
 Technology peripherals
AI
Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss
Technology peripherals
AI
Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss
Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss

Introduction
Word embedding representation is the basis for various natural language processing tasks such as machine translation, question answering, text classification, etc. It usually accounts for 20% to 90% of the total model parameters. Storing and accessing these embeddings requires a large amount of space, which is not conducive to model deployment and application on devices with limited resources. In response to this problem, this article proposes the MorphTE word embedding compression method. MorphTE combines the powerful compression capabilities of tensor product operations with prior knowledge of language morphology to achieve high compression of word embedding parameters (more than 20 times) while maintaining the accuracy of the model. performance.

- ## Paper link: https://arxiv.org/abs/2210.15379
- Open source code: https://github.com/bigganbing/Fairseq_MorphTE
This article proposes The MorphTE word embedding compression method first divides words into the smallest units with semantic meaning - morphemes, and trains a low-dimensional vector representation for each morpheme, and then uses tensor products to realize the mathematical representation of quantum entangled states of low-dimensional morpheme vectors. , thereby obtaining a high-dimensional word representation.
01 The morpheme composition of a wordIn linguistics, a morpheme is the smallest unit with specific semantic or grammatical functions. For languages such as English, a word can be split into smaller units of morphemes such as roots and affixes. For example, "unkindly" can be broken down into "un" for negation, "kind" for something like "friendly," and "ly" for an adverb. For Chinese, a Chinese character can also be split into smaller units such as radicals. For example, "MU" can be split into "氵" and "木" which represent water.

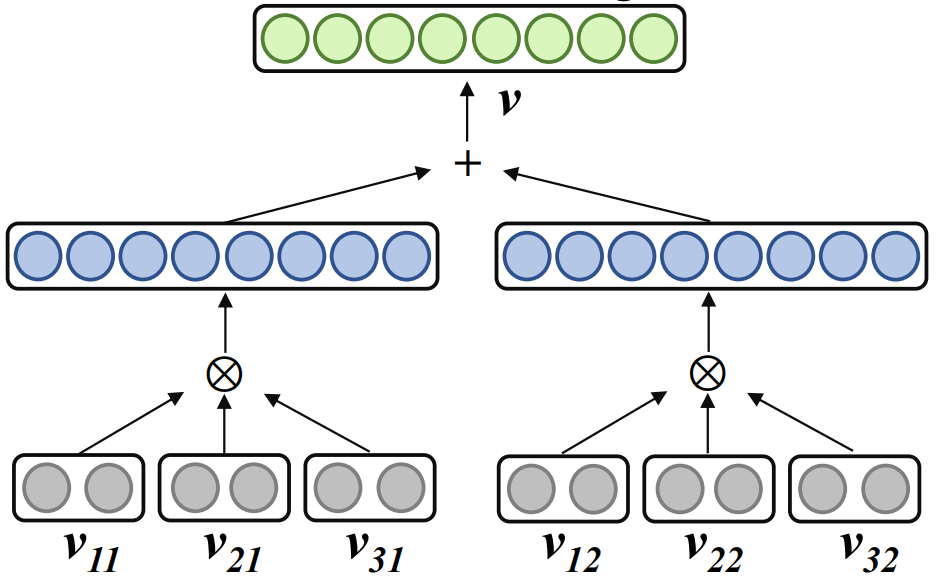
02 Compressed representation of word embeddings in the form of entangled tensors
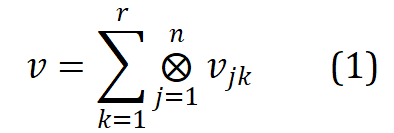 ##where
##where
, r is rank, n is order, represents tensor product. Word2ket only needs to store and use these low-dimensional vectors to build high-dimensional word vectors, thereby achieving effective parameter reduction. For example, when r = 2 and n = 3, a word vector with a dimension of 512 can be obtained by two groups of three low-dimensional vector tensor products with a dimension of 8 in each group. At this time, the required number of parameters is reduced from 512 to 48 . 03 Morphology-enhanced tensorized word embedding compression representation
Through tensor product, Word2ket can achieve obvious parameter compression. However, it suffers from high compression and machine translation problems. For more complex tasks, it is usually difficult to achieve the effect before compression. Since low-dimensional vectors are the basic units that make up entanglement tensors, and morphemes are the basic units that make up words. This study considers the introduction of linguistic knowledge and proposes MorphTE, which trains low-dimensional morpheme vectors and uses the tensor product of the morpheme vectors contained in the word to construct the corresponding word embedding representation.
Specifically, first use the morpheme segmentation tool to segment the words in the word list V. The morphemes of all words will form a morpheme list M, and the number of morphemes will be significantly lower than the number of words ().
For each word, construct its morpheme index vector, which points to the position of the morpheme contained in each word in the morpheme table. The morpheme index vectors of all words form a 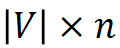 morpheme index matrix, where n is the order of MorphTE.
morpheme index matrix, where n is the order of MorphTE.
For the j-th word 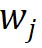 in the vocabulary, use its morpheme index vector
in the vocabulary, use its morpheme index vector 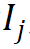 to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:
to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:
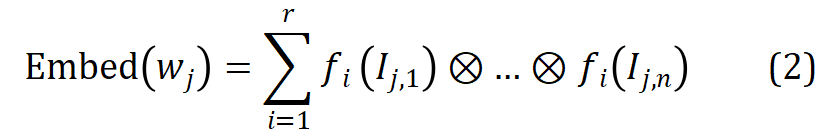
Through the above methods, MophTE can inject morpheme-based linguistic prior knowledge into the word embedding representation, and the sharing of morpheme vectors between different words can explicitly build inter-word connections. In addition, the number and vector dimensions of morphemes are much lower than the size and dimension of the vocabulary, and MophTE achieves compression of word embedding parameters from both perspectives. Therefore, MophTE is able to achieve high-quality compression of word embedding representations.
Experiments
This article mainly conducts experiments on translation, question and answer tasks in different languages, and compares it with related decomposition-based word embedding compression methods.
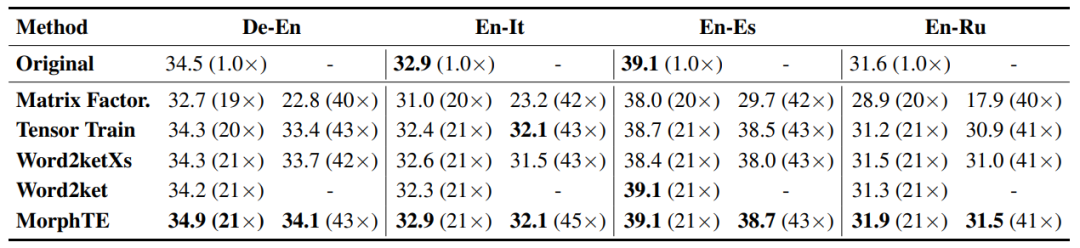
As you can see from the table, MorphTE can adapt to different languages such as English, German, and Italian. At a compression ratio of more than 20 times, MorphTE is able to maintain the effect of the original model, while almost all other compression methods show a decrease in effect. In addition, MorphTE performs better than other compression methods on different data sets at a compression ratio of more than 40 times.
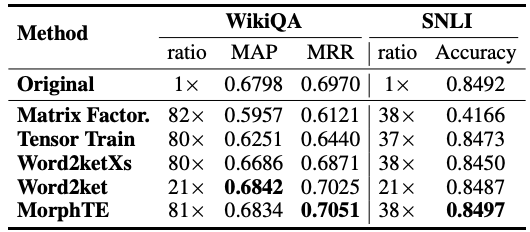
Similarly, MorphTE achieved a compression ratio of 81 times and 38 times respectively on WikiQA's question and answer task and SNLI's natural language reasoning task. , while maintaining the effect of the model.
Conclusion
MorphTE combines a priori morphological language knowledge and the powerful compression capability of tensor products to achieve high-quality compression of word embeddings. Experiments on different languages and tasks show that MorphTE can achieve 20 to 80 times compression of word embedding parameters without damaging the effect of the model. This verifies that the introduction of morpheme-based linguistic knowledge can improve the learning of compressed representations of word embeddings. Although MorphTE currently only models morphemes, it can actually be extended into a general word embedding compression enhancement framework that explicitly models more a priori linguistic knowledge such as prototypes, parts of speech, capitalization, etc., to further improve word embedding compression. express.
The above is the detailed content of Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to write a novel in the Tomato Free Novel app. Share the tutorial on how to write a novel in Tomato Novel.
Mar 28, 2024 pm 12:50 PM
How to write a novel in the Tomato Free Novel app. Share the tutorial on how to write a novel in Tomato Novel.
Mar 28, 2024 pm 12:50 PM
Tomato Novel is a very popular novel reading software. We often have new novels and comics to read in Tomato Novel. Every novel and comic is very interesting. Many friends also want to write novels. Earn pocket money and edit the content of the novel you want to write into text. So how do we write the novel in it? My friends don’t know, so let’s go to this site together. Let’s take some time to look at an introduction to how to write a novel. Share the Tomato novel tutorial on how to write a novel. 1. First open the Tomato free novel app on your mobile phone and click on Personal Center - Writer Center. 2. Jump to the Tomato Writer Assistant page - click on Create a new book at the end of the novel.
 How to enter bios on Colorful motherboard? Teach you two methods
Mar 13, 2024 pm 06:01 PM
How to enter bios on Colorful motherboard? Teach you two methods
Mar 13, 2024 pm 06:01 PM
Colorful motherboards enjoy high popularity and market share in the Chinese domestic market, but some users of Colorful motherboards still don’t know how to enter the bios for settings? In response to this situation, the editor has specially brought you two methods to enter the colorful motherboard bios. Come and try it! Method 1: Use the U disk startup shortcut key to directly enter the U disk installation system. The shortcut key for the Colorful motherboard to start the U disk with one click is ESC or F11. First, use Black Shark Installation Master to create a Black Shark U disk boot disk, and then turn on the computer. When you see the startup screen, continuously press the ESC or F11 key on the keyboard to enter a window for sequential selection of startup items. Move the cursor to the place where "USB" is displayed, and then
 How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
How to recover deleted contacts on WeChat (simple tutorial tells you how to recover deleted contacts)
May 01, 2024 pm 12:01 PM
Unfortunately, people often delete certain contacts accidentally for some reasons. WeChat is a widely used social software. To help users solve this problem, this article will introduce how to retrieve deleted contacts in a simple way. 1. Understand the WeChat contact deletion mechanism. This provides us with the possibility to retrieve deleted contacts. The contact deletion mechanism in WeChat removes them from the address book, but does not delete them completely. 2. Use WeChat’s built-in “Contact Book Recovery” function. WeChat provides “Contact Book Recovery” to save time and energy. Users can quickly retrieve previously deleted contacts through this function. 3. Enter the WeChat settings page and click the lower right corner, open the WeChat application "Me" and click the settings icon in the upper right corner to enter the settings page.
 How to set font size on mobile phone (easily adjust font size on mobile phone)
May 07, 2024 pm 03:34 PM
How to set font size on mobile phone (easily adjust font size on mobile phone)
May 07, 2024 pm 03:34 PM
Setting font size has become an important personalization requirement as mobile phones become an important tool in people's daily lives. In order to meet the needs of different users, this article will introduce how to improve the mobile phone use experience and adjust the font size of the mobile phone through simple operations. Why do you need to adjust the font size of your mobile phone - Adjusting the font size can make the text clearer and easier to read - Suitable for the reading needs of users of different ages - Convenient for users with poor vision to use the font size setting function of the mobile phone system - How to enter the system settings interface - In Find and enter the "Display" option in the settings interface - find the "Font Size" option and adjust it. Adjust the font size with a third-party application - download and install an application that supports font size adjustment - open the application and enter the relevant settings interface - according to the individual
 Summary of methods to obtain administrator rights in Win11
Mar 09, 2024 am 08:45 AM
Summary of methods to obtain administrator rights in Win11
Mar 09, 2024 am 08:45 AM
A summary of how to obtain Win11 administrator rights. In the Windows 11 operating system, administrator rights are one of the very important permissions that allow users to perform various operations on the system. Sometimes, we may need to obtain administrator rights to complete some operations, such as installing software, modifying system settings, etc. The following summarizes some methods for obtaining Win11 administrator rights, I hope it can help you. 1. Use shortcut keys. In Windows 11 system, you can quickly open the command prompt through shortcut keys.
 The secret of hatching mobile dragon eggs is revealed (step by step to teach you how to successfully hatch mobile dragon eggs)
May 04, 2024 pm 06:01 PM
The secret of hatching mobile dragon eggs is revealed (step by step to teach you how to successfully hatch mobile dragon eggs)
May 04, 2024 pm 06:01 PM
Mobile games have become an integral part of people's lives with the development of technology. It has attracted the attention of many players with its cute dragon egg image and interesting hatching process, and one of the games that has attracted much attention is the mobile version of Dragon Egg. To help players better cultivate and grow their own dragons in the game, this article will introduce to you how to hatch dragon eggs in the mobile version. 1. Choose the appropriate type of dragon egg. Players need to carefully choose the type of dragon egg that they like and suit themselves, based on the different types of dragon egg attributes and abilities provided in the game. 2. Upgrade the level of the incubation machine. Players need to improve the level of the incubation machine by completing tasks and collecting props. The level of the incubation machine determines the hatching speed and hatching success rate. 3. Collect the resources required for hatching. Players need to be in the game
 Detailed explanation of Oracle version query method
Mar 07, 2024 pm 09:21 PM
Detailed explanation of Oracle version query method
Mar 07, 2024 pm 09:21 PM
Detailed explanation of Oracle version query method Oracle is one of the most popular relational database management systems in the world. It provides rich functions and powerful performance and is widely used in enterprises. In the process of database management and development, it is very important to understand the version of the Oracle database. This article will introduce in detail how to query the version information of the Oracle database and give specific code examples. Query the database version of the SQL statement in the Oracle database by executing a simple SQL statement
 Quickly master: How to open two WeChat accounts on Huawei mobile phones revealed!
Mar 23, 2024 am 10:42 AM
Quickly master: How to open two WeChat accounts on Huawei mobile phones revealed!
Mar 23, 2024 am 10:42 AM
In today's society, mobile phones have become an indispensable part of our lives. As an important tool for our daily communication, work, and life, WeChat is often used. However, it may be necessary to separate two WeChat accounts when handling different transactions, which requires the mobile phone to support logging in to two WeChat accounts at the same time. As a well-known domestic brand, Huawei mobile phones are used by many people. So what is the method to open two WeChat accounts on Huawei mobile phones? Let’s reveal the secret of this method. First of all, you need to use two WeChat accounts at the same time on your Huawei mobile phone. The easiest way is to
