
 Operation and Maintenance
Linux Operation and Maintenance
How to use the Linux automated build tools make and Makefile
Operation and Maintenance
Linux Operation and Maintenance
How to use the Linux automated build tools make and Makefile
How to use the Linux automated build tools make and Makefile

1. The role of make and Makefile
The source files in a project are not counted. They are placed in several directories according to type, function, and module. The makefile defines a series of rules to specify , which files need to be compiled first, which files need to be compiled later, which files need to be recompiled, and even more complex functional operations can be performed.
So, the benefit brought by makefile is - "Automatic compilation". Once written, only one make command is needed, and the entire project is completely automatically compiled, which greatly improves the efficiency. Software development efficiency.
make is a command tool that interprets the instructions in the makefile. Generally speaking, most IDEs have this command, such as: Delphi's make, Visual C's nmake, and GNU's under Linux. make. It can be seen that makefile has become a compilation method in engineering. make is a command and makefile is a file. Use both together to complete the automated construction of the project.
2. Use of make and Makefile
Before understanding dependencies and dependency methods, let’s write a small program in C language.
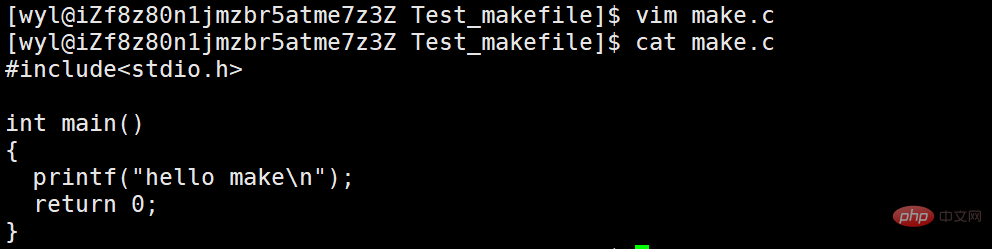
We created a make.c file and wrote a hello make code.
Then let’s create another Makefile (makefile is also possible, but not recommended).
Then we edit the Makefile and write the following code:
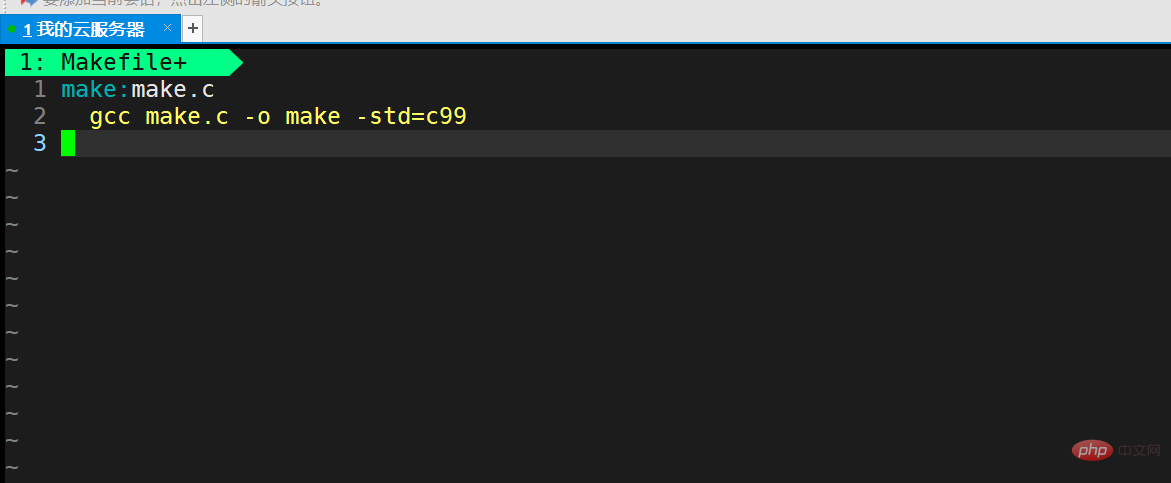
Then we save and exit.
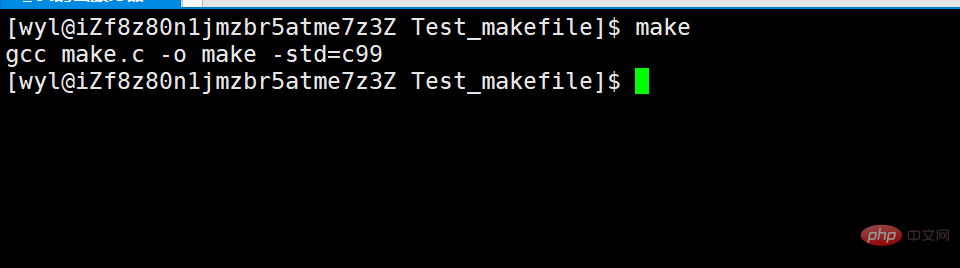
Then we can execute the make command. If it prompts that make does not exist, it is because it is not installed. You can switch to install as root. Installation code: yum install make or sudo install make.
After executing make normally, the following display will appear.
Then we will view the files in the current directory.
We can find that there is an additional executable program make. Then let’s try running ./make.
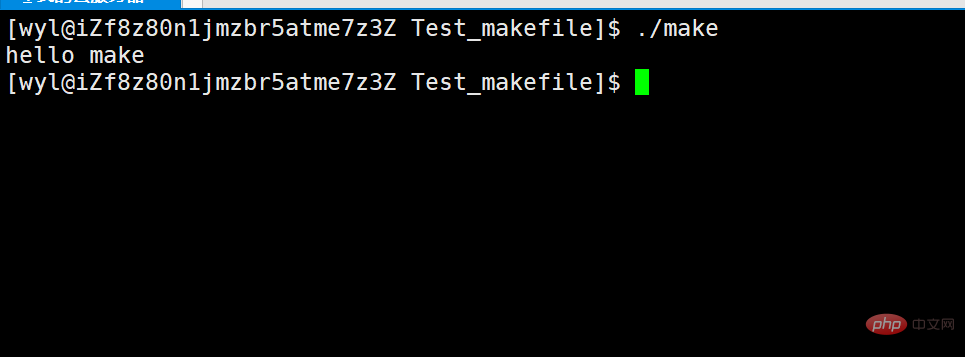
We will find that this executable program outputs make.
This is our automated build tool, which only needs to be configured in the Makefile. Then type make directly to compile the code. Then let’s try typing make again.

prompts us that the make program is the latest. That is, if you haven't modified or updated the program. Then it will not be compiled for you because your program has not been touched. Why compile it?
Now let’s go back and analyze the code written in the Makefile.

First we divide it into three parts
make
make.c
gcc make.c -o make -std=c99
The relationship between the three is that make depends on make .c generated. The two of them have a dependency relationship, and gcc make.c -o make -std=c99 is the method that make depends on make.c, called dependency method.
What are dependencies and dependency methods?
An analogy.
It’s the end of the month and your living expenses are gone. At this time, you call your dad and tell him: "Dad, it's the end of the month. I have no money." Your father will know at this time and will give you living expenses. Here, you and your father have a father-son relationship, so you are dependent on your father, and there is a dependence relationship between you. And your father gives you living expenses, which is a way for you to rely on your father, so this is Dependence Method. If you call your roommate's father to ask for living expenses at this time, he will tell you to get out. Because you don't have a dependency relationship at all. If you don't have a dependency relationship, there will be no dependency method.
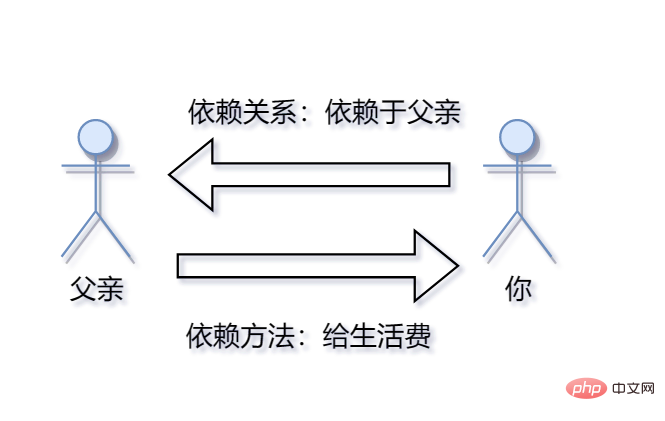
So my program is the same. make is the generated executable program. And it depends on make.c because it is compiled from make.c. The dependent method is to execute the command gcc make.c -o make -std=c99.
The principle of dependency
make will look for a file named "Makefile" or "makefile" in the current directory.
If found, it will find the first target file (target) in the file. In the above example, it will find the file "hello" and use this file as the final target. document.
If the hello file does not exist, or the file modification time of the subsequent test.o file that hello depends on is newer than the test file (you can use touch to test), then, he The command defined later will be executed to generate the test file.
If the test.o file that test depends on does not exist, then make will look for the dependency of the test.o file in the current file. If it is found, it will follow that rule. Generate test.o file. (This is a bit like a stack process)
Of course, your C file and H file exist, so make will generate the test.o file, and then use test.o The file declares the ultimate task of make, which is to execute the file test.
This is the dependency of the entire make. Make will look for file dependencies layer by layer until the first target file is finally compiled.
During the search process, if an error occurs, for example, the last dependent file cannot be found, then make will exit directly and report an error, and for the error of the defined command , or the compilation is unsuccessful, make simply ignores it.
make only cares about the dependencies of files, that is, if after I find the dependencies, the file after the colon is still not there, then I'm sorry, I won't work.
Cleaning
When we usually write code, we often need to compile and execute the code repeatedly.
Before recompiling next time, you need to clean up the executable program generated last time. However, you may make a mistake during cleaning and accidentally delete the source file, which may cause problems again.
So do we have a solution? The answer is of course.
We continue to edit the Makefile.
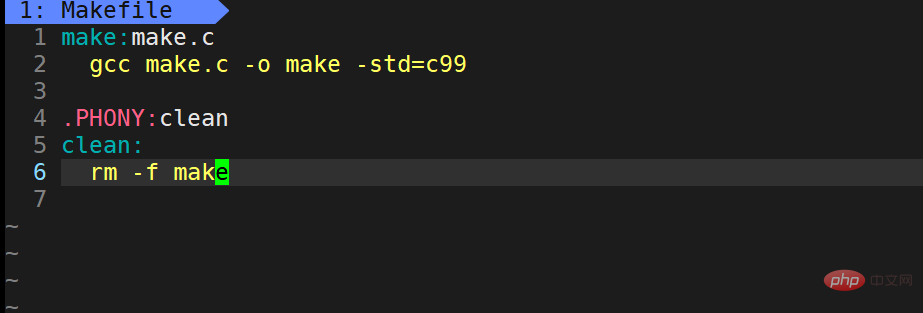
We added
.PHONY:clean clean: rm -f make
on the original basis. So what is the role of PHONY?
.PHONY is modified with a pseudo target, and the pseudo target is always executed. clean is a self-defined make command. The usage method is make clean
Then let’s try this command
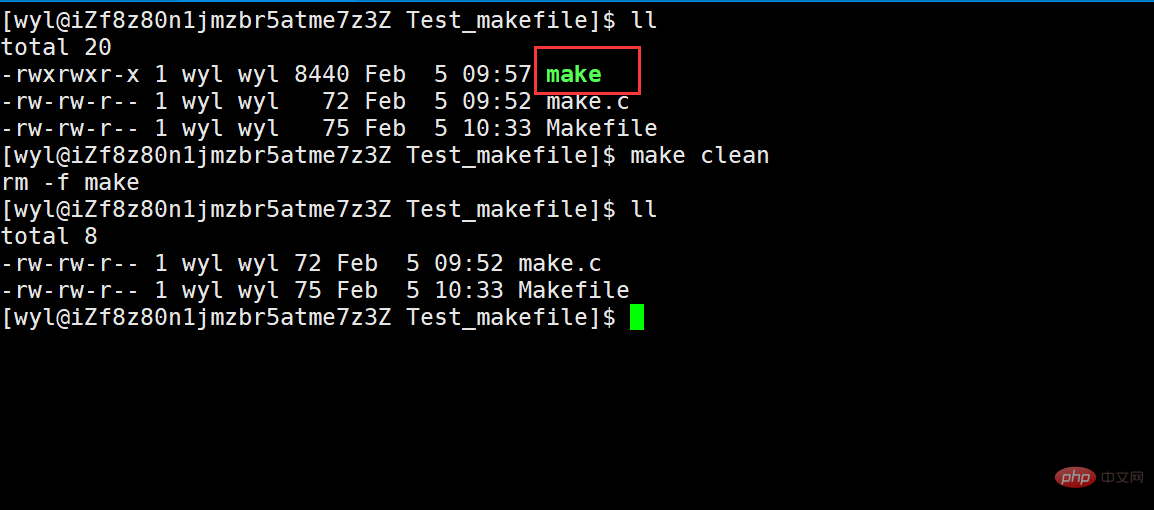
We can see that it has been cleaned up, so why is the pseudo target always executed? Let's run it multiple times and see.
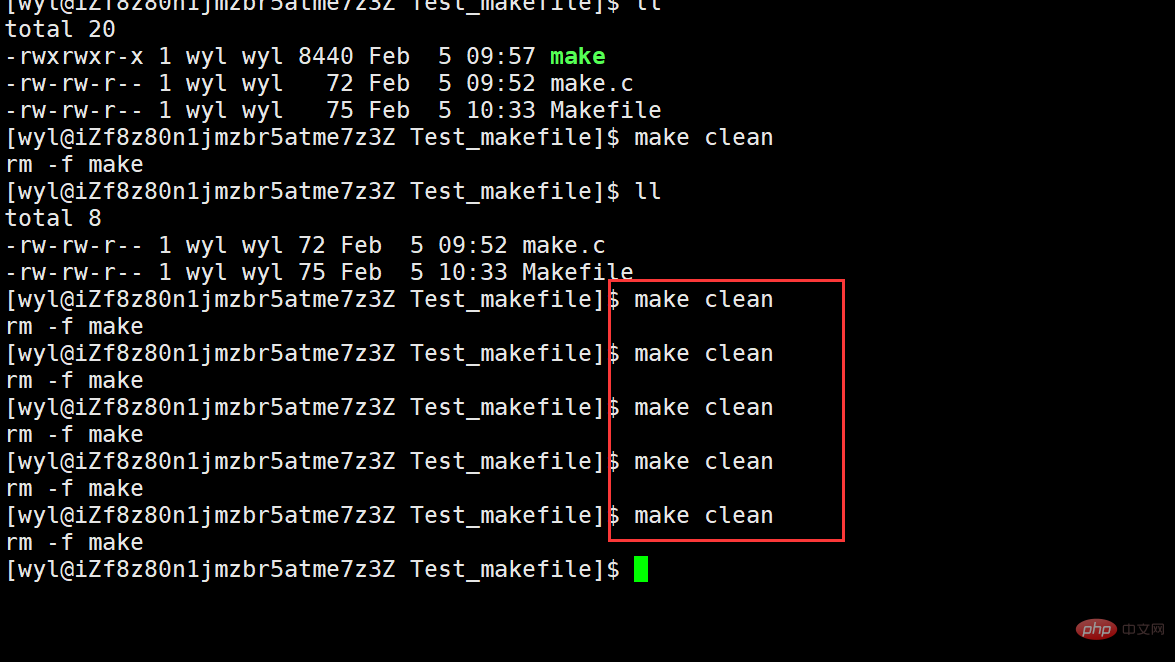
We can execute it all the time, so what if we execute make multiple times?
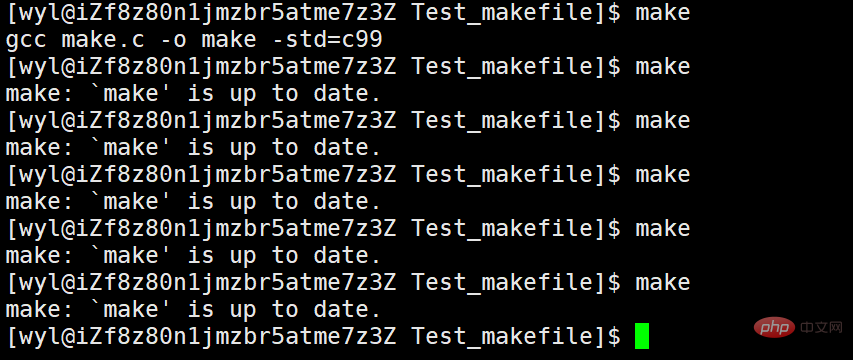
We will find that after make is executed once, it cannot be executed because it is not modified by .PHONY. Then I modify it with .PHONY and try again.
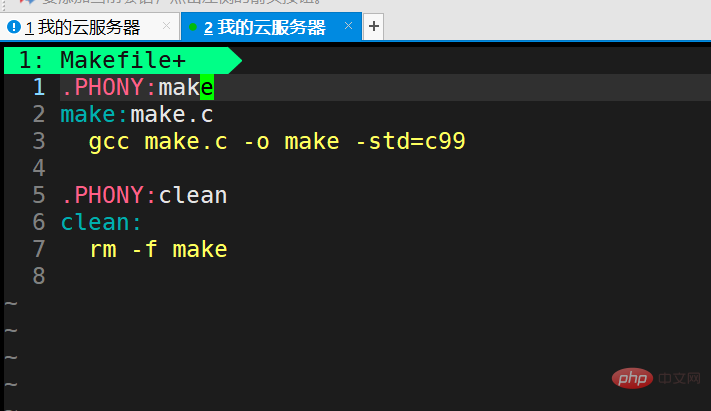
Then we save and exit, execute make
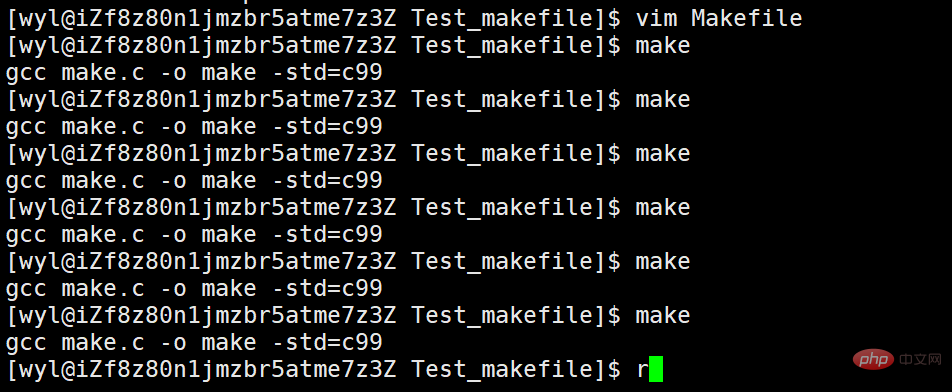
# we can see It was performed many times. But I don't think this is necessary, because the file has not been modified. Recompiling makes no sense, so it is not recommended to add .PHONY
to automated compilation. We save and exit, and execute make
# multiple times.
.PHONY to automated compilation.
The above is the detailed content of How to use the Linux automated build tools make and Makefile. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
What is Linux actually good for?
Apr 12, 2025 am 12:20 AM
Linux is suitable for servers, development environments, and embedded systems. 1. As a server operating system, Linux is stable and efficient, and is often used to deploy high-concurrency applications. 2. As a development environment, Linux provides efficient command line tools and package management systems to improve development efficiency. 3. In embedded systems, Linux is lightweight and customizable, suitable for environments with limited resources.
 How to start apache
Apr 13, 2025 pm 01:06 PM
How to start apache
Apr 13, 2025 pm 01:06 PM
The steps to start Apache are as follows: Install Apache (command: sudo apt-get install apache2 or download it from the official website) Start Apache (Linux: sudo systemctl start apache2; Windows: Right-click the "Apache2.4" service and select "Start") Check whether it has been started (Linux: sudo systemctl status apache2; Windows: Check the status of the "Apache2.4" service in the service manager) Enable boot automatically (optional, Linux: sudo systemctl
 What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
What to do if the apache80 port is occupied
Apr 13, 2025 pm 01:24 PM
When the Apache 80 port is occupied, the solution is as follows: find out the process that occupies the port and close it. Check the firewall settings to make sure Apache is not blocked. If the above method does not work, please reconfigure Apache to use a different port. Restart the Apache service.
 How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
How to monitor Nginx SSL performance on Debian
Apr 12, 2025 pm 10:18 PM
This article describes how to effectively monitor the SSL performance of Nginx servers on Debian systems. We will use NginxExporter to export Nginx status data to Prometheus and then visually display it through Grafana. Step 1: Configuring Nginx First, we need to enable the stub_status module in the Nginx configuration file to obtain the status information of Nginx. Add the following snippet in your Nginx configuration file (usually located in /etc/nginx/nginx.conf or its include file): location/nginx_status{stub_status
 How to start monitoring of oracle
Apr 12, 2025 am 06:00 AM
How to start monitoring of oracle
Apr 12, 2025 am 06:00 AM
The steps to start an Oracle listener are as follows: Check the listener status (using the lsnrctl status command) For Windows, start the "TNS Listener" service in Oracle Services Manager For Linux and Unix, use the lsnrctl start command to start the listener run the lsnrctl status command to verify that the listener is started
 How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
How to set up a recycling bin in Debian system
Apr 12, 2025 pm 10:51 PM
This article introduces two methods of configuring a recycling bin in a Debian system: a graphical interface and a command line. Method 1: Use the Nautilus graphical interface to open the file manager: Find and start the Nautilus file manager (usually called "File") in the desktop or application menu. Find the Recycle Bin: Look for the Recycle Bin folder in the left navigation bar. If it is not found, try clicking "Other Location" or "Computer" to search. Configure Recycle Bin properties: Right-click "Recycle Bin" and select "Properties". In the Properties window, you can adjust the following settings: Maximum Size: Limit the disk space available in the Recycle Bin. Retention time: Set the preservation before the file is automatically deleted in the recycling bin
 How to restart the apache server
Apr 13, 2025 pm 01:12 PM
How to restart the apache server
Apr 13, 2025 pm 01:12 PM
To restart the Apache server, follow these steps: Linux/macOS: Run sudo systemctl restart apache2. Windows: Run net stop Apache2.4 and then net start Apache2.4. Run netstat -a | findstr 80 to check the server status.
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
