
 Technology peripherals
AI
Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'
Technology peripherals
AI
Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'
Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'

With the development of large language model (LLM), diffusion (Diffusion) and other technologies, the birth of products such as ChatGPT and Midjourney has set off a new wave of AI craze, and generative AI has also become a topic of great concern. .
Unlike text and images, 3D generation is still in the technology exploration stage.
At the end of 2022, Google, NVIDIA and Microsoft have successively launched their own 3D generation work, but most of them are based on advanced Neural Radiation Field (NeRF) implicit expression and are incompatible with industrial 3D software Rendering pipelines such as Unity, Unreal Engine, and Maya are not compatible.
Even if it is converted into geometric and color maps expressed by Mesh through traditional solutions, it will cause insufficient accuracy and reduced visual quality, and cannot be directly applied to film and television production and game production.

Project website: https://sites.google.com/view/dreamface
Paper address: https://arxiv.org/abs/2304.03117
Web Demo: https ://hyperhuman.top
HuggingFace Space: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
In order to solve these problems, the R&D team from Yingmo Technology and Shanghai University of Science and Technology proposed a text-guided progressive 3D generation framework.
This framework introduces external data sets (including geometry and PBR materials) that comply with CG production standards, and can directly generate 3D assets that comply with this standard based on text. It is the first to support Production-Ready A framework for 3D asset generation.
To achieve text generation-driven 3D hyper-realistic digital humans, the team combined this framework with a production-grade 3D digital human dataset. This work has been accepted by Transactions on Graphics, the top international journal in the field of computer graphics, and will be presented at SIGGRAPH 2023, the top international computer graphics conference.
DreamFace mainly includes three modules, geometry generation, physics-based material diffusion and animation capability generation.
Compared with previous 3D generation work, the main contributions of this work include:
· Proposed DreamFace This novel generative approach combines recent visual-language models with animatable and physically materialable facial assets, using progressive learning to separate geometry, appearance, and animation capabilities.
· Introduces the design of dual-channel appearance generation, combining a novel material diffusion model with a pre-trained model, simultaneously in the latent space and image space Perform two-stage optimization.
· Facial assets using BlendShapes or generated Personalized BlendShapes have animation capabilities and further demonstrate the use of DreamFace for natural character design.
Geometry generation
The geometry generation module can generate a consistent geometric model based on text prompts. However, when it comes to face generation, this can be difficult to supervise and converge.
Therefore, DreamFace proposes a selection framework based on CLIP (Contrastive Language-Image Pre-Training), which first selects the best candidates from randomly sampled candidates in the face geometric parameter space. Get a good rough geometry model and then sculpt the geometric details to make the head model more consistent with the text prompt.
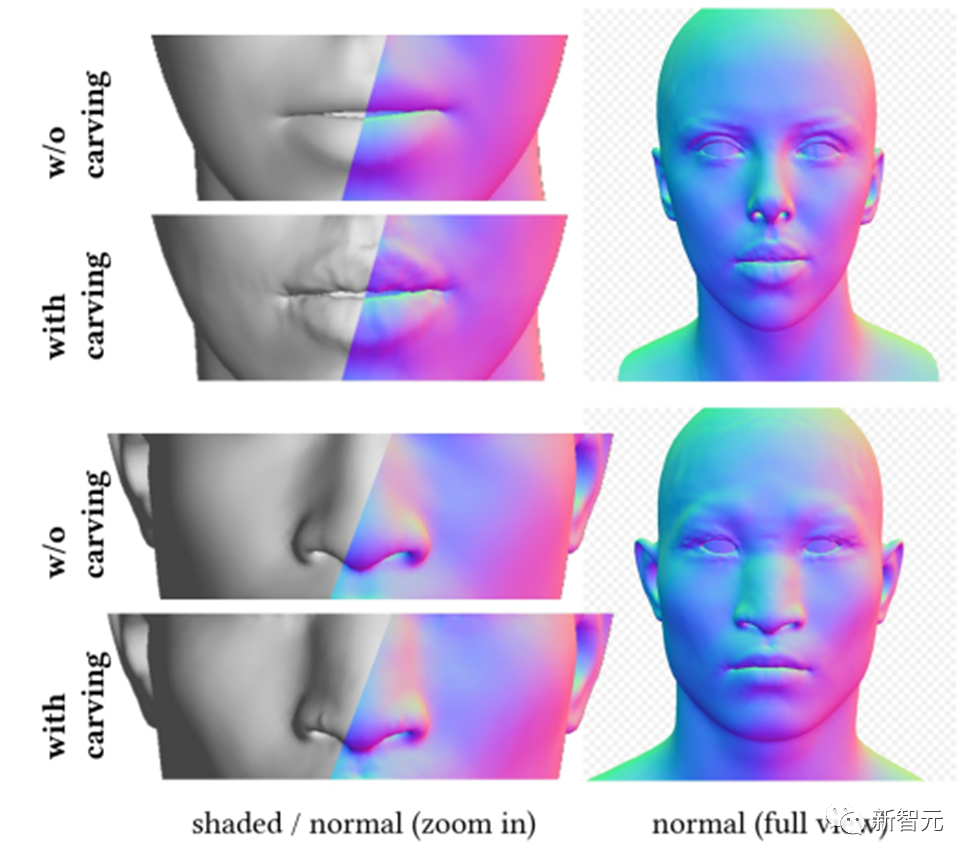
Based on the input prompts, DreamFace uses the CLIP model to select the rough geometry candidate with the highest matching score. Next, DreamFace uses an implicit diffusion model (LDM) to perform Scored Distillation Sampling (SDS) processing on the rendered image under random viewing angles and lighting conditions.
This allows DreamFace to add facial details to rough geometry models through vertex displacement and detailed normal maps, resulting in highly detailed geometry.
Similar to the head model, DreamFace also makes hairstyle and color selections based on this framework.
Physically Based Material Diffusion Generation
The physically based material diffusion module is designed to predict facial textures that are consistent with predicted geometry and text cues.
First, DreamFace fine-tuned the pre-trained LDM on the large-scale UV material data set collected to obtain two LDM diffusion models.

DreamFace uses a joint training scheme that coordinates two diffusion processes, one for directly denoising UV textures map, and the other is used to supervise the rendered image to ensure the correct formation of facial UV maps and rendered images consistent with text cues.
In order to reduce the generation time, DreamFace adopts a rough texture potential diffusion stage to provide a priori potential for detailed texture generation.
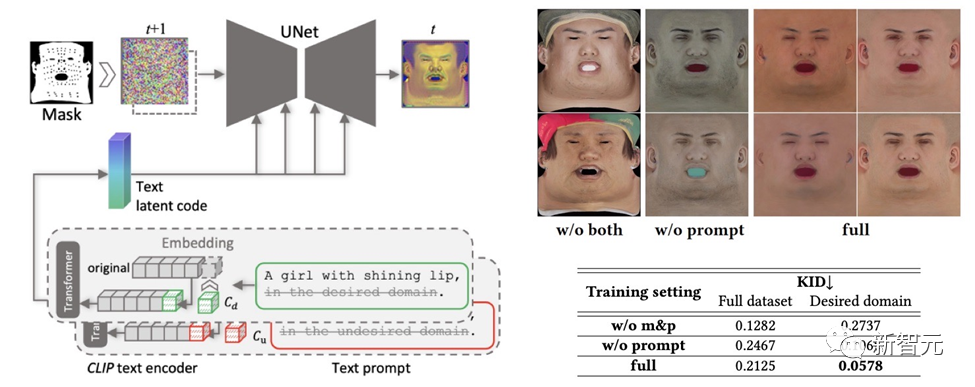
To ensure that the texture maps created do not contain undesirable features or lighting situations, while still maintaining diversity, the design A cued learning strategy.
The team uses two methods to generate high-quality diffuse reflection maps:
(1) Prompt Tuning. Unlike hand-crafted domain-specific text cues, DreamFace combines two domain-specific continuous text cues Cd and Cu with corresponding text cues, which will be optimized during U-Net denoiser training to avoid instability and Time-consuming manual writing of prompts.
(2) Masking of non-face areas. The LDM denoising process will be additionally constrained by non-face area masks to ensure that the resulting diffuse map does not contain any unwanted elements.
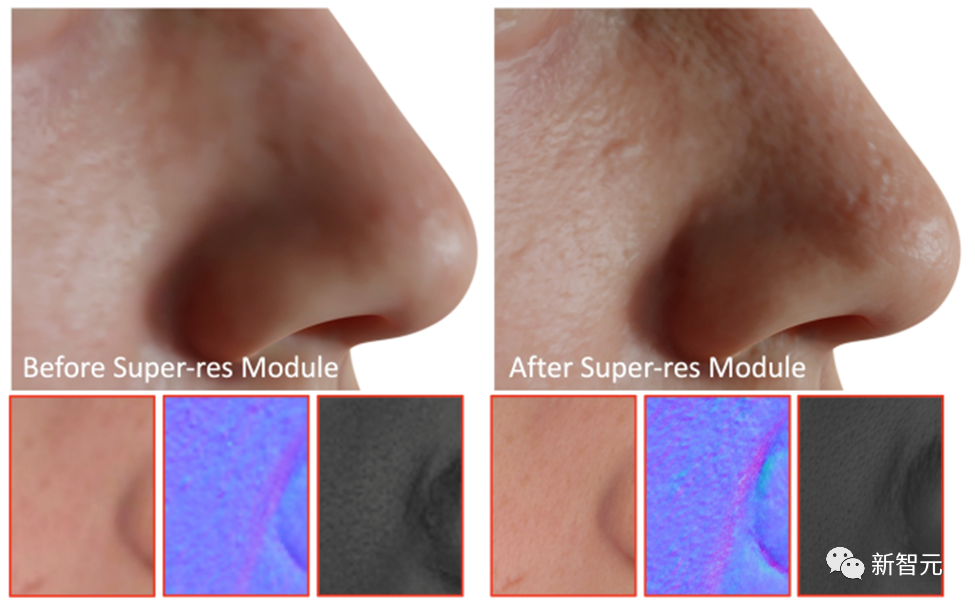
As the final step, DreamFace applies the Super-Resolution module to generate 4K physically-based textures for high-quality rendering.

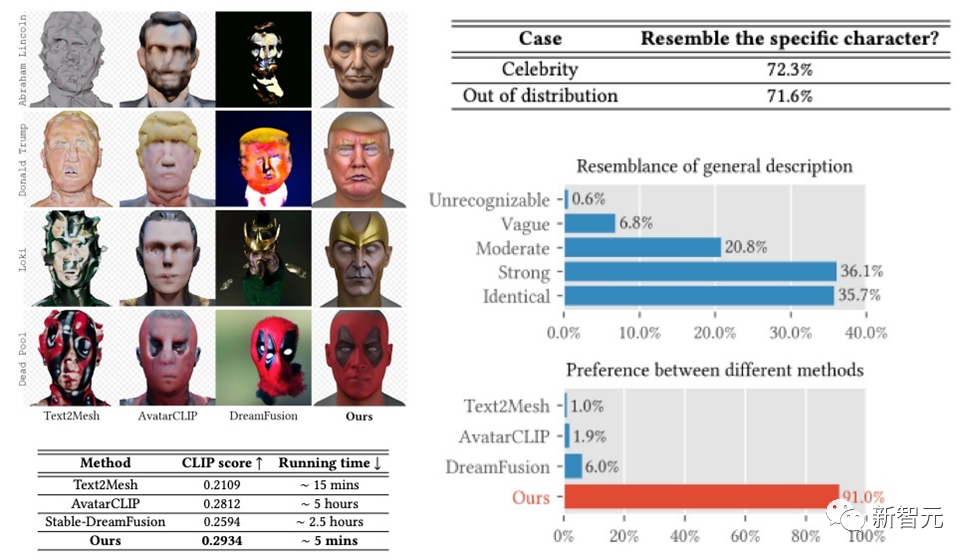
The DreamFace framework has achieved very good results in generating celebrities and generating characters based on descriptions. In the User Study Obtained results that far exceeded previous work. Compared with previous work, it also has obvious advantages in running time.
In addition to this, DreamFace also supports texture editing using hints and sketches. Global editing effects such as aging and makeup can be achieved by directly using fine-tuned texture LDMs and cues. By further combining masks or sketches, various effects can be created such as tattoos, beards, and birthmarks.

Animation ability generation
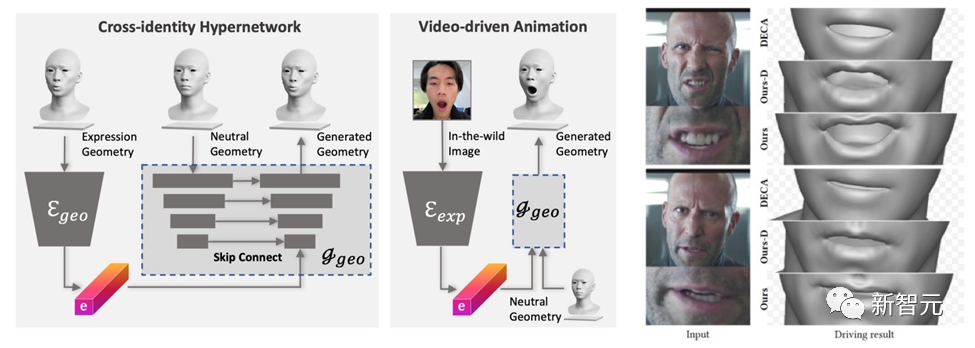
# #DreamFace generates models with animation capabilities. Unlike BlendShapes-based methods, DreamFace’s neural facial animation method produces personalized animations by predicting unique deformations to animate the resulting Neutral model.
First, a geometric generator is trained to learn the latent space of expressions, where the decoder is extended to be conditioned on neutral geometric shapes. Then, the expression encoder is further trained to extract expression features from RGB images. Therefore, DreamFace is able to generate personalized animations conditioned on neutral geometric shapes using monocular RGB images.
Compared to DECA, which uses generic BlendShapes for expression control, DreamFace's framework provides fine expression details and is able to capture performances with fine detail.
Conclusion
This paper introduces DreamFace, a text-guided progressive 3D generation framework that combines the latest visual-language models, implicit Diffusion models, and physically based material diffusion techniques.
DreamFace’s main innovations include geometry generation, physically based material diffusion generation and animation capability generation. Compared with traditional 3D generation methods, DreamFace has higher accuracy, faster running speed and better CG pipeline compatibility.
DreamFace’s progressive generation framework provides an effective solution for solving complex 3D generation tasks and is expected to promote more similar research and technology development.
In addition, physically based material diffusion generation and animation capability generation will promote the application of 3D generation technology in film and television production, game development and other related industries.
The above is the detailed content of Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'
May 17, 2023 am 08:02 AM
Shanghai University of Science and Technology and others released DreamFace: just text can generate a 'hyper-realistic 3D digital human'
May 17, 2023 am 08:02 AM
With the development of large language model (LLM), diffusion (Diffusion) and other technologies, the birth of products such as ChatGPT and Midjourney has set off a new wave of AI craze, and generative AI has also become a topic of great concern. Unlike text and images, 3D generation is still in the technology exploration stage. At the end of 2022, Google, NVIDIA, and Microsoft have successively launched their own 3D generation work, but most of them are based on advanced neural radiation field (NeRF) implicit expressions and are incompatible with the rendering pipelines of industrial 3D software such as Unity, UnrealEngine, and Maya. . Even if it is converted into a geometric and color map expressed by Mesh through traditional solutions, it will cause a lack of accuracy.
 Damn it, I'm surrounded by digital colleagues! Xiaobing AI digital employees are upgraded again, with zero-sample customization and immediate employment
Jul 19, 2024 pm 05:52 PM
Damn it, I'm surrounded by digital colleagues! Xiaobing AI digital employees are upgraded again, with zero-sample customization and immediate employment
Jul 19, 2024 pm 05:52 PM
"Hello, I have just joined our company. If I have any questions about business, please give me your advice!" What, these colleagues are all "digital people" driven by large models? It only takes 30 seconds of image, 10 seconds of audio, and 10 minutes to quickly customize a "digital colleague" that is no different from a real person. It can directly interact with you in real time, and has high-quality and low-latency audio and video transmission at the communication operator level. Like this: Like this: This is the latest "zero-shot Xiaoice Neural Rendering, Zero-XNR" technology launched by Xiaoice. Relying on a large model base of over 100 billion, new technology
 Large models are popular with digital people: one sentence can be customized in 5 minutes, and you can hold it while dancing, hosting and delivering goods
May 08, 2024 pm 08:10 PM
Large models are popular with digital people: one sentence can be customized in 5 minutes, and you can hold it while dancing, hosting and delivering goods
May 08, 2024 pm 08:10 PM
In as little as 5 minutes, you can create a 3D digital human that can go directly to work. This is the latest shock that large models have brought to the field of digital humans. Just like this, one sentence describes the demand: the generated digital people can directly enter the live broadcast room and serve as anchors. It's no problem to dance in a girl group dance. During the entire production process, just say whatever comes to mind. The large model can automatically disassemble the requirements, and you can get designs and modify ideas instantly. △With 2x speed, you no longer have to worry about the boss/Party A’s ideas being too novel. Such Vincent digital human technology comes from the latest release of Baidu Intelligent Cloud. It’s time to say it or not, but it’s time to cut down the barriers to digital people’s use in one fell swoop. After hearing about such an artifact, we immediately obtained the qualification for internal testing as usual. Let’s take a sneak peek at more details~ In 5 minutes in one sentence, the 3D digital man will be directly on duty.
 Yang Dong, Platform Technical Director of Unity Greater China: Starting the Digital Human Journey in the Metaverse
Apr 08, 2023 pm 06:11 PM
Yang Dong, Platform Technical Director of Unity Greater China: Starting the Digital Human Journey in the Metaverse
Apr 08, 2023 pm 06:11 PM
As the cornerstone of building Metaverse content, digital people are the earliest mature scenarios for metaverse subdivision that can be implemented and sustainably developed. Currently, commercial applications such as virtual idols, e-commerce delivery, TV hosting, and virtual anchors have been recognized by the public. In the world of the metaverse, one of the most core contents is none other than digital humans, because digital humans are not only the "incarnations" of real-world humans in the metaverse, they are also one of the important vehicles for us to carry out various interactions in the metaverse. one. It is well known that creating and rendering realistic digital human characters is one of the most difficult problems in computer graphics. Recently, at the MetaCon Metaverse Technology Conference "Games and AI Interaction" branch venue hosted by 51CTO, Unity Greater China Platform Technical Director Yang Dong gave a series of Demo demonstrations
 Digital people light the main torch of the Asian Games, and this ICCV paper reveals Ant's generative AI black technology
Sep 29, 2023 pm 11:57 PM
Digital people light the main torch of the Asian Games, and this ICCV paper reveals Ant's generative AI black technology
Sep 29, 2023 pm 11:57 PM
Open a digital human and it will be full of generative AI. On the evening of September 23, at the opening ceremony of the Hangzhou Asian Games, the lighting of the main torch showed the "little flames" of hundreds of millions of online digital torchbearers gathering on the Qiantang River, forming the image of a digital human. Then, the digital human torchbearer and the sixth torchbearer on site walked to the torch stage together and lit the main torch together. As the core idea of the opening ceremony, the digital-real-interconnected torch lighting format became a hot search topic, arousing people's interest. Focus. Rewritten content: As the core idea of the opening ceremony, the torch lighting method of Digital Reality Internet has aroused heated discussions and attracted people's attention. Digital human ignition is an unprecedented initiative. Hundreds of millions of people participated in it, involving a large number of advanced and Complex technology. One of the most important questions is how
 Human-computer interactive dialogue driven by large models
Apr 11, 2023 pm 07:27 PM
Human-computer interactive dialogue driven by large models
Apr 11, 2023 pm 07:27 PM
Introduction: Dialogue technology is one of the core capabilities of digital human interaction. This sharing mainly starts from the research and development and application related to Baidu PLATO, and talks about the impact of large models on dialogue systems and some opportunities for digital humans. The title of this sharing is : Human-computer interaction dialogue driven by large models. Today’s introduction starts from the following points: Dialogue system overview Baidu PLATO and related technology dialogue large model implementation, challenges and prospects 1. Dialogue system overview 1. Dialogue system overview In daily life, we often come into contact with some task-oriented tasks Dialogue systems, such as asking a mobile assistant to set an alarm or a smart speaker to play a song. The technology for this kind of vertical dialogue in a specific field is relatively mature, and the system design is usually modular, including dialogue understanding, dialogue management,
 AI digital human technology: empowering the video industry and opening the door to the future
Dec 20, 2023 pm 05:25 PM
AI digital human technology: empowering the video industry and opening the door to the future
Dec 20, 2023 pm 05:25 PM
In 2023, China's major e-commerce platforms will launch multiple live broadcast rooms, and these live broadcast rooms will be equipped with "digital human" anchors. These anchors can not only highly imitate the expressions and movements of real people, but can also live stream goods 24 hours a day, and can smoothly answer consumers' shopping questions. According to relevant statistics, there are currently nearly 140 million anchor accounts in China engaged in video performances and other activities, of which the proportion of virtual "digital people" has reached 40%. According to a virtual digital human industry report released by Orient Securities, it is expected that by 2030, The size of my country's virtual digital human market will reach 270 billion yuan. Mr. Han Kun, chairman of Xinyi Technology, presided over the press conference of the digital human image as China's leading artificial intelligence
 Film and TV drama promotion: Dimension Upgrade collaborates with N World to create 'Lotus Tower', a digital human that can talk to each other
Sep 08, 2023 pm 07:01 PM
Film and TV drama promotion: Dimension Upgrade collaborates with N World to create 'Lotus Tower', a digital human that can talk to each other
Sep 08, 2023 pm 07:01 PM
Have you ever imagined what it would be like to talk to the characters in your favorite movies and TV series? Things that could only be done in the "little theater in the brain" are now really possible! Recently, produced by Huanrui Century "Lotus Tower" hit the airwaves, setting off a summer drama-watching craze. With technical support provided by N World, a conversational AI digital human character has been customized for the characters in the "Lotus Tower" series. This is the first time that digital humans have been used in the promotion and distribution of a film and television series, allowing the audience to gain something different while watching the series. interactive experience. Huanrui Century is a leading group in the domestic film and television culture industry. In terms of film and television drama production, we insist on creating diversified high-quality content as the core, and rely on industrialized and systematic production capabilities to produce nearly 100 TV dramas and online dramas, with a cumulative click count of over 100 billion. In terms of artist management
