
 Operation and Maintenance
Safety
Process analysis from entering the URL to the final browser rendering of the page content
Operation and Maintenance
Safety
Process analysis from entering the URL to the final browser rendering of the page content
Process analysis from entering the URL to the final browser rendering of the page content

Preparation
When you enter the URL (such as www.coder.com) in the browser and hit Enter, the first thing the browser does is to obtain the coder. com's IP address, the specific method is to send a UDP packet to the DNS server, and the DNS server will return the IP of coder.com. At this time, the browser usually caches the IP address, so that the next access will be faster.
For example, in Chrome, you can view it through chrome://net-internals/#dns.
With the IP of the server, the browser can initiate HTTP requests, but HTTP Request/Response must be sent and received on the "virtual connection" of TCP.
To establish a "virtual" TCP connection, TCP Postman needs to know 4 things: (local IP, local port, server IP, server port). Now it only knows the local IP and server IP. , what to do with the two ports?
The local port is very simple. The operating system can randomly assign one to the browser. The server port is even simpler. It uses a "well-known" port. The HTTP service is 80. We just tell TCP Postman directly.
After the three-way handshake, the TCP connection between the client and the server is established! Finally we can send HTTP requests.

The reason why the TCP connection is drawn as a dotted line is because this connection is virtual
Web server
An HTTP GET request goes through thousands of miles and is forwarded by multiple routers before finally reaching the server (HTTP packets may be fragmented and transmitted by the lower layer, which is omitted).
The Web server needs to start processing. It has three ways to handle it:
(1) You can use one thread to process all requests, and only one can be processed at the same time. The structure is easy to implement, but it can cause serious performance problems.
(2) A process/thread can be allocated for each request, but when there are too many connections, the server-side process/thread will consume a lot of memory resources, and the switching of processes/threads will also cause The CPU is overwhelmed.
(3) To reuse I/O, many web servers adopt a reuse structure. For example, all connections are monitored through epoll. When the status of the connection changes (if data is readable) , only use one process/thread to process that connection. After processing, continue to monitor and wait for the next status change. In this way thousands of connection requests can be handled with a small number of processes/threads.
We use Nginx, a very popular web server, to continue the following story.
For the HTTP GET request, Nginx uses epoll to read it. Next, Nginx needs to determine whether this is a static request or a dynamic request?
If it is a static request (HTML file, JavaScript file, CSS file, picture, etc.), you may be able to handle it yourself (of course it depends on the Nginx configuration and may be forwarded to other cache servers), read Relevant files on the local hard disk are returned directly.
If it is a dynamic request that needs to be processed by the backend server (such as Tomcat) before it can be returned, then it needs to be forwarded to Tomcat. If there is more than one Tomcat on the backend, then one needs to be selected according to a certain strategy.
For example, Ngnix supports the following types:
Polling: forward to the backend servers one by one in order
Weight: assign a weight to each backend server , which is equivalent to the probability of forwarding to the backend server.
ip_hash: Do a hash operation based on the IP, and then find a server to forward it. In this way, the same client IP will always be forwarded to the same back-end server.
fair: Allocate requests based on the response time of the backend server, and prioritize the response time period.
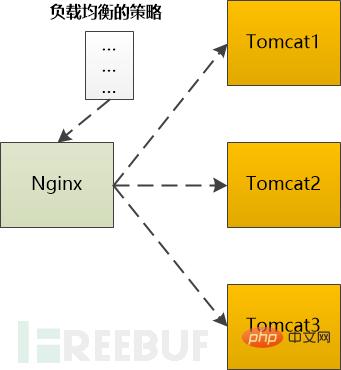
No matter which algorithm is used, a certain backend server is finally selected, and then Nginx needs to forward the HTTP Request to the backend Tomcat and output the HttpResponse is then forwarded to the browser.
It can be seen that Nginx plays the role of an agent in this scenario.

Application Server
Http Request finally came to Tomcat, which is written in Java and can handle Servlet/JSP Container, our code runs in this container.
Like the Web server, Tomcat may also allocate a thread for each request to process, which is commonly known as the BIO mode (Blocking I/O mode).
It is also possible to use I/O multiplexing technology and only use a few threads to handle all requests, that is, NIO mode.
No matter which method is used, the Http Request will be handed over to a Servlet for processing. This Servlet will convert the Http Request into the parameter format used by the framework, and then distribute it to a Controller (if Are you using Spring) or Action (if you are on Struts).
The rest of the story is relatively simple (no, for coders, it is actually the most complicated part), which is to execute the add, delete, modify and check logic that coders often write. In this process, it is very likely to interact with cache, The database and other back-end components deal with each other and ultimately return HTTP Response. Since the details depend on the business logic, they are omitted.
According to our example, this HTTP Response should be an HTML page.
Homecoming
Tomcat happily sent the Http Response to Ngnix.
Ngnix is also happy to send the Http Response to the browser.

Can the TCP connection be closed after sending?
If you are using HTTP1.1, this connection is keep-alive by default, which means it cannot be closed;
If you are using HTTP1.0, you need to check the previous HTTP Request Header. There is no Connection:keep-alive. If there is, it cannot be turned off.
The browser works again
The browser received the Http Response, read the HTML page from it, and began to prepare to display the page.
But this HTML page may reference a large number of other resources, such as js files, CSS files, pictures, etc. These resources are also located on the server side and may be located under another domain name, such as static.coder.com.
The browser has no choice but to download them one by one. Starting from using DNS to obtain the IP, the things that have been done before have to be done again. The difference is that there will no longer be the intervention of application servers such as Tomcat.
If there are too many external resources that need to be downloaded, the browser will create multiple TCP connections and download them in parallel.
But the number of requests to the same domain name at the same time cannot be too many, otherwise the server will have too much traffic and will not be able to bear it. Therefore, browsers need to limit themselves. For example, Chrome can only download 6 resources in parallel under Http1.1.
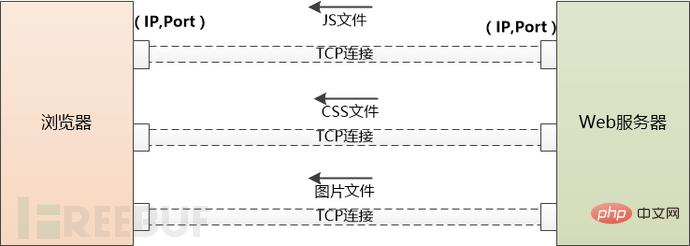
When the server sends JS and CSS files to the browser, it will tell the browser when these files will expire (using Cache-Control or Expire), and the browser can The file is cached locally. When the same file is requested for the second time, if it does not expire, it can be retrieved directly from the local area.
If it expires, the browser can ask the server whether the file has been modified? (Based on the Last-Modified and ETag sent by the last server), if it has not been modified (304 Not Modified), you can also use caching. Otherwise the server will send the latest file back to the browser.
Of course, if you press Ctrl F5, a GET request will be forcibly issued, completely ignoring the cache.
Note: Under Chrome, you can view the cache through the chrome://view-http-cache/ command.
Now the browser gets three important things:
1.HTML, the browser turns it into a DOM Tree
2. CSS, the browser Turn it into a CSS Rule Tree
3. JavaScript, it can modify the DOM Tree
The browser will generate the so-called "Render Tree" through the DOM Tree and CSS Rule Tree, calculating each The position/size of each element, layout, and then calling the API of the operating system for drawing. This is a very complicated process and will not be shown here.
So far, we finally see the content of www.coder.com in the browser.
The above is the detailed content of Process analysis from entering the URL to the final browser rendering of the page content. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1375
1375
 52
52

 How to achieve gap effect on the card and coupon layout with gradient background?
Apr 05, 2025 am 07:48 AM
How to achieve gap effect on the card and coupon layout with gradient background?
Apr 05, 2025 am 07:48 AM
Realize the gap effect of card coupon layout. When designing card coupon layout, you often encounter the need to add gaps on card coupons, especially when the background is gradient...
 How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
How to correctly display the locally installed 'Jingnan Mai Round Body' on the web page?
Apr 05, 2025 pm 10:33 PM
Using locally installed font files in web pages Recently, I downloaded a free font from the internet and successfully installed it into my system. Now...
 How to customize the resize symbol through CSS and make it uniform with the background color?
Apr 05, 2025 pm 02:30 PM
How to customize the resize symbol through CSS and make it uniform with the background color?
Apr 05, 2025 pm 02:30 PM
The method of customizing resize symbols in CSS is unified with background colors. In daily development, we often encounter situations where we need to customize user interface details, such as adjusting...
 Why does negative margins not take effect in some cases? How to solve this problem?
Apr 05, 2025 pm 10:18 PM
Why does negative margins not take effect in some cases? How to solve this problem?
Apr 05, 2025 pm 10:18 PM
Why do negative margins not take effect in some cases? During programming, negative margins in CSS (negative...
 The text under Flex layout is omitted but the container is opened? How to solve it?
Apr 05, 2025 pm 11:00 PM
The text under Flex layout is omitted but the container is opened? How to solve it?
Apr 05, 2025 pm 11:00 PM
The problem of container opening due to excessive omission of text under Flex layout and solutions are used...
 How to obtain real-time application and viewer data on the 58.com work page?
Apr 05, 2025 am 08:06 AM
How to obtain real-time application and viewer data on the 58.com work page?
Apr 05, 2025 am 08:06 AM
How to obtain dynamic data of 58.com work page while crawling? When crawling a work page of 58.com using crawler tools, you may encounter this...
 Why does a specific div element in the Edge browser not display? How to solve this problem?
Apr 05, 2025 pm 08:21 PM
Why does a specific div element in the Edge browser not display? How to solve this problem?
Apr 05, 2025 pm 08:21 PM
How to solve the display problem caused by user agent style sheets? When using the Edge browser, a div element in the project cannot be displayed. After checking, I posted...
 How to use CSS and Flexbox to implement responsive layout of images and text at different screen sizes?
Apr 05, 2025 pm 06:06 PM
How to use CSS and Flexbox to implement responsive layout of images and text at different screen sizes?
Apr 05, 2025 pm 06:06 PM
Implementing responsive layouts using CSS When we want to implement layout changes under different screen sizes in web design, CSS...
