
 Technology peripherals
AI
OpenAI text generation 3D model has been upgraded to complete the modeling in seconds, which is more usable than Point·E
Technology peripherals
AI
OpenAI text generation 3D model has been upgraded to complete the modeling in seconds, which is more usable than Point·E
OpenAI text generation 3D model has been upgraded to complete the modeling in seconds, which is more usable than Point·E

Generative AI large models are the focus of OpenAI’s efforts. It has already launched text-generated image models DALL-E and DALL-E 2, as well as POINT-E, which generates 3D models based on text earlier this year.
Recently, the OpenAI research team has upgraded the 3D generative model and newly launched Shap・E, which is a conditional generative model for synthesizing 3D assets. Currently, the relevant model weights, inference code and samples have been open sourced.

- ##Paper address :https://arxiv.org/abs/2305.02463
- Project address: https://github.com/openai/shap-e
Let’s take a look at the generation effect first. Similar to generating images based on text, the 3D object model generated by Shap・E focuses on "unconstrained". For example, a plane that looks like a banana:

A chair that looks like a tree:

There are also classic examples, like the avocado chair:

Of course, some common objects can also be generated 3D model, for example a bowl of vegetables:

Donuts:

The Shap・E proposed in this article is a latent diffusion model on the 3D implicit function space, which can be rendered into NeRF and texture meshes. Given the same data set, model architecture and training calculations, Shap・E is better than similar explicit generation models. The researchers found that the pure text conditional model can generate diverse and interesting objects, which also demonstrates the potential of generating implicit representations.

Unlike working on a 3D generative model to produce a single output representation, Shap-E can Directly generate the parameters of the implicit function. Training Shap-E is divided into two stages: first training the encoder, which deterministically maps 3D assets into the parameters of the implicit function, and second training a conditional diffusion model on the output of the encoder. When trained on a large dataset of paired 3D and text data, the model is able to generate complex and diverse 3D assets in seconds. Compared with the point cloud explicit generation model Point・E, Shap-E models a high-dimensional, multi-representation output space, converges faster, and achieves equivalent or better sample quality.
Research backgroundThis article focuses on two implicit neural representations (INR) for 3D representation:
- NeRF An INR that represents a 3D scene as a function that maps coordinates and viewing directions to density and RGB color;
- DMTet and its extension GET3D Represents a textured 3D mesh that maps coordinates to colors, signed distances, and vertex offsets as a function. This INR enables 3D triangular meshes to be constructed in a differentiable manner and then rendered into a differentiable rasterization library.
While INR is flexible and expressive, obtaining an INR for every sample in the dataset is expensive. Additionally, each INR may have many numerical parameters, which may cause difficulties when training downstream generative models. By solving these problems using autoencoders with implicit decoders, smaller latent representations can be obtained that are directly modeled with existing generative techniques. An alternative approach is to use meta-learning to create a dataset of INRs that share most of their parameters, and then train a diffusion model or normalized flow on the free parameters of these INRs. It has also been suggested that gradient-based meta-learning may not be necessary and instead the Transformer encoder should be trained directly to produce NeRF parameters conditioned on multiple views of a 3D object.
The researchers combined and expanded the above methods and finally obtained Shap·E, which became a conditional generation model for various complex 3D implicit representations. First generate INR parameters for the 3D asset by training a Transformer-based encoder, and then train a diffusion model on the output of the encoder. Unlike previous approaches, INRs are generated that represent both NeRF and meshes, allowing them to be rendered in a variety of ways or imported into downstream 3D applications.
When trained on a dataset of millions of 3D assets, our model is able to produce a variety of identifiable samples under text prompts. Shap-E converges faster than Point·E, a recently proposed explicit 3D generative model. It can achieve comparable or better results with the same model architecture, data set, and conditioning mechanism.
Method Overview
The researcher first trains the encoder to generate implicit representation, and then trains the diffusion model on the latent representation generated by the encoder, which is mainly divided into the following two steps Done:
#1. Train an encoder to produce the parameters of an implicit function given a dense explicit representation of a known 3D asset. The encoder produces a latent representation of the 3D asset followed by linear projection to obtain the weights of the multilayer perceptron (MLP);
2. Apply the encoder to the dataset, and then Training diffusion priors on the set. The model is conditioned on images or textual descriptions.
We trained all models on a large dataset of 3D assets using corresponding renderings, point clouds, and text captions.
3D Encoder
The encoder architecture is shown in Figure 2 below.
Potential diffusion
The generation model adopts the Point・E diffusion architecture based on the transformer, but uses a latent vector sequence instead Point cloud. The sequence of latent function shapes is 1024×1024 and is input to the transformer as a sequence of 1024 tokens, where each token corresponds to a different row of the MLP weight matrix. Therefore, this model is roughly computationally equivalent to the base Point·E model (i.e., has the same context length and width). On this basis, input and output channels are added to generate samples in a higher-dimensional space.
Experimental results
Encoder evaluation
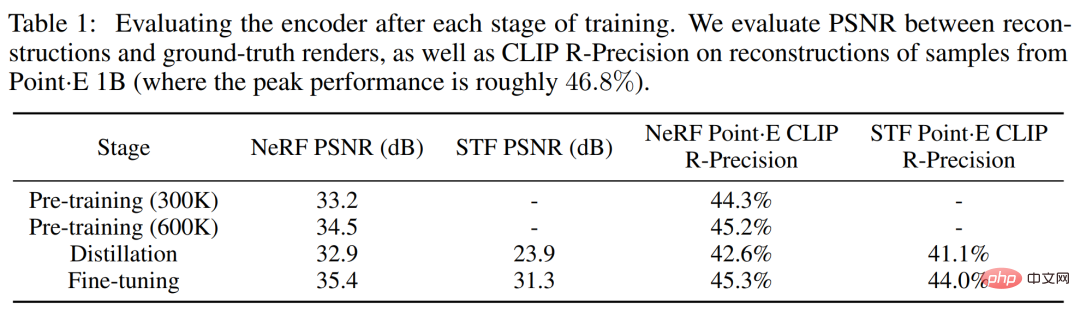
The researcher conducted the entire encoder training process Tracks two rendering-based metrics. First evaluate the peak signal-to-noise ratio (PSNR) between the reconstructed image and the real rendered image. Additionally, to measure the encoder's ability to capture semantically relevant details of a 3D asset, the CLIP R-Precision for reconstructed NeRF and STF renderings was re-evaluated by encoding the mesh produced by the largest Point·E model.
Table 1 below tracks the results of these two metrics at different training stages. It can be found that distillation harms the NeRF reconstruction quality, while fine-tuning not only restores but also slightly improves the NeRF quality while greatly improving the STF rendering quality.
##Compare Point・E
Researcher The proposed latent diffusion model has the same architecture, training data set, and conditional pattern as Point·E. Comparison with Point·E is more useful in distinguishing the effects of generating implicit neural representations rather than explicit representations. Figure 4 below compares these methods on sample-based evaluation metrics.
Qualitative samples are shown in Figure 5 below, and you can see that these models often generate samples of varying quality for the same text prompt. Before the end of training, the text condition Shap·E starts to get worse in evaluation. 
The researchers found that Shap·E and Point·E tend to share similar failure cases, as shown in Figure 6 (a) below. This suggests that training data, model architecture, and conditioned images have a greater impact on generated samples than the chosen representation space.
We can observe that there are still some qualitative differences between the two image condition models, for example in the first row of Figure 6(b) below, Point・E ignores the bench small gaps, and Shap・E attempts to model them. This article hypothesizes that this particular discrepancy occurs because point clouds do not represent thin features or gaps well. Also observed in Table 1 is that the 3D encoder slightly reduces CLIP R-Precision when applied to Point·E samples.

##Compare with other methods
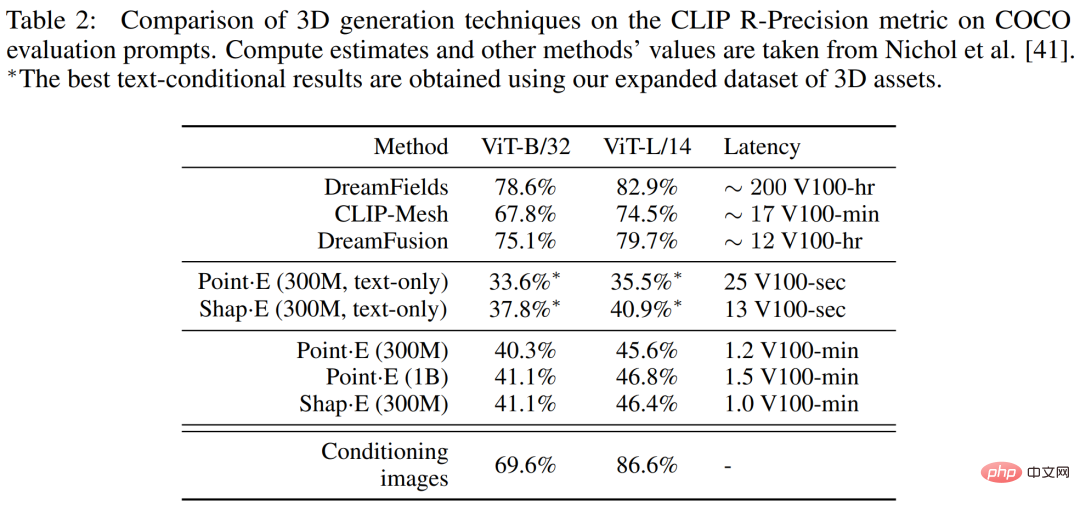
In Table 2 below, researchers compare shape・E to a wider range of 3D generation techniques on the CLIP R-Precision metric.
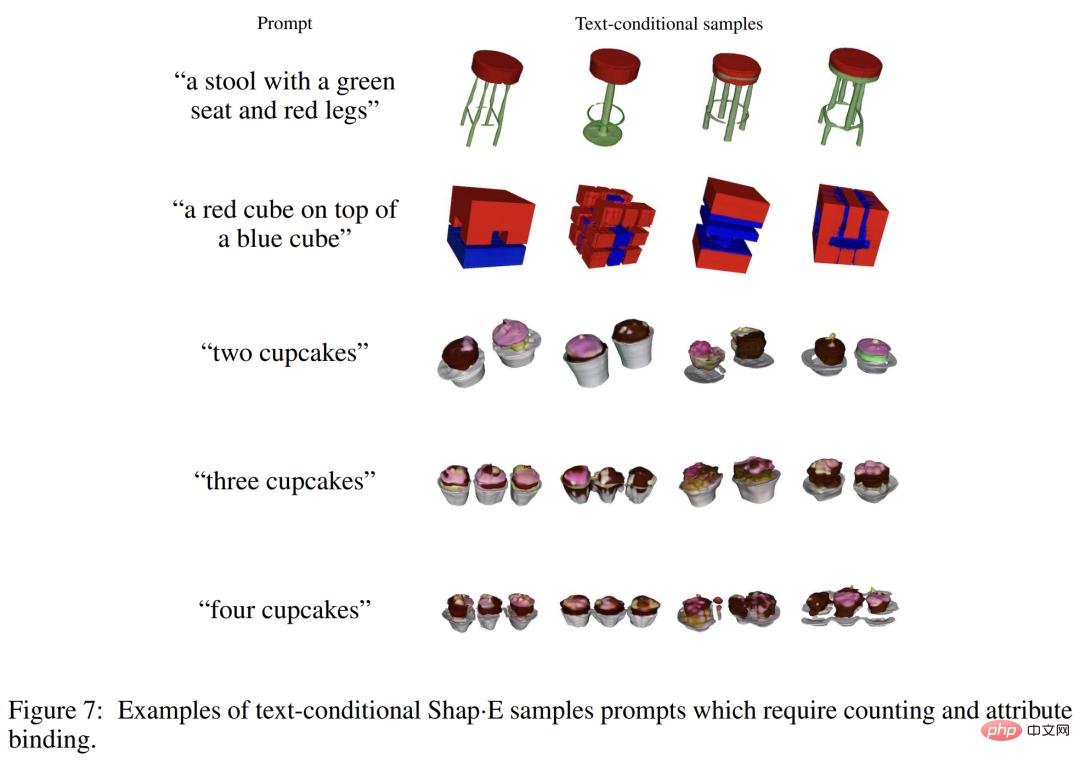
Although Shap-E can understand many problems with A single object prompt for simple properties, but it is limited in its ability to combine concepts. As you can see in Figure 7 below, this model makes it difficult to bind multiple properties to different objects and does not efficiently generate the correct number of objects when more than two objects are requested. This may be a result of insufficient paired training data and may be addressed by collecting or generating a larger annotated 3D dataset.

The above is the detailed content of OpenAI text generation 3D model has been upgraded to complete the modeling in seconds, which is more usable than Point·E. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Centos8 restarts ssh
Apr 14, 2025 pm 09:00 PM
Centos8 restarts ssh
Apr 14, 2025 pm 09:00 PM
The command to restart the SSH service is: systemctl restart sshd. Detailed steps: 1. Access the terminal and connect to the server; 2. Enter the command: systemctl restart sshd; 3. Verify the service status: systemctl status sshd.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
