

How to use ClickHouse in Python

ClickHouse is an open source columnar database (DBMS) that has attracted much attention in recent years. It is mainly used in the field of data online analysis (OLAP) and was open sourced in 2016. At present, the domestic community is booming, and major manufacturers have followed up and used it on a large scale.
Today's headlines use ClickHouse internally for user behavior analysis. There are thousands of ClickHouse nodes internally, with a maximum of 1,200 nodes in a single cluster. The total data volume is dozens of PB, and the original data increases by 300TB daily. about.
Tencent uses ClickHouse internally for game data analysis and has established a complete monitoring and operation system for it.
Since the trial began in July 2018, Ctrip has migrated 80% of its internal business to the ClickHouse database. Data increases by more than one billion every day, and nearly one million query requests are made.
Kuaishou is also using ClickHouse internally. The total storage capacity is about 10PB, with 200TB added every day, and 90% of queries are less than 3S.
Abroad, Yandex has hundreds of nodes used to analyze user click behavior, and leading companies such as CloudFlare and Spotify are also using it.
ClickHouse was originally developed to develop YandexMetrica, the world's second largest web analytics platform. It has been used continuously as a core component of the system for many years.
1. About ClickHouse usage practices
First, let’s review some basic concepts:
OLTP: It is a traditional relationship A database that mainly operates additions, deletions, modifications, and queries, emphasizing transaction consistency, such as banking systems and e-commerce systems.OLAP: It is a warehouse-type database that mainly reads data, performs complex data analysis, focuses on technical decision support, and provides intuitive and simple results.
1.1. ClickHouse is applied to data warehouse scenarios
ClickHouse is a columnar database, which is more suitable for OLAP scenarios. The key features of OLAP scenarios are:
The vast majority are read requests
The data is updated in fairly large batches (>1000 rows) rather than single row updates; or not at all renew.
Data that has been added to the database cannot be modified.
For reads, quite a few rows are fetched from the database, but only a small subset of the columns are fetched.
Wide tables, that is, each table contains a large number of columns
There are relatively few queries (usually hundreds of queries per second per server) times or less)
For simple queries, allow for a delay of about 50 milliseconds
The data in the columns is relatively small: numbers and short characters String (e.g., 60 bytes per URL)
Requires high throughput when processing a single query (up to billions of rows per second per server)
Transactions are not necessary
Low data consistency requirements
Each query has a large table. Except for him, everyone else is small.
The query result is significantly smaller than the source data. In other words, the data is filtered or aggregated so that the results fit within the RAM of a single server
1.2. Client tool DBeaver
Clickhouse client tool is dbeaver, The official website is https://dbeaver.io/.
dbeaver is a free and open source (GPL) general database tool for developers and database administrators. [Baidu Encyclopedia]
The core goal of this project is to improve ease of use, so we specially designed and developed a database management tool. Free, cross-platform, based on an open source framework and allows the writing of various extensions (plug-ins).
It supports any database with a JDBC driver.
It can handle any external data source.
Create and configure a new connection through "Database" in the operation interface menu, as shown in the figure below, select and download the ClickHouse driver (the default is no driver).

DBeaver configuration is based on Jdbc. Generally, the default URL and port are as follows:
jdbc:clickhouse://192.168.17.61:8123
As shown in the figure below.
When using DBeaver to connect to Clickhouse for query, sometimes the connection or query times out. At this time, you can add and set the socket_timeout parameter in the connection parameters to solve the problem.
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000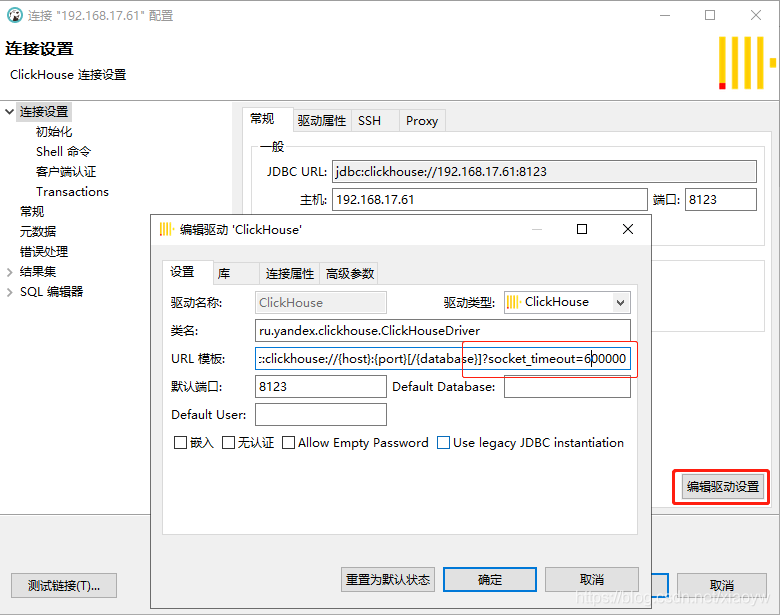
1.3. Big data application practice
Brief description of environment:
The hardware resources are limited, with only 16G of memory, and the transaction data is in the hundreds of millions.
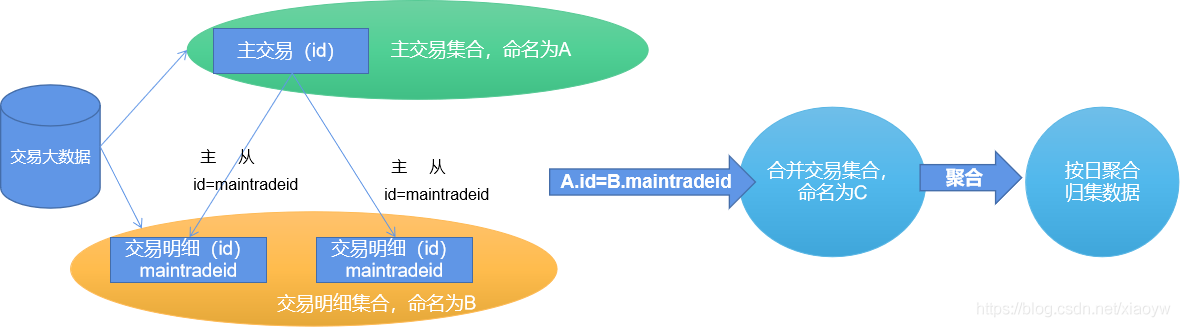
This application is a certain transaction big data, which mainly includes the transaction master table, related customer information, material information, historical prices, discounts and points information, etc. The main transaction table is a self-association tree. Table structure.
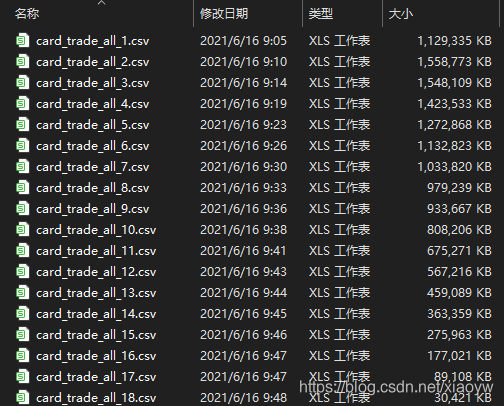
In order to analyze customer transaction behavior, under the conditions of limited resources, transaction details are extracted and compiled by day and transaction point into transaction records, as shown in the figure below.
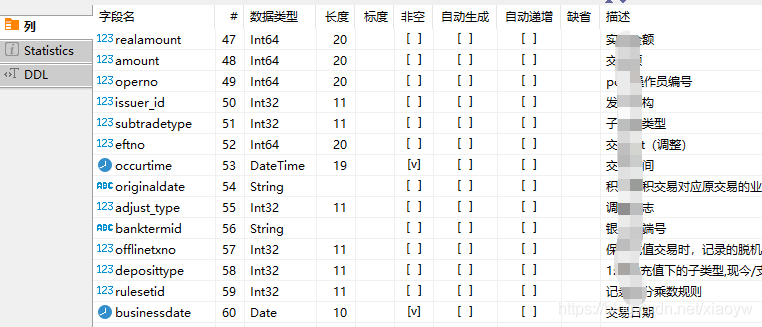
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
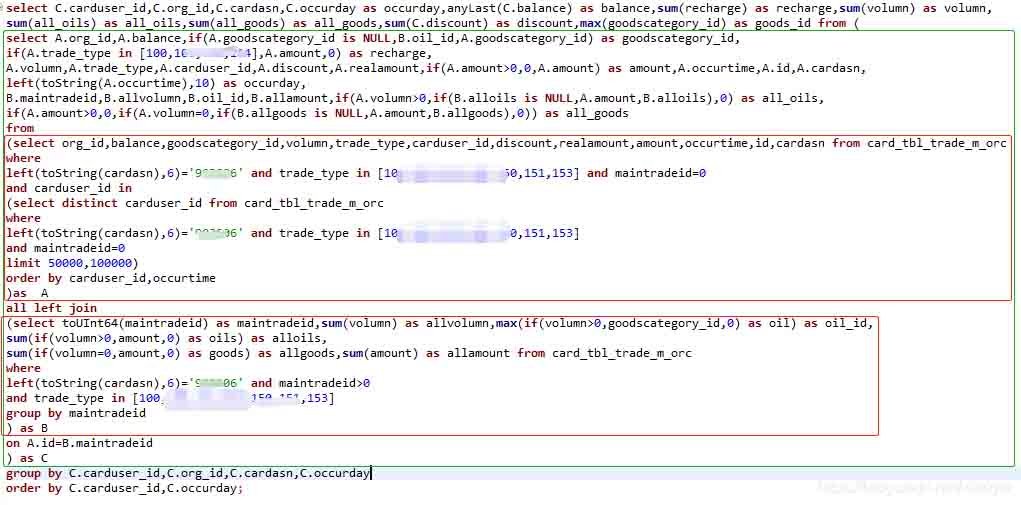
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()返回本地文件为:
3. 小结一下
ClickHouse运用于OLAP场景时,拥有出色的查询速度,但需要具备大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
The above is the detailed content of How to use ClickHouse in Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python: Automation, Scripting, and Task Management
Apr 16, 2025 am 12:14 AM
Python excels in automation, scripting, and task management. 1) Automation: File backup is realized through standard libraries such as os and shutil. 2) Script writing: Use the psutil library to monitor system resources. 3) Task management: Use the schedule library to schedule tasks. Python's ease of use and rich library support makes it the preferred tool in these areas.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 Can visual studio code run python
Apr 15, 2025 pm 08:00 PM
Can visual studio code run python
Apr 15, 2025 pm 08:00 PM
VS Code not only can run Python, but also provides powerful functions, including: automatically identifying Python files after installing Python extensions, providing functions such as code completion, syntax highlighting, and debugging. Relying on the installed Python environment, extensions act as bridge connection editing and Python environment. The debugging functions include setting breakpoints, step-by-step debugging, viewing variable values, and improving debugging efficiency. The integrated terminal supports running complex commands such as unit testing and package management. Supports extended configuration and enhances features such as code formatting, analysis and version control.
