

How to use re.findAll(), re.sub(), and set() in Python

1. re.findall()
re.findall(): The function returns a list containing all matching items. Returns all strings matching pattern in string, in the form of list/array.
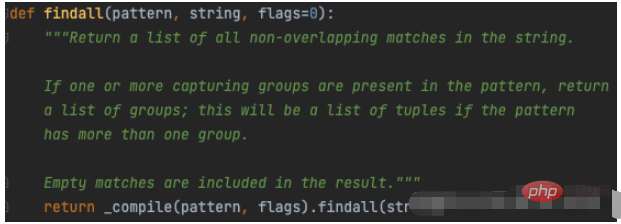
It can be seen from the function prototype code that the findall() function has three parameters:
1. pattern: the ‘ pattern string in the regular expression ’ ;
2. string: the original string that currently needs to be processed (search and replace);
3. flags: optional parameter, indicating the matching mode used during compilation (such as ignoring size writing, multi-line mode, etc.), in numeric form, the default is 0
# 示例代码 import re text1 = '北京市海淀区不存在的38街区不想工作大厦99号' res = re.findall(r'\d+', text1) print(type(res)) print(res) # output # <class 'list'> # ['38', '99']
2. re.sub()
re.sub(): The function replaces all matching items with the selected text and returns the result.
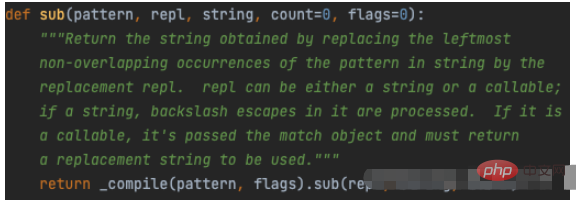
It can be seen from the function prototype code that the re.sub() function has five parameters:
1. pattern: ‘ pattern in regular expressions String’ ;
2. repl: the string that needs to be replaced, that is, replacing the matched pattern with repl; it can be a function;
3. string: currently needs to be processed ( Find and replace) the original string; ;
5. flags: Optional parameter, indicating the matching mode used during compilation (such as ignoring case, multi-line mode, etc.), in numeric form, the default is 0
# 将所有匹配到的‘数字串' 替换为 '520‘ text1 = '北京市海淀区不存在的38街区不想工作大厦99号' res = re.re(r'\d+', 520) print(type(res)) print(res) # output,返回值res结果是str # <class 'str'> # 北京市海淀区不存在的520街区不想工作大厦520号
3. set ()
set(): One of python’s built-in functions, creates an unordered set of non-repeating elements. Supports calculation of intersection, difference, and union.
# 为list数组l1 去重
l1 = [1, 1, 2, 2, 2, 3, 4]
s1 = set(l1)
print(type(s1))
print(s1)
# output,返回类型是 set
# <class 'set'>
# {1, 2, 3, 4}# 计算l1 和 l2 的交集
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1)
s2 = set(l2)
u = s1 & s2
print(type(u))
print(u)
# output,返回结果类型set
# <class 'set'>
# {2, 3, 4}# 计算l1 和 l2 的并集, 并集符号 ‘|',intersection
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1) # {1, 2, 3, 4}
s2 = set(l2) # {2, 3, 4, 5, 6}
u = s1 | s2
print(type(u))
print(u)
# output,返回结果类型set, 计算 {1, 2, 3, 4} 和 {2, 3, 4, 5, 6} 的并集
# <class 'set'>
# {1, 2, 3, 4, 5, 6}# 计算差集,diff
l1 = [1, 1, 2, 2, 2, 3, 4]
l2 = [2, 3, 3, 4, 5, 6, 6]
s1 = set(l1) # {1, 2, 3, 4}
s2 = set(l2) # {2, 3, 4, 5, 6}
print(s2)
u = s1 - s2
print(type(u))
print(u)
# output,返回结果是set
# <class 'set'>
# {1}# set内也可以传入字符串,会自动转换成list类型
text1 = '北京市海淀区海淀区不想上班不想上班'
res = set(text1)
print(res) # 内部元素是一个个的字,去重 且 无序
# output
# <class 'set'>
# {'上', '北', '班', '海', '淀', '京', '不', '想', '区', '市'}The above is the detailed content of How to use re.findAll(), re.sub(), and set() in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 What is the function of C language sum?
Apr 03, 2025 pm 02:21 PM
What is the function of C language sum?
Apr 03, 2025 pm 02:21 PM
There is no built-in sum function in C language, so it needs to be written by yourself. Sum can be achieved by traversing the array and accumulating elements: Loop version: Sum is calculated using for loop and array length. Pointer version: Use pointers to point to array elements, and efficient summing is achieved through self-increment pointers. Dynamically allocate array version: Dynamically allocate arrays and manage memory yourself, ensuring that allocated memory is freed to prevent memory leaks.
 Who gets paid more Python or JavaScript?
Apr 04, 2025 am 12:09 AM
Who gets paid more Python or JavaScript?
Apr 04, 2025 am 12:09 AM
There is no absolute salary for Python and JavaScript developers, depending on skills and industry needs. 1. Python may be paid more in data science and machine learning. 2. JavaScript has great demand in front-end and full-stack development, and its salary is also considerable. 3. Influencing factors include experience, geographical location, company size and specific skills.
 Is distinctIdistinguish related?
Apr 03, 2025 pm 10:30 PM
Is distinctIdistinguish related?
Apr 03, 2025 pm 10:30 PM
Although distinct and distinct are related to distinction, they are used differently: distinct (adjective) describes the uniqueness of things themselves and is used to emphasize differences between things; distinct (verb) represents the distinction behavior or ability, and is used to describe the discrimination process. In programming, distinct is often used to represent the uniqueness of elements in a collection, such as deduplication operations; distinct is reflected in the design of algorithms or functions, such as distinguishing odd and even numbers. When optimizing, the distinct operation should select the appropriate algorithm and data structure, while the distinct operation should optimize the distinction between logical efficiency and pay attention to writing clear and readable code.
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
The H5 page needs to be maintained continuously, because of factors such as code vulnerabilities, browser compatibility, performance optimization, security updates and user experience improvements. Effective maintenance methods include establishing a complete testing system, using version control tools, regularly monitoring page performance, collecting user feedback and formulating maintenance plans.
 How to understand !x in C?
Apr 03, 2025 pm 02:33 PM
How to understand !x in C?
Apr 03, 2025 pm 02:33 PM
!x Understanding !x is a logical non-operator in C language. It booleans the value of x, that is, true changes to false, false changes to true. But be aware that truth and falsehood in C are represented by numerical values rather than boolean types, non-zero is regarded as true, and only 0 is regarded as false. Therefore, !x deals with negative numbers the same as positive numbers and is considered true.
 What does sum mean in C language?
Apr 03, 2025 pm 02:36 PM
What does sum mean in C language?
Apr 03, 2025 pm 02:36 PM
There is no built-in sum function in C for sum, but it can be implemented by: using a loop to accumulate elements one by one; using a pointer to access and accumulate elements one by one; for large data volumes, consider parallel calculations.
 How to obtain real-time application and viewer data on the 58.com work page?
Apr 05, 2025 am 08:06 AM
How to obtain real-time application and viewer data on the 58.com work page?
Apr 05, 2025 am 08:06 AM
How to obtain dynamic data of 58.com work page while crawling? When crawling a work page of 58.com using crawler tools, you may encounter this...
 What is the reason why PS keeps showing loading?
Apr 06, 2025 pm 06:39 PM
What is the reason why PS keeps showing loading?
Apr 06, 2025 pm 06:39 PM
PS "Loading" problems are caused by resource access or processing problems: hard disk reading speed is slow or bad: Use CrystalDiskInfo to check the hard disk health and replace the problematic hard disk. Insufficient memory: Upgrade memory to meet PS's needs for high-resolution images and complex layer processing. Graphics card drivers are outdated or corrupted: Update the drivers to optimize communication between the PS and the graphics card. File paths are too long or file names have special characters: use short paths and avoid special characters. PS's own problem: Reinstall or repair the PS installer.
