
 Backend Development
Python Tutorial
How to use the xlrd/xlwt/xlutils module for Python Excel data processing
Backend Development
Python Tutorial
How to use the xlrd/xlwt/xlutils module for Python Excel data processing
How to use the xlrd/xlwt/xlutils module for Python Excel data processing

Conventional Excel data processing involves reading/writing/file object operations on Excel data files.
The specific data processing business logic is implemented through the corresponding python non-standard library xlrd/xlwt/xlutils.
In the complex Excel business data processing, the three brothers play indispensable roles. Today our content is about how to use the three modules of xlrd/xlwt/xlutils to implement data processing.
1. Module Description
The best thing about using these three modules to process Excel data is that they have the same data processing concept as the Excel file object, which can better facilitate us. Understand data objects.
First of all, these three modules are non-standard libraries of python, and you can choose pip to install them.
pip install xlrd pip install xlwt pip install xlutils
The following is the source data content we prepared to demonstrate the data processing process, just for testing.
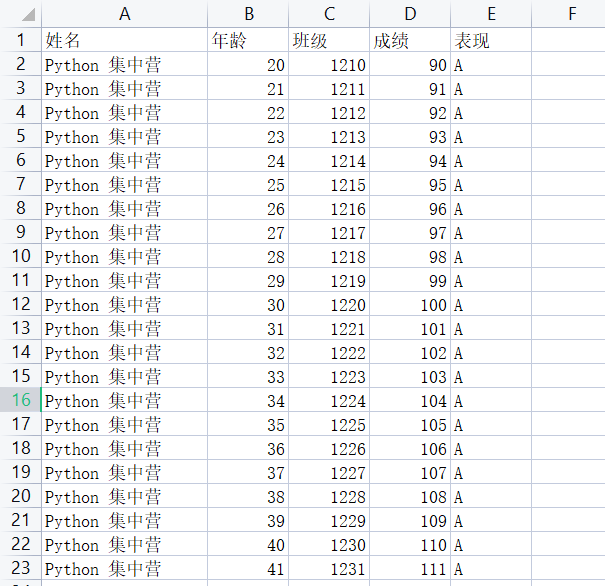
xlrd: used to read the Excel data file, put the returned data object into the memory, and then query the relevant information of the data file object.
xlwt: Used to generate a new data file object in the memory, and write it to the Excel data file after the processing is completed.
xlutils: The main function is to copy new file objects and complete data processing operations in new data objects.
Import the three modules xlrd/xlwt/xlutils into the code block to be developed to provide support.
# Importing the xlrd module. import xlrd as read # Importing the xlwt module. import xlwt as write # Copying the contents of the original workbook into a new workbook. from xlutils.copy import copy
2.
# Opening the workbook and assigning it to the variable `work_book`.
work_book = read.open_workbook('D:/test-data-work/test.xls')
# Assigning the sheet named 'Sheet1' to the variable `sheet`.
sheet = work_book.sheet_by_name('Sheet1')
# `row = sheet.nrows` is assigning the number of rows in the sheet to the variable `row`.
row = sheet.nrows
# `col = sheet.ncols` is assigning the number of columns in the sheet to the variable `col`.
col = sheet.ncols
print('Sheet1工作表有:{0}行,{1}列'.format(str(row), str(col)))
# Sheet1工作表有:23行,5列3.xlwt processing
for a in sheet.get_rows():
print(a)
# [text:'姓名', text:'年龄', text:'班级', text:'成绩', text:'表现']
# [text:'Python 集中营', number:20.0, number:1210.0, number:90.0, text:'A']
# [text:'Python 集中营', number:21.0, number:1211.0, number:91.0, text:'A']
# [text:'Python 集中营', number:22.0, number:1212.0, number:92.0, text:'A']
# [text:'Python 集中营', number:23.0, number:1213.0, number:93.0, text:'A']
# [text:'Python 集中营', number:24.0, number:1214.0, number:94.0, text:'A']
# [text:'Python 集中营', number:25.0, number:1215.0, number:95.0, text:'A']
# [text:'Python 集中营', number:26.0, number:1216.0, number:96.0, text:'A']
# [text:'Python 集中营', number:27.0, number:1217.0, number:97.0, text:'A']
# [text:'Python 集中营', number:28.0, number:1218.0, number:98.0, text:'A']
# [text:'Python 集中营', number:29.0, number:1219.0, number:99.0, text:'A']
# [text:'Python 集中营', number:30.0, number:1220.0, number:100.0, text:'A']
# [text:'Python 集中营', number:31.0, number:1221.0, number:101.0, text:'A']
# [text:'Python 集中营', number:32.0, number:1222.0, number:102.0, text:'A']
# [text:'Python 集中营', number:33.0, number:1223.0, number:103.0, text:'A']
# [text:'Python 集中营', number:34.0, number:1224.0, number:104.0, text:'A']
# [text:'Python 集中营', number:35.0, number:1225.0, number:105.0, text:'A']
# [text:'Python 集中营', number:36.0, number:1226.0, number:106.0, text:'A']
# [text:'Python 集中营', number:37.0, number:1227.0, number:107.0, text:'A']
# [text:'Python 集中营', number:38.0, number:1228.0, number:108.0, text:'A']
# [text:'Python 集中营', number:39.0, number:1229.0, number:109.0, text:'A']
# [text:'Python 集中营', number:40.0, number:1230.0, number:110.0, text:'A']
# [text:'Python 集中营', number:41.0, number:1231.0, number:111.0, text:'A']
for b in range(row):
print(sheet.row_values(b))
# ['姓名', '年龄', '班级', '成绩', '表现']
# ['Python 集中营', 20.0, 1210.0, 90.0, 'A']
# ['Python 集中营', 21.0, 1211.0, 91.0, 'A']
# ['Python 集中营', 22.0, 1212.0, 92.0, 'A']
# ['Python 集中营', 23.0, 1213.0, 93.0, 'A']
# ['Python 集中营', 24.0, 1214.0, 94.0, 'A']
# ['Python 集中营', 25.0, 1215.0, 95.0, 'A']
# ['Python 集中营', 26.0, 1216.0, 96.0, 'A']
# ['Python 集中营', 27.0, 1217.0, 97.0, 'A']
# ['Python 集中营', 28.0, 1218.0, 98.0, 'A']
# ['Python 集中营', 29.0, 1219.0, 99.0, 'A']
# ['Python 集中营', 30.0, 1220.0, 100.0, 'A']
# ['Python 集中营', 31.0, 1221.0, 101.0, 'A']
# ['Python 集中营', 32.0, 1222.0, 102.0, 'A']
# ['Python 集中营', 33.0, 1223.0, 103.0, 'A']
# ['Python 集中营', 34.0, 1224.0, 104.0, 'A']
# ['Python 集中营', 35.0, 1225.0, 105.0, 'A']
# ['Python 集中营', 36.0, 1226.0, 106.0, 'A']
# ['Python 集中营', 37.0, 1227.0, 107.0, 'A']
# ['Python 集中营', 38.0, 1228.0, 108.0, 'A']
# ['Python 集中营', 39.0, 1229.0, 109.0, 'A']
# ['Python 集中营', 40.0, 1230.0, 110.0, 'A']
# ['Python 集中营', 41.0, 1231.0, 111.0, 'A']
for c in range(col):
print(sheet.col_values(c))
# ['姓名', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营', 'Python 集中营']
# ['年龄', 20.0, 21.0, 22.0, 23.0, 24.0, 25.0, 26.0, 27.0, 28.0, 29.0, 30.0, 31.0, 32.0, 33.0, 34.0, 35.0, 36.0, 37.0, 38.0, 39.0, 40.0, 41.0]
# ['班级', 1210.0, 1211.0, 1212.0, 1213.0, 1214.0, 1215.0, 1216.0, 1217.0, 1218.0, 1219.0, 1220.0, 1221.0, 1222.0, 1223.0, 1224.0, 1225.0, 1226.0, 1227.0, 1228.0, 1229.0, 1230.0, 1231.0]
# ['成绩', 90.0, 91.0, 92.0, 93.0, 94.0, 95.0, 96.0, 97.0, 98.0, 99.0, 100.0, 101.0, 102.0, 103.0, 104.0, 105.0, 106.0, 107.0, 108.0, 109.0, 110.0, 111.0]
# ['表现', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A']4.xlutils processing
# Creating a new workbook.
work_book_2 = write.Workbook()
# Creating a new sheet named 'Sheet4' in the workbook.
sheet_2 = work_book_2.add_sheet('Sheet4')
list = [
['姓名', '年龄', '班级', '成绩'],
['张三', '20', '1210', '89'],
['李四', '21', '1211', '90'],
['王五', '22', '1212', '91'],
]
for row_index in range(4):
for col_index in range(4):
sheet_2.write(row_index, col_index, list[row_index][col_index])
col_index += 1
row_index += 1
# Saving the workbook to the specified location.
work_book_2.save('D:/test-data-work/test2.xls')The above is the detailed content of How to use the xlrd/xlwt/xlutils module for Python Excel data processing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Can the Python interpreter be deleted in Linux system?
Apr 02, 2025 am 07:00 AM
Regarding the problem of removing the Python interpreter that comes with Linux systems, many Linux distributions will preinstall the Python interpreter when installed, and it does not use the package manager...
 How to solve the problem of Pylance type detection of custom decorators in Python?
Apr 02, 2025 am 06:42 AM
How to solve the problem of Pylance type detection of custom decorators in Python?
Apr 02, 2025 am 06:42 AM
Pylance type detection problem solution when using custom decorator In Python programming, decorator is a powerful tool that can be used to add rows...
 Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
Python asyncio Telnet connection is disconnected immediately: How to solve server-side blocking problem?
Apr 02, 2025 am 06:30 AM
About Pythonasyncio...
 How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
How to solve permission issues when using python --version command in Linux terminal?
Apr 02, 2025 am 06:36 AM
Using python in Linux terminal...
 Python 3.6 loading pickle file error ModuleNotFoundError: What should I do if I load pickle file '__builtin__'?
Apr 02, 2025 am 06:27 AM
Python 3.6 loading pickle file error ModuleNotFoundError: What should I do if I load pickle file '__builtin__'?
Apr 02, 2025 am 06:27 AM
Loading pickle file in Python 3.6 environment error: ModuleNotFoundError:Nomodulenamed...
 Do FastAPI and aiohttp share the same global event loop?
Apr 02, 2025 am 06:12 AM
Do FastAPI and aiohttp share the same global event loop?
Apr 02, 2025 am 06:12 AM
Compatibility issues between Python asynchronous libraries In Python, asynchronous programming has become the process of high concurrency and I/O...
 What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?
Apr 02, 2025 am 07:12 AM
What should I do if the '__builtin__' module is not found when loading the Pickle file in Python 3.6?
Apr 02, 2025 am 07:12 AM
Error loading Pickle file in Python 3.6 environment: ModuleNotFoundError:Nomodulenamed...
 How to ensure that the child process also terminates after killing the parent process via signal in Python?
Apr 02, 2025 am 06:39 AM
How to ensure that the child process also terminates after killing the parent process via signal in Python?
Apr 02, 2025 am 06:39 AM
The problem and solution of the child process continuing to run when using signals to kill the parent process. In Python programming, after killing the parent process through signals, the child process still...
