
 Technology peripherals
AI
DAMO Academy's mPLUG-Owl debuts: a modular multi-modal large model, catching up with GPT-4 multi-modal capabilities
Technology peripherals
AI
DAMO Academy's mPLUG-Owl debuts: a modular multi-modal large model, catching up with GPT-4 multi-modal capabilities
DAMO Academy's mPLUG-Owl debuts: a modular multi-modal large model, catching up with GPT-4 multi-modal capabilities

Pure text large models are in the ascendant, and multimodal large model work has begun to emerge in the multimodal field. GPT-4, the strongest on the surface, has the multimodal ability to read images, but it has not yet been open to the public for experience, so The Hu research community began to research and open source in this direction. Shortly after the advent of MiniGPT-4 and LLaVA, Alibaba DAMO Academy launched mPLUG-Owl, a large multi-modal model based on modular implementation.
mPLUG-Owl is the latest work of the mPLUG series of Alibaba Damo Academy. It continues the modular training idea of the mPLUG series and upgrades the LLM into a large multi-modal model. In the mPLUG series of work, the previous E2E-VLP, mPLUG, and mPLUG-2 were accepted by ACL2021, EMNLP2022, and ICML2023 respectively. Among them, the mPLUG work topped the VQA list with superhuman results.
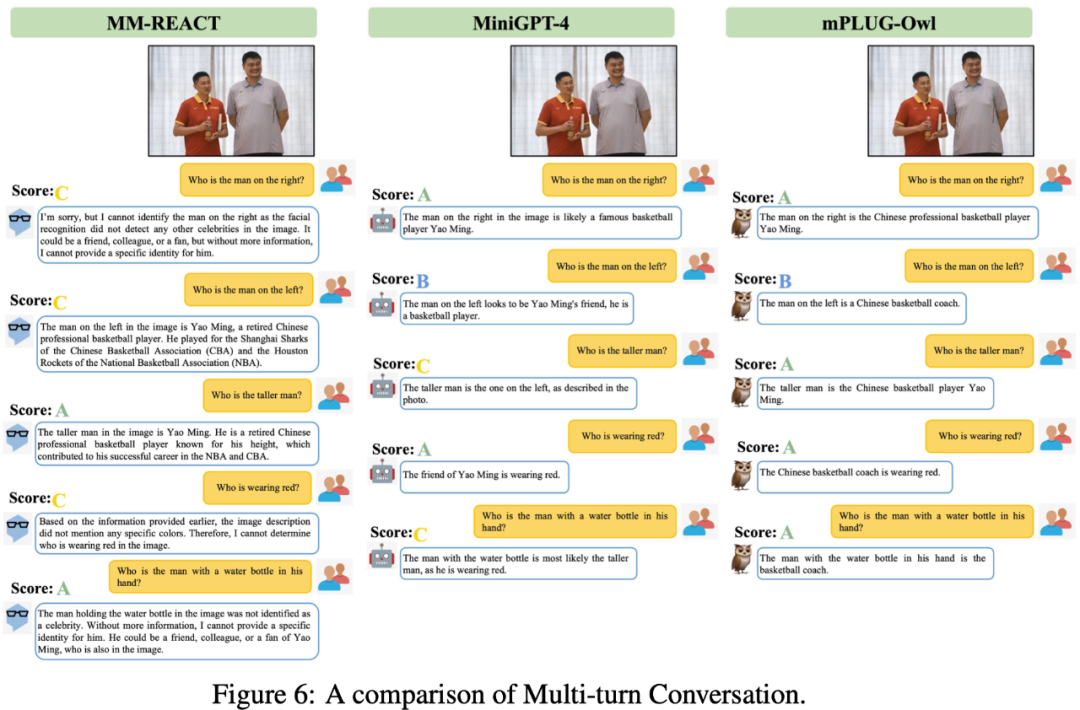
What I want to introduce today is mPLUG-Owl. This work not only demonstrates excellent multi-modal capabilities through a large number of cases, but also proposes a comprehensive test set for vision-related instruction understanding for the first time. OwlEval compared existing models through manual evaluation, including LLaVA, MiniGPT-4, BLIP-2 and system-based MM-REACT. The experimental results show that mPLUG-Owl exhibits better multi-modal capabilities, especially in multi-modal Outstanding performance in aspects such as the ability to understand dynamic instructions, multi-turn dialogue ability, and knowledge reasoning ability

##Paper link: https://arxiv.org/abs/2304.14178
Code link: https://github.com/X-PLUG /mPLUG-Owl
ModelScope experience address:
https://modelscope. cn/studios/damo/mPLUG-Owl/summary
HuggingFace experience address:
https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
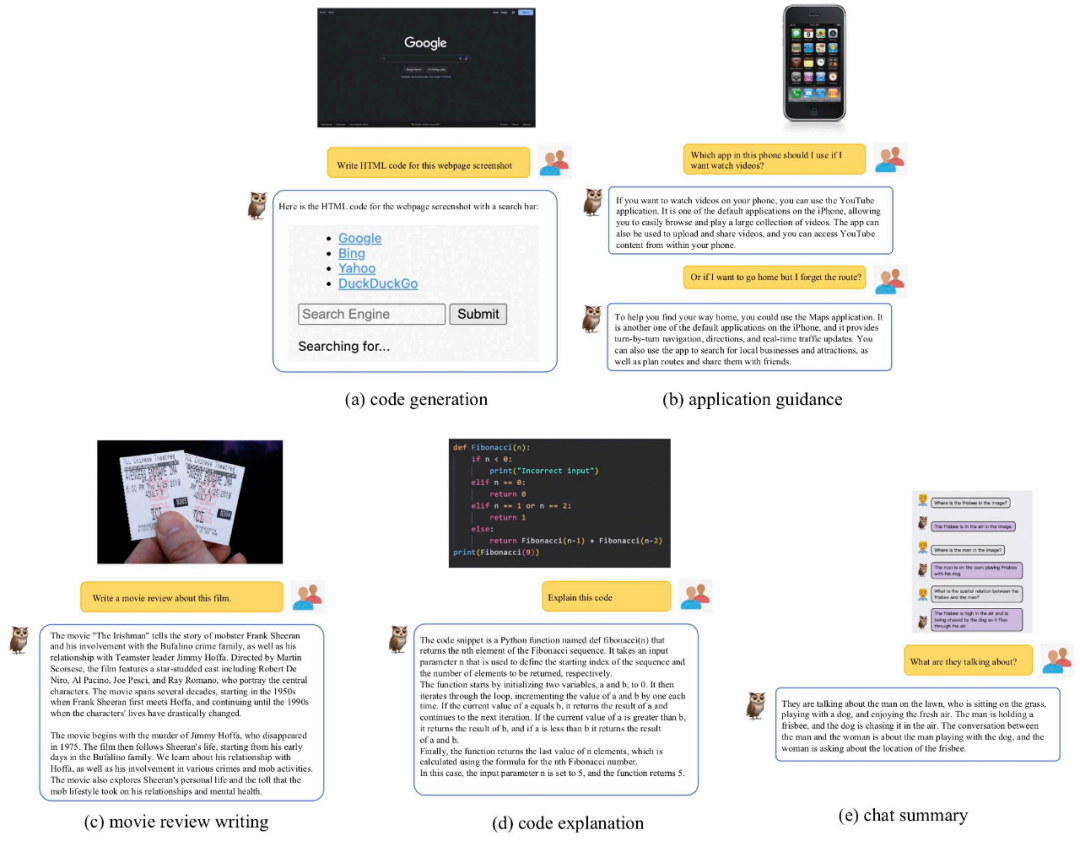
Multi-modal capability demonstrationWe combine mPLUG-Owl with existing Compare the work to feel the multi-modal effect of mPLUG-Owl. It is worth mentioning that the test samples evaluated in this work are basically from existing work, avoiding the cherry pick problem.
Figure 6 below shows mPLUG-Owl’s strong multi-round dialogue capabilities.
It can be found from Figure 7 that mPLUG-Owl has strong reasoning capabilities.

Figure 9 shows some examples of joke explanations.

As shown in Figure 10, although multi-graph correlation data was not trained during the training phase, mPLUG-Owl has demonstrated certain multi-graph correlation capabilities.


Although mPLUG-Owl was not trained on annotated document data, it still demonstrated certain text recognition and document understanding. Capability, the test results are shown in Figure 12.
Method introduction
The overall architecture of mPLUG-Owl proposed in this work is shown in Figure 2 Show.
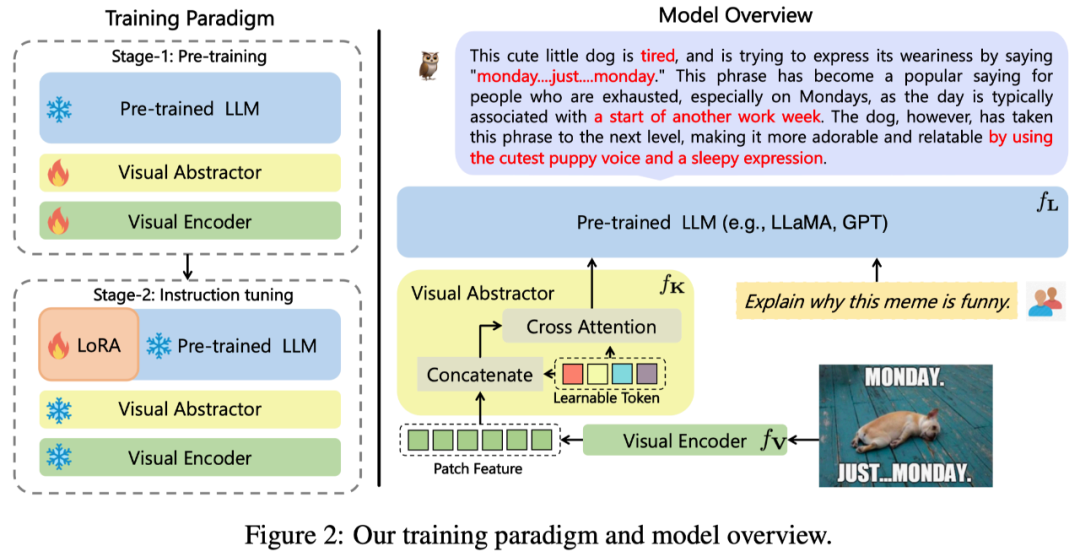
## Model structure: It consists of the visual basic module
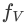
(open source ViT-L), visual abstraction module
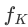
and pre-trained language model
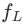
(LLaMA-7B) Composition. The visual abstraction module summarizes longer, fine-grained image features into a small number of learnable Tokens, thereby achieving efficient modeling of visual information. The generated visual tokens are input into the language model together with the text query to generate corresponding responses.
Model training: adopt a two-stage training method
The first stage: the main purpose is also to first Learn the opposition between visual and verbal modalities. Different from previous work, mPLUG-Owl proposes that freezing the basic visual module will limit the model's ability to associate visual knowledge and textual knowledge. Therefore, mPLUG-Owl only freezes the parameters of LLM in the first stage, and uses LAION-400M, COYO-700M, CC and MSCOCO to train the visual basic module and visual summary module.
The second stage: Continuing the discovery that mixed training of different modalities in mPLUG and mPLUG-2 are beneficial to each other, Owl also uses pure training in the second stage of instruction fine-tuning training. Textual command data (52k from Alpaca 90k from Vicuna 50k from Baize) and multimodal command data (150k from LLaVA). Through detailed ablation experiments, the author verified the benefits brought by the introduction of pure text instruction fine-tuning in aspects such as instruction understanding. In the second stage, the parameters of the visual basic module, visual summary module and the original LLM are frozen. Referring to LoRA, only an adapter structure with a small number of parameters is introduced in the LLM for instruction fine-tuning.
Experimental resultsSOTA comparison
In order to compare the multi-modal capabilities of different models, This work builds a multi-modal instruction evaluation set OwlEval. Since there are currently no suitable automated indicators, refer to Self-Intruct for manual evaluation of the model's responses. The scoring rules are: A="Correct and satisfactory"; B="Some imperfections, but acceptable"; C ="Understood the instructions but there were obvious errors in the responses"; D="Completely irrelevant or incorrect responses".
The comparison results are shown in Figure 3 below. Experiments prove that Owl is superior to existing OpenFlamingo, BLIP-2, LLaVA, and MiniGPT-4 in visual-related command response tasks.
Multi-dimensional ability comparison
Multimodal command response tasks involve a variety of abilities, such as command understanding, visual understanding, text understanding on pictures, and reasoning. In order to explore the level of different capabilities of the model in a fine-grained manner, this article further defines 6 main capabilities in multi-modal scenarios, and manually annotates each OwlEval test instruction with relevant capability requirements and the model's responses reflected in them. What abilities have been acquired.
The results are shown in Table 6 below. In this part of the experiment, the author not only conducted Owl ablation experiments to verify the effectiveness of the training strategy and multi-modal instruction fine-tuning data, but also The best-performing baseline in the previous experiment—MiniGPT4—was compared, and the results showed that Owl was superior to MiniGPT4 in all aspects of capabilities.
The above is the detailed content of DAMO Academy's mPLUG-Owl debuts: a modular multi-modal large model, catching up with GPT-4 multi-modal capabilities. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
