
 Technology peripherals
AI
Google internal documents leaked: Open source large models are too scary, even OpenAI can't stand it!
Technology peripherals
AI
Google internal documents leaked: Open source large models are too scary, even OpenAI can't stand it!
Google internal documents leaked: Open source large models are too scary, even OpenAI can't stand it!

I saw an article today, saying that Google leaked a document "We have no moat, and neither does OpenAI." It describes the views of a certain Google employee (non-Google company) on open source AI. The view is very interesting, roughly What it means is this:
After ChatGPT became popular, all major manufacturers are flocking to LLM and investing crazily.
Google is also working hard, hoping to make a comeback, but no one can win this arms race because third parties are quietly eating this big cake.
This third party is a large open source model.
Open source large models have already done this:
1. Run the basic model on Pixel 6 at a speed of 5 tokens per second.
2. You can fine-tune personalized AI on your PC in one night:
Although OpenAI and Google’s models have advantages in quality, The gap is closing at an alarming rate:
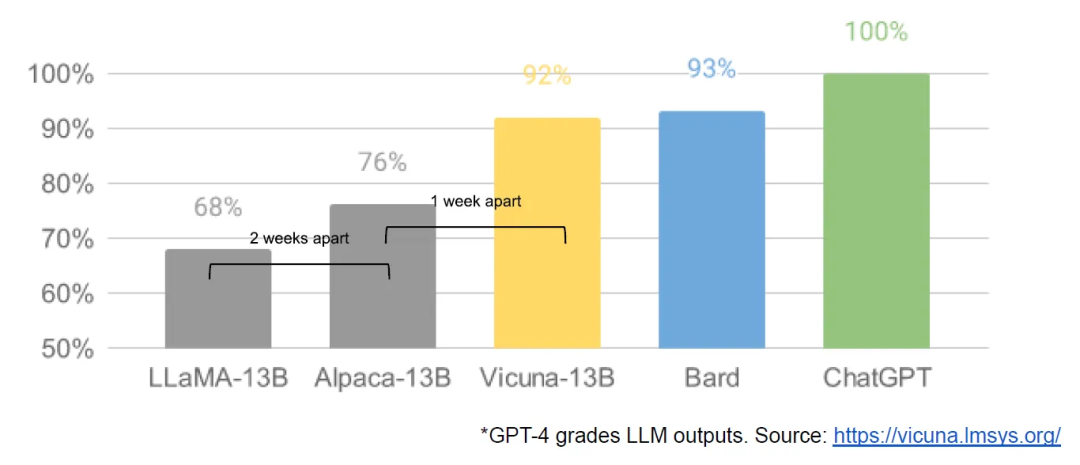
Open source models are faster, customizable, more private, and more powerful.
Open source large models use $100 and 13B parameters to do things and get it done within a few weeks; while Google struggles with $10 million and 540B parameters within a few months.
When free, unrestricted alternatives are as good as the closed model, people will definitely abandon the closed model.
It all started when Facebook open sourced LLaMA. In early March, the open source community got this truly capable basic model. Although there was no instruction, conversation tuning, or RLHF, the community immediately realized the importance of this thing. .
The subsequent innovation is simply crazy, even measured in days:
2-24: Facebook launches LLaMA, which at this time is only licensed to research institutions and used by government organizations
3-03: LLaMA was leaked on the Internet. Although it was not allowed for commercial use, suddenly anyone could play it.
3-12: Running LLaMA on Raspberry Pi is very slow and impractical
3-13: Stanford released Alpaca and added instruction tuning for LLaMA, which is even more "scary" Yes, Eric J. Wang of Stanford used an RTX 4090 graphics card to train a model equivalent to Alpaca in just 5 hours, reducing the computing power requirements of such models to consumer levels.
3-18: 5 days later, Georgi Gerganov uses 4-bit quantization technology to run LLaMA on MacBook CPU, which is the first "GPUless" solution.
3-19: Just one day later, researchers from the University of California, Berkeley, CMU, Stanford University, and the University of California, San Diego jointly launched Vicuna, which claims to have achieved more than 90% of the quality of OpenAI ChatGPT and Google Bard. It also outperforms other models such as LLaMA and Stanford Alpaca in more than 90% of cases.
3-25: Nomic created GPT4all, which is both a model and an ecosystem. For the first time we see multiple models gathered in one place
…
In just one month, instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. all appeared.
More importantly, the open source community has solved the scalability problem, and the threshold for training has been lowered from a large company to one person, one night and a powerful personal computer.
So the author said at the end: OpenAI also made mistakes like us, and it cannot withstand the impact of open source. We need to build an ecosystem to make open source work for Google.
Google has applied this paradigm on Android and Chrome with great success. You should establish yourself as a leader in large model open source and continue to solidify your position as a thought leader and leader.
To be honest, the development of large language models in the past month or so has been really dazzling and overwhelming, and I am bombarded every day.
This reminds me of the early years when the Internet was just starting out. One exciting website pops up today, and another pops up tomorrow. And when the mobile Internet broke out, one app became popular today, and another app became popular tomorrow...
Personally, I don’t want these big language models to be controlled by giants. We can only “parasitize” these giant models, call their APIs, and develop some applications. This is very unpleasant. of. It is best to let a hundred flowers bloom and be accessible to the masses, so that everyone can build their own private model.
Now the cost of training should be affordable for small companies. If programmers have the ability to train, it may be a good opportunity combined with specific industries and fields.
If programmers want to be proficient in large-scale privatization models, in addition to the principles, they still have to practice by themselves. There are also dozens of people on our planet practicing in teams. Although the open source community has greatly reduced the cost, it still requires I want to train a useful model, but the requirements for the hardware environment are still too high. Graphics cards are very expensive. RTX4090 costs tens of thousands, which is painful. The price of renting a GPU for training in the cloud is even more uncontrollable. If the training fails, money will be lost. Throw it away in vain. It's not like learning a language or framework and downloading a few installation packages. It's almost zero cost.
I hope the threshold will be lowered further!
The above is the detailed content of Google internal documents leaked: Open source large models are too scary, even OpenAI can't stand it!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Google Pixel 9 Pro XL gets tested with desktop mode
Aug 29, 2024 pm 01:09 PM
Google Pixel 9 Pro XL gets tested with desktop mode
Aug 29, 2024 pm 01:09 PM
Google has introduced DisplayPort Alternate Mode with the Pixel 8 series, and it's present on the newly launched Pixel 9 lineup. While it's mainly there to let you mirror the smartphone display with a connected screen, you can also use it for desktop
 Google Tensor G4 of Pixel 9 Pro XL lags behind Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google Tensor G4 of Pixel 9 Pro XL lags behind Tensor G2 in Genshin Impact
Aug 24, 2024 am 06:43 AM
Google recently responded to the performance concerns about the Tensor G4 of the Pixel 9 line. The company said that the SoC wasn't designed to beat benchmarks. Instead, the team focused on making it perform well in the areas where Google wants the c
 Google Pixel 9 smartphones will not launch with Android 15 despite seven-year update commitment
Aug 01, 2024 pm 02:56 PM
Google Pixel 9 smartphones will not launch with Android 15 despite seven-year update commitment
Aug 01, 2024 pm 02:56 PM
The Pixel 9 series is almost here, having been scheduled for an August 13 release. Based on recent rumours, the Pixel 9, Pixel 9 Pro and Pixel 9 Pro XL will mirror the Pixel 8 and Pixel 8 Pro (curr. $749 on Amazon) by starting with 128 GB of storage.
 New Google Pixel desktop mode showcased in fresh video as possible Motorola Ready For and Samsung DeX alternative
Aug 08, 2024 pm 03:05 PM
New Google Pixel desktop mode showcased in fresh video as possible Motorola Ready For and Samsung DeX alternative
Aug 08, 2024 pm 03:05 PM
A few months have passed since Android Authority demonstrated a new Android desktop mode that Google had hidden away within Android 14 QPR3 Beta 2.1. Arriving hot on the heels of Google adding DisplayPort Alt Mode support for the Pixel 8 and Pixel 8
 Google opens AI Test Kitchen & Imagen 3 to most users
Sep 12, 2024 pm 12:17 PM
Google opens AI Test Kitchen & Imagen 3 to most users
Sep 12, 2024 pm 12:17 PM
Google's AI Test Kitchen, which includes a suite of AI design tools for users to play with, has now opened up to users in well over 100 countries worldwide. This move marks the first time that many around the world will be able to use Imagen 3, Googl
 Google\'s new Chromecast \'TV Streamer\' rumoured to launch with Ethernet and Thread connectivity
Aug 01, 2024 am 10:21 AM
Google\'s new Chromecast \'TV Streamer\' rumoured to launch with Ethernet and Thread connectivity
Aug 01, 2024 am 10:21 AM
Google is roughly a fortnight away from fully revealing new hardware. As usual, countless sources have leaked details about new Pixel devices, whether that be the Pixel Watch 3, Pixel Buds Pro 2 or Pixel 9 smartphones. It also seems that the company
 Google Pixel 9 Pro XL ranks 2nd in DxOMark\'s \'Global\' smartphone camera ranking
Aug 23, 2024 am 06:42 AM
Google Pixel 9 Pro XL ranks 2nd in DxOMark\'s \'Global\' smartphone camera ranking
Aug 23, 2024 am 06:42 AM
Google's new Pixel 9 series has introduced a new variant that wasn't present in previous lineups, the Pixel 9 Pro XL. It is essentially identical to the non-XL variant (pre-order at Amazon), but as the name suggests, it has a larger screen. The two e
 Pixel 9 Pro XL vs iPhone 15 Pro Max camera comparison reveals surprising Google wins in video and zoom performance
Aug 24, 2024 pm 12:32 PM
Pixel 9 Pro XL vs iPhone 15 Pro Max camera comparison reveals surprising Google wins in video and zoom performance
Aug 24, 2024 pm 12:32 PM
The Google Pixel 9 Pro and Pro XL are Google's answers to the likes of the Samsung Galaxy S24 Ultra and the Apple iPhone 15 Pro and Pro Max. Daniel Sin on YouTube(watch below) has compared the Google Pixel 9 Pro XL to the iPhone 15 Pro Max with some
