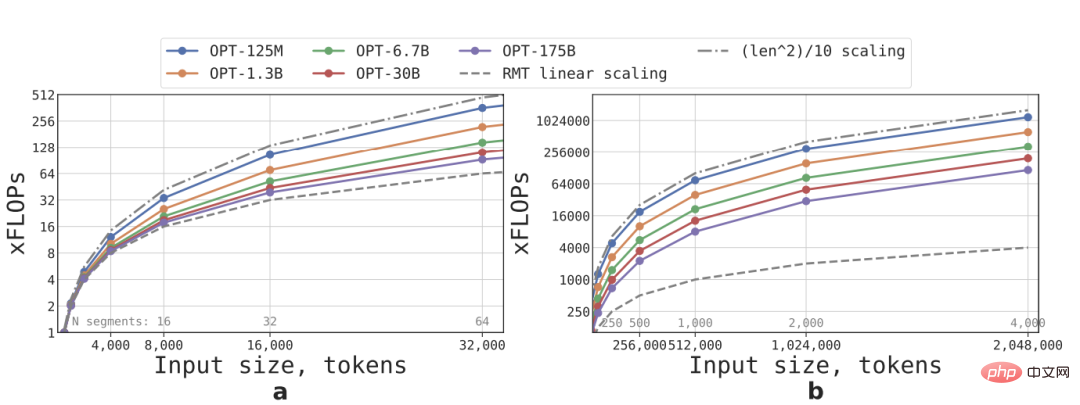
Linear expansion is achieved by dividing an input sequence into several segments and calculating the entire attention matrix only within the boundaries of the segment. The result can be seen that if the segment length Fixed, the inference speed of RMT increases linearly for any model size.
Due to the large amount of calculation of the FFN layer, larger Transformer models tend to show a slower quadratic growth rate relative to the sequence length. However, on extremely long sequences with a length greater than 32,000, FLOPs return to quadratic. state of growth.
For sequences with more than one segment (larger than 512 in this study), RMT has lower FLOPs than acyclic models, and can increase the efficiency of FLOPs by up to ×295 times on smaller models. ; In larger models such as OPT-175B, it can be increased by ×29 times.
Memory Task
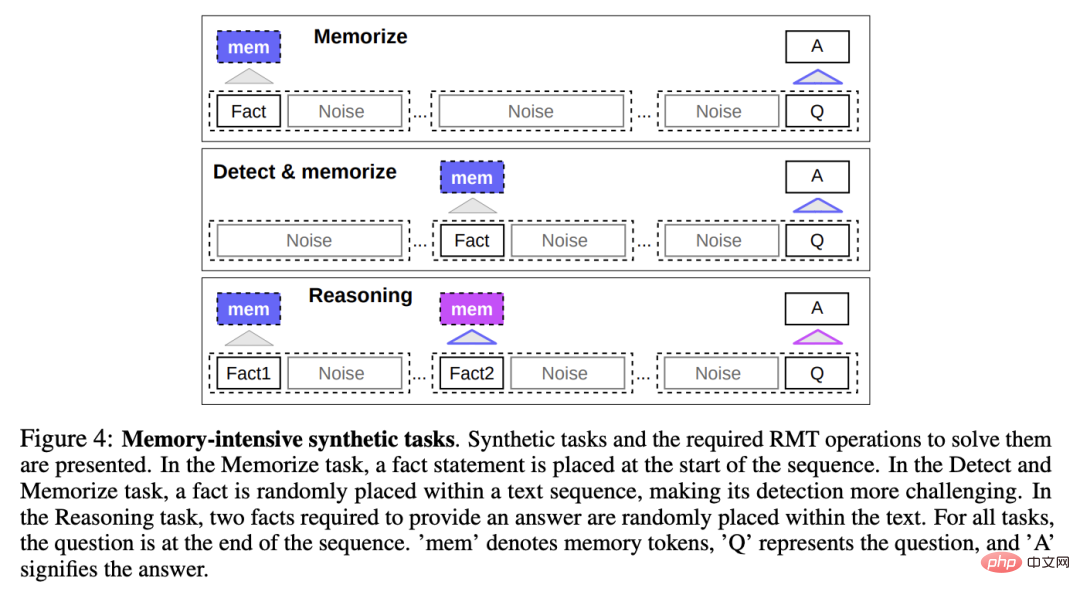
To test memory abilities, the researchers constructed a synthetic dataset that required the model to memorize simple facts and basic reasoning.
Task input consists of one or several facts and a question that can only be answered with all of these facts.
In order to increase the difficulty of the task, natural language text that is not related to the question or answer is also added to the task. These texts can be regarded as noise, so the task of the model is actually to separate the facts from the irrelevant text. , and use factual text to answer questions.

Factual Memory
Test RMT writes and stores information in memory for long periods of time Power: In the simplest case, the facts are at the beginning of the input, the questions are at the end of the input, and gradually increase the amount of irrelevant text between questions and answers until the model cannot accept all the input at once.

Fact detection and memory
Fact detection increases the difficulty of the task by moving the fact to a random position in the input, requiring The model first separates facts from irrelevant text, writes them into memory, and then answers the question at the end.
Reasoning based on memorized facts
Another important operation of memory is to use memorized facts and the current context to reason.
To evaluate this feature, the researchers introduced a more complex task in which two facts are generated and randomly placed in the input sequence; a question asked at the end of the sequence must be chosen to answer the question with the correct fact .

Experimental results
The researchers used the pre-trained Bert-base-cased model in HuggingFace Transformers as the backbone of RMT in all experiments, and all models were based on memory Enhanced with a size of 10.
Train and evaluate on 4-8 NVIDIA 1080Ti GPUs; for longer sequences, switch to a single 40GB NVIDIA A100 for accelerated evaluation.
Curriculum Learning
The researchers observed that using training scheduling can significantly improve the accuracy and stability of the solution.
Initially let RMT train on a shorter task version. After the training converges, increase the task length by adding a segment, and continue the course learning process until the ideal input length is reached.
Start the experiment with a sequence that fits a single segment. The actual segment size is 499 because 3 BERT's special markers and 10 memory placeholders are retained from the model input, giving a total size of 512.
It can be noticed that after training on shorter tasks, RMT is easier to solve longer tasks because it converges to a perfect solution using fewer training steps.
Extrapolation Abilities
In order to observe the generalization ability of RMT to different sequence lengths, the researchers evaluated models trained on different numbers of segments. , to solve tasks of greater length.
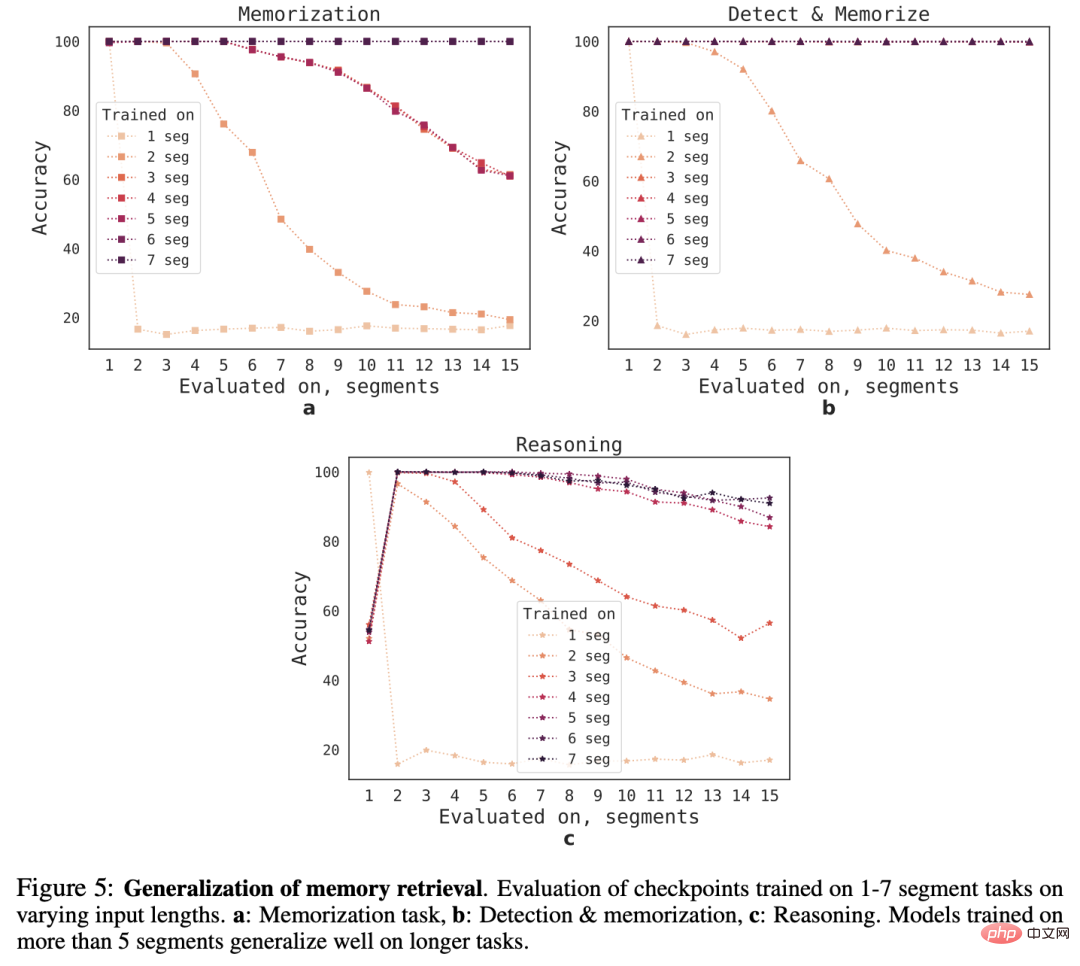
It can be observed that the model often performs well on shorter tasks, but after training the model on a longer sequence, it becomes difficult to handle single-segment inference tasks.
One possible explanation is that because the task size exceeds one segment, the model stops anticipating the problem in the first segment, resulting in a decline in quality.
Interestingly, as the number of training segments increases, RMT's generalization ability to longer sequences also appears. After training on 5 or more segments, RMT can handle twice as long sequences. nearly perfect generalization of tasks.
In order to test the limit of generalization, the researchers increased the size of the verification task to 4096 segments (i.e. 2,043,904 tokens).
RMT holds up surprisingly well on such long sequences, of which the "detection and memory" task is the simplest and the inference task is the most complex.
Reference materials: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
The above is the detailed content of Completely solve ChatGPT amnesia! Breaking through the Transformer input limit: measured to support 2 million valid tokens. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
