
 Technology peripherals
AI
OpenAI's new generation model is an open source explosion! Faster and stronger than Diffusion, a work by Tsinghua alumnus Song Yang
Technology peripherals
AI
OpenAI's new generation model is an open source explosion! Faster and stronger than Diffusion, a work by Tsinghua alumnus Song Yang
OpenAI's new generation model is an open source explosion! Faster and stronger than Diffusion, a work by Tsinghua alumnus Song Yang

The field of image generation seems to be changing again.
Just now, OpenAI open sourced a consistency model that is faster and better than the diffusion model:
You can generate high-quality images without adversarial training!
As soon as this blockbuster news was released, it immediately detonated the academic circle.

Although the paper itself was released in a low-key manner in March, at that time it was generally believed that it was just a cutting-edge research of OpenAI and the details would not really be made public.

Unexpectedly, an open source came directly this time. Some netizens immediately started testing the effect and found that it only takes about 3.5 seconds to generate about 64 256×256 images:
Game over!

This is the image effect generated by this netizen, it looks pretty good:

Also Netizens joked: This time OpenAI is finally open!

It is worth mentioning that the first author of the paper, OpenAI scientist Song Yang, is a Tsinghua alumnus. At the age of 16, he entered Tsinghua’s basic mathematics and science class through the Leadership Program.
Let’s take a look at what kind of research OpenAI has open sourced this time.
What kind of blockbuster research has been open sourced?
As an image generation AI, the biggest feature of the Consistency Model is that it is fast and good.
Compared with the diffusion model, it has two main advantages:
First, it can directly generate high-quality image samples without adversarial training.
Secondly, compared to the diffusion model which may require hundreds or even thousands of iterations, the consistency model only needs one or two steps to handle a variety of image tasks - including coloring, Denoising, super-scoring, etc., can all be done in a few steps without requiring explicit training for these tasks. (Of course, if few-sample learning is performed, the generation effect will be better)
 So how does the consistency model achieve this effect?
So how does the consistency model achieve this effect?
From a principle point of view, the birth of the consistency model is related to the ODE (ordinary differential equation) generation diffusion model.
As can be seen in the figure, ODE will first convert the image data into noise step by step, and then perform a reverse solution to learn to generate images from the noise.
In this process, the authors tried to map any point on the ODE trajectory (such as Xt, Xt and Xr) to its origin (such as X0) for generative modeling.
Subsequently, this mapped model was named the consistency model because their outputs are all at the same point on the same trajectory:
 Based on this The idea is that the consistency model no longer needs to go through long iterations to generate a relatively high-quality image, but can be generated in one step.
Based on this The idea is that the consistency model no longer needs to go through long iterations to generate a relatively high-quality image, but can be generated in one step.
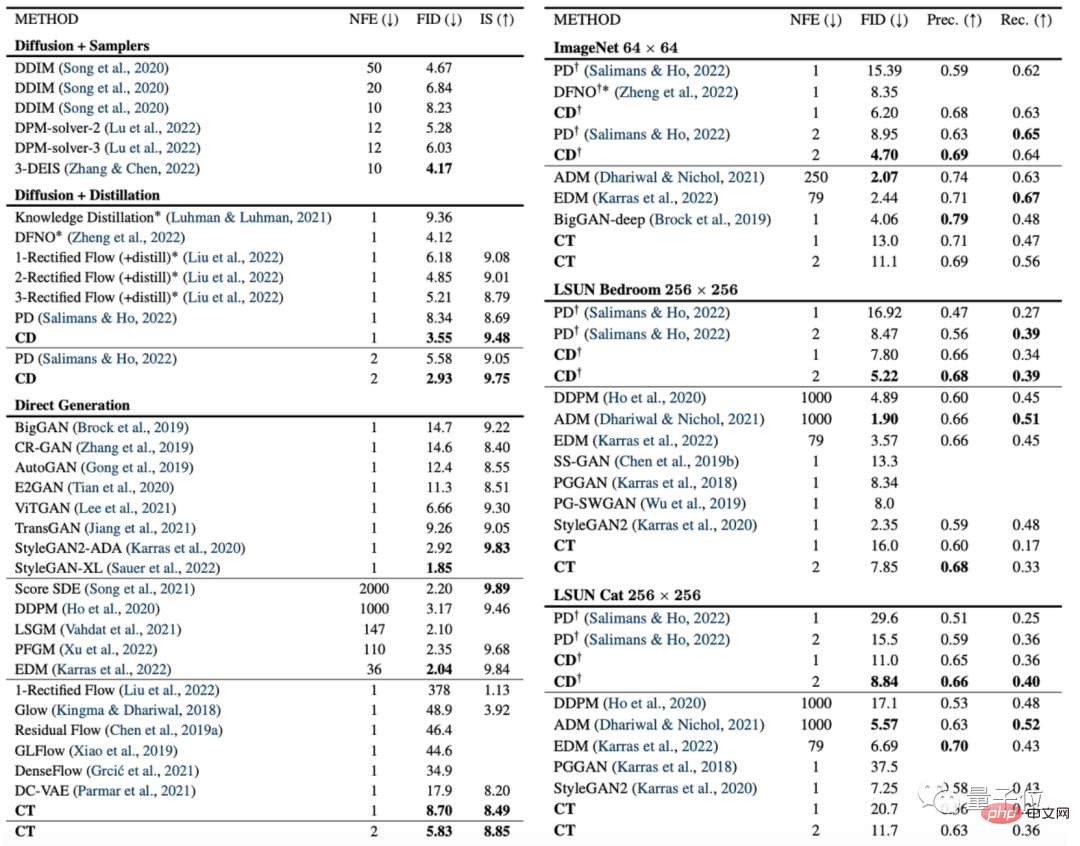
The following figure is a comparison of the consistency model (CD) and the diffusion model (PD) on the image generation index FID.
Among them, PD is the abbreviation of progressive distillation (progressive distillation), a latest diffusion model method proposed by Stanford and Google Brain last year, and CD (consistency distillation) is the consistency distillation method.
It can be seen that in almost all data sets, the image generation effect of the consistency model is better than that of the diffusion model. The only exception is the 256×256 room data set:
 In addition, the authors also compared diffusion models, consistency models, GAN and other models on various other data sets:
In addition, the authors also compared diffusion models, consistency models, GAN and other models on various other data sets:
However, some netizens mentioned that the images generated by the open source AI consistency model are still too small:
It’s sad that this open source The images generated by the version are still too small. It would be very exciting if an open source version that generates larger images could be provided.
# Some netizens also speculated that OpenAI may not have been trained yet. But maybe after training, we may not be able to get the code (manual dog head).
But regarding the significance of this work, TechCrunch said:
If you have a bunch of GPUs, then use the diffusion model to iterate more than 1,500 times in a minute or two, and the effect of generating images will certainly be extremely good. OK
But if you want to generate images in real time on your mobile phone or during a chat conversation, then obviously the diffusion model is not the best choice.
The consistency model is the next important move of OpenAI.
I hope OpenAI will open source a wave of image generation AI with higher resolution~
Tsinghua alumnus Song Yang is the first author of the paper
Song Yang is the first author of the paper and is currently a research scientist at OpenAI.

#When he was 14 years old, he was selected into the "Tsinghua University New Centenary Leadership Program" with unanimous votes from 17 judges. In the college entrance examination the following year, he became the top scorer in science in Lianyungang City and was successfully admitted to Tsinghua University.
In 2016, Song Yang graduated from Tsinghua University’s basic mathematics and physics class, and then went to Stanford for further study. In 2022, Song Yang received a PhD in computer science from Stanford and then joined OpenAI.
During his doctoral period, his first paper "Score-Based Generative Modeling through Stochastic Differential Equations" also won the ICLR 2021 Outstanding Paper Award.

According to information on his personal homepage, starting from January 2024, Song Yang will officially join the Department of Electronics and Department of Computational Mathematical Sciences at the California Institute of Technology as an assistant professor.
Project address:
https://www.php.cn/link/4845b84d63ea5fa8df6268b8d1616a8f
Paper address:
https://www.php.cn/link/5f25fbe144e4a81a1b0080b6c1032778
Reference link:
[1]https://twitter.com/alfredplpl/status/1646217811898011648
[2]https://twitter.com/_akhaliq/status/1646168119658831874
The above is the detailed content of OpenAI's new generation model is an open source explosion! Faster and stronger than Diffusion, a work by Tsinghua alumnus Song Yang. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
