
 Technology peripherals
AI
Chinese team subverts CV! SEEM perfectly divides all explosions and divides the 'instantaneous universe' with one click
Technology peripherals
AI
Chinese team subverts CV! SEEM perfectly divides all explosions and divides the 'instantaneous universe' with one click
Chinese team subverts CV! SEEM perfectly divides all explosions and divides the 'instantaneous universe' with one click

The emergence of Meta’s “Divide Everything” made many people exclaim that CV no longer exists.
Based on this model, many netizens have done further work, such as Grounded SAM.
By combining Stable Diffusion, Whisper, and ChatGPT, you can turn a dog into a monkey through voice.

And now, not just voice, you can segment everything everywhere at once through multi-modal prompts .
How to do it specifically?
Click the mouse to directly select the split content.

Open your mouth and say a word.

Just swipe it and the complete emoticon package will be there.

Even, you can even split the video.

The latest research on SEEM was jointly completed by scholars from the University of Wisconsin-Madison, Microsoft Research and other institutions.
Easily segment images with SEEM using different kinds of cues, visual cues (dots, marks, boxes, doodles, and image fragments), as well as verbal cues (text and audio).

Paper address: https://arxiv.org/pdf/2304.06718.pdf
The interesting thing about the title of this paper is that it is very similar to the name of an American science fiction movie "Everything Everywhere All at Once" released in 2022.

NVIDIA scientist Jim Fan said that the Oscar for best paper title goes to "Segment Everything Everywhere All at Once"
Having a unified, versatile task specification interface is key to scaling up large base models. Multimodal prompts are the way of the future.

After reading the paper, netizens said that CV will now begin to embrace large models. What is the future for graduate students? ?

Oscar Best Title Paper
was inspired by the development of a common interface for LLMs based on prompts , the researchers proposed SEEM.
As shown in the figure, the SEEM model can perform any segmentation task in the open set without hints, such as semantic segmentation, instance segmentation and panoramic segmentation.
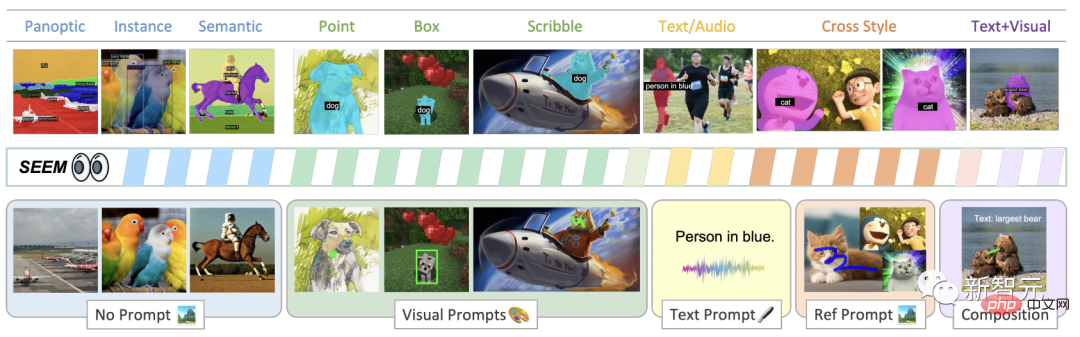
Additionally, it supports any combination of visual, textual and reference area prompts, allowing for versatile and interactive Reference splitting.
In terms of model architecture, SEEM adopts a common encoder-decoder architecture. What makes it unique is the complex interaction between queries and prompts.
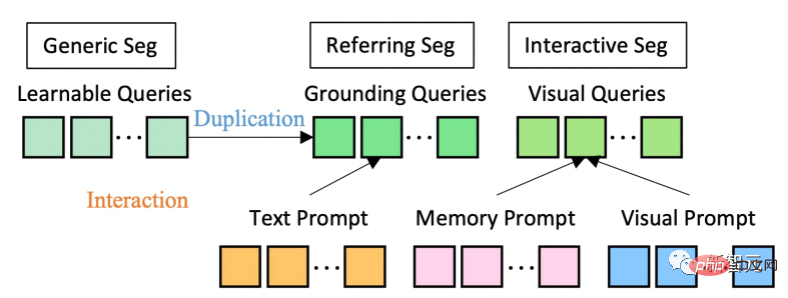
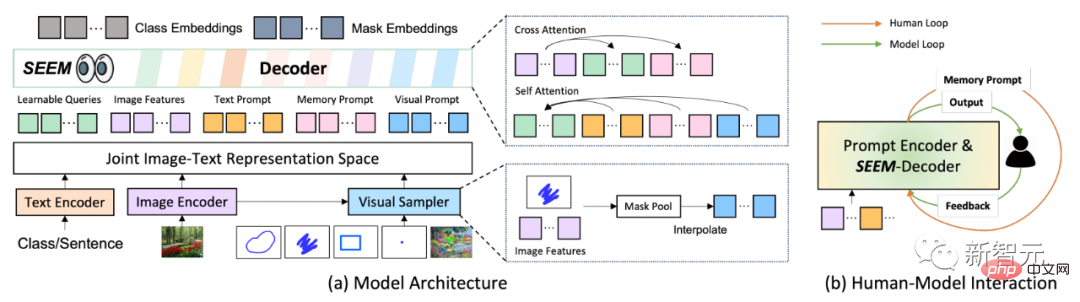
Features and cues are encoded into a joint visual semantic space by corresponding encoders, or samplers.
Learnable queries are randomly initialized, and the SEEM decoder accepts learnable queries, image features, and textual cues as input and output, including class and mask embeddings for masks and semantics predict.
It is worth mentioning that the SEEM model has multiple rounds of interactions. Each round consists of a manual cycle and a model cycle.
In the manual loop, the mask output of the previous iteration is manually received and positive feedback for the next round of decoding is given through visual cues. In the model loop, the model receives and updates memory cues for future predictions.
Through SEEM, given a picture of Optimus Prime’s truck, you can segment Optimus Prime on any target image .

Generate a mask from the text entered by the user for one-click segmentation.

In addition, SEEM can add similar semantics to the target image by simply clicking or graffiti on the reference image. objects are segmented.

In addition, SEEM understands solution space relationships very well. After the zebras in the upper left row are graffitied, the leftmost zebra will also be segmented.

SEEM can also reference images to video masks. It does not require any video data training and can perfectly segment videos. .


## On the data set and settings, SEEM Three datasets were trained: panoramic segmentation, reference segmentation and interactive segmentation.
Interactive segmentation
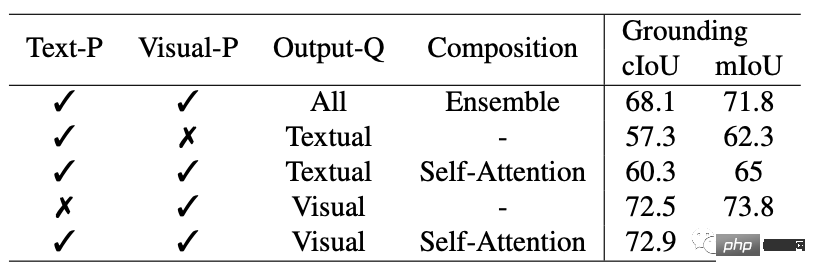
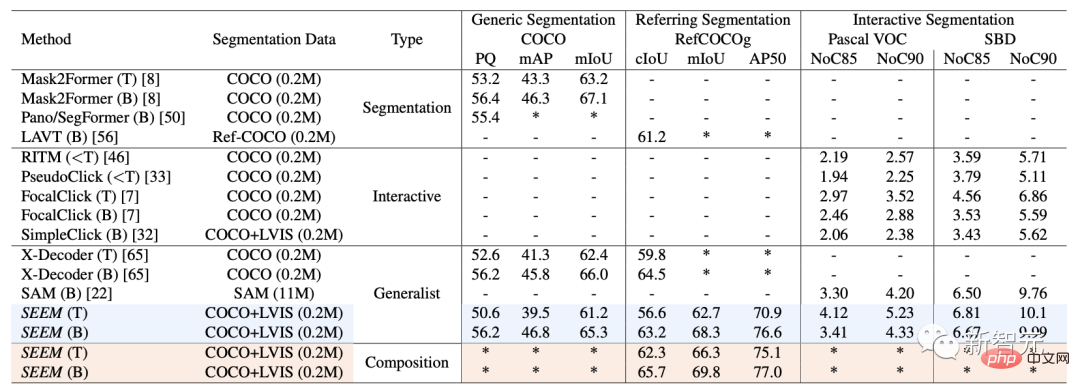
On interactive segmentation, researchers compared SEEM with state-of-the-art interactive segmentation models.
As a general model, SEEM has achieved comparable performance to RITM, SimpleClick, etc. And it achieves very similar performance to SAM. SAM also uses 50 more segmented data for training.
Notably, unlike existing interactive models, SEEM is the first to support not only classic segmentation tasks but also a wide range of multi-modal inputs, including text , points, scribbles, bounding boxes and images, providing powerful combination capabilities.
##Universal segmentation
pass all A set of parameters pre-trained for segmentation tasks, allowing researchers to directly evaluate its performance on common segmentation datasets.
SEEM achieves better panoramic view, instance and semantic segmentation performance.
1 . Versatility: By introducing a versatile hint engine to handle different types of hints, including points, boxes, graffiti, masks, text and reference areas of another image;
2. Complexity: By learning a joint visual-semantic space, visual and textual cues can be combined for instant query reasoning;
3. Interactivity: By integrating learnable memory cues, through masking Code-guided cross-attention preserves conversation history information;
4. Semantic awareness: Open vocabulary segmentation is achieved by using a text encoder to encode text queries and mask tags.
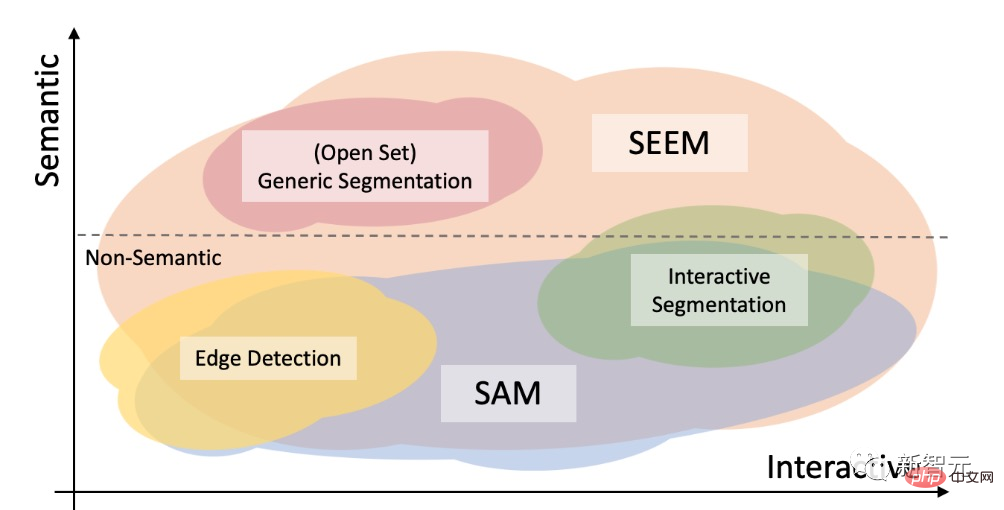
The difference between SAM and SAM
#The SAM model proposed by Meta can be specified in a unified framework prompt encoder. Points, a bounding box, and a sentence can segment objects with one click.


In open set segmentation, high-level semantics are also required and no interaction is required.
Compared with SAM, SEEM covers a wider range of interactions and semantic levels.
SAM only supports limited interaction types, such as points and bounding boxes, and ignores high semantic tasks because it does not output semantic labels itself.
For SEEM, researchers have highlighted two highlights:
First, SEEM has a unified prompt encoder that combines all Visual and verbal cues are encoded into a joint representation space. Therefore, SEEM can support more general usage, and it can potentially be extended to custom prompts.
Secondly, SEEM does a good job at text masking and output semantic-aware predictions.
Introduction to the author
The first author of the paper Xueyan Zou
She is currently a doctoral student in the Department of Computer Science at the University of Wisconsin-Madison, under the supervision of Professor Yong Jae Lee.
Prior to this, Zou spent three years at the University of California, Davis, under the guidance of the same mentor and worked closely with Dr. Fanyi Xiao.
She received her bachelor's degree from Hong Kong Baptist University, supervised by Professor PC Yuen and Professor Chu Xiaowen.

##Jianwei Yang

Yang is a senior researcher in the deep learning group of Microsoft Research in Redmond, supervised by Dr. Jianfeng Gao.
Yang’s research mainly focuses on computer vision, vision and language, and machine learning. He focuses on different levels of structured visual understanding and how they can be further exploited for intelligent interaction with humans through language and environmental embodiment.
Before joining Microsoft in March 2020, Yang received his PhD in Computer Science from Georgia Tech’s School of Interactive Computing, where his advisor was Professor Devi Parikh, and he also worked with Professor Dhruv Batra Work closely together.
Gao Jianfeng

Currently, Gao Jianfeng leads the deep learning group. The group's mission is to advance the state-of-the-art of deep learning and its applications in natural language and image understanding, and to make advances in conversation models and methods.
Research mainly includes neural language models for natural language understanding and generation, neural symbolic computing, the foundation and understanding of visual language, conversational artificial intelligence, etc.
From 2014 to 2018, Gao Jianfeng served as a partner research manager for commercial artificial intelligence in the Microsoft Artificial Intelligence and Research Department and the Deep Learning Technology Center (DLTC) of Redmond Microsoft Research.
From 2006 to 2014, Gao Jianfeng served as the chief researcher in the natural language processing group.
Yong Jae Lee

Before joining UW-Madison in the fall of 2021, he served as a visiting instructor in artificial intelligence at Cruise for a year, and before that he was at the University of California, Davis Served as assistant and associate professor for 6 years.
He also spent a year as a postdoctoral researcher at the Robotics Institute at Carnegie Mellon University.
He received his PhD from the University of Texas at Austin in May 2012 with Kristen Grauman, and from the University of Illinois at Urbana-Champaign in May 2006 Bachelor's degree.
He also worked as a summer intern at Microsoft Research with Larry Zitnick and Michael Cohen.
Currently, Lee’s research focuses on computer vision and machine learning. Lee is particularly interested in creating powerful visual recognition systems that can understand visual data with minimal human supervision. Currently, SEEM has opened a demo: https://huggingface.co/spaces/xdecoder/SEEM Come and try it out.
The above is the detailed content of Chinese team subverts CV! SEEM perfectly divides all explosions and divides the 'instantaneous universe' with one click. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1206
24
52
1206
24

 Where are video files stored in browser cache?
Feb 19, 2024 pm 05:09 PM
Where are video files stored in browser cache?
Feb 19, 2024 pm 05:09 PM
Which folder does the browser cache the video in? When we use the Internet browser every day, we often watch various online videos, such as watching music videos on YouTube or watching movies on Netflix. These videos will be cached by the browser during the loading process so that they can be loaded quickly when played again in the future. So the question is, in which folder are these cached videos actually stored? Different browsers store cached video folders in different locations. Below we will introduce several common browsers and their
 Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
With the rise of short video platforms, Douyin has become an indispensable part of everyone's daily life. On TikTok, we can see interesting videos from all over the world. Some people like to post other people’s videos, which raises a question: Is Douyin infringing upon posting other people’s videos? This article will discuss this issue and tell you how to edit videos without infringement and how to avoid infringement issues. 1. Is it infringing upon Douyin’s posting of other people’s videos? According to the provisions of my country's Copyright Law, unauthorized use of the copyright owner's works without the permission of the copyright owner is an infringement. Therefore, posting other people’s videos on Douyin without the permission of the original author or copyright owner is an infringement. 2. How to edit a video without infringement? 1. Use of public domain or licensed content: Public
 How to remove video watermark in Wink
Feb 23, 2024 pm 07:22 PM
How to remove video watermark in Wink
Feb 23, 2024 pm 07:22 PM
How to remove watermarks from videos in Wink? There is a tool to remove watermarks from videos in winkAPP, but most friends don’t know how to remove watermarks from videos in wink. Next is the picture of how to remove watermarks from videos in Wink brought by the editor. Text tutorial, interested users come and take a look! How to remove video watermarks in Wink 1. First open wink APP and select the [Remove Watermark] function in the homepage area; 2. Then select the video you want to remove the watermark in the album; 3. Then select the video and click the upper right corner after editing the video. [√]; 4. Finally, click [One-click Print] as shown in the figure below and then click [Process].
 How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, the national short video platform, not only allows us to enjoy a variety of interesting and novel short videos in our free time, but also gives us a stage to show ourselves and realize our values. So, how to make money by posting videos on Douyin? This article will answer this question in detail and help you make more money on TikTok. 1. How to make money from posting videos on Douyin? After posting a video and gaining a certain amount of views on Douyin, you will have the opportunity to participate in the advertising sharing plan. This income method is one of the most familiar to Douyin users and is also the main source of income for many creators. Douyin decides whether to provide advertising sharing opportunities based on various factors such as account weight, video content, and audience feedback. The TikTok platform allows viewers to support their favorite creators by sending gifts,
 2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
2 Ways to Remove Slow Motion from Videos on iPhone
Mar 04, 2024 am 10:46 AM
On iOS devices, the Camera app allows you to shoot slow-motion video, or even 240 frames per second if you have the latest iPhone. This capability allows you to capture high-speed action in rich detail. But sometimes, you may want to play slow-motion videos at normal speed so you can better appreciate the details and action in the video. In this article, we will explain all the methods to remove slow motion from existing videos on iPhone. How to Remove Slow Motion from Videos on iPhone [2 Methods] You can use Photos App or iMovie App to remove slow motion from videos on your device. Method 1: Open on iPhone using Photos app
 How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
With the rise of short video platforms, Xiaohongshu has become a platform for many people to share their lives, express themselves, and gain traffic. On this platform, publishing video works is a very popular way of interaction. So, how to publish Xiaohongshu video works? 1. How to publish Xiaohongshu video works? First, make sure you have a video content ready to share. You can use your mobile phone or other camera equipment to shoot, but you need to pay attention to the image quality and sound clarity. 2. Edit the video: In order to make the work more attractive, you can edit the video. You can use professional video editing software, such as Douyin, Kuaishou, etc., to add filters, music, subtitles and other elements. 3. Choose a cover: The cover is the key to attracting users to click. Choose a clear and interesting picture as the cover to attract users to click on it.
 How to convert videos downloaded by uc browser into local videos
Feb 29, 2024 pm 10:19 PM
How to convert videos downloaded by uc browser into local videos
Feb 29, 2024 pm 10:19 PM
How to turn videos downloaded by UC browser into local videos? Many mobile phone users like to use UC Browser. They can not only browse the web, but also watch various videos and TV programs online, and download their favorite videos to their mobile phones. Actually, we can convert downloaded videos to local videos, but many people don't know how to do it. Therefore, the editor specially brings you a method to convert the videos cached by UC browser into local videos. I hope it can help you. Method to convert uc browser cached videos to local videos 1. Open uc browser and click the "Menu" option. 2. Click "Download/Video". 3. Click "Cached Video". 4. Long press any video, when the options pop up, click "Open Directory". 5. Check the ones you want to download
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
