
 Technology peripherals
AI
GPT-4 wins the new SOTA of the most difficult mathematical reasoning data set, and the new Prompting greatly improves the reasoning capabilities of large models
Technology peripherals
AI
GPT-4 wins the new SOTA of the most difficult mathematical reasoning data set, and the new Prompting greatly improves the reasoning capabilities of large models
GPT-4 wins the new SOTA of the most difficult mathematical reasoning data set, and the new Prompting greatly improves the reasoning capabilities of large models

Recently, Huawei Lianhe Port Chinese published a paper "Progressive-Hint Prompting Improves Reasoning in Large Language Models", proposing Progressive-Hint Prompting (PHP) to simulate the human question-taking process. Under the PHP framework, Large Language Model (LLM) can use the reasoning answers generated in the past few times as hints for subsequent reasoning, gradually getting closer to the final correct answer. To use PHP, you only need to meet two requirements: 1) the question can be merged with the inference answer to form a new question; 2) the model can handle this new question and give a new inference answer.
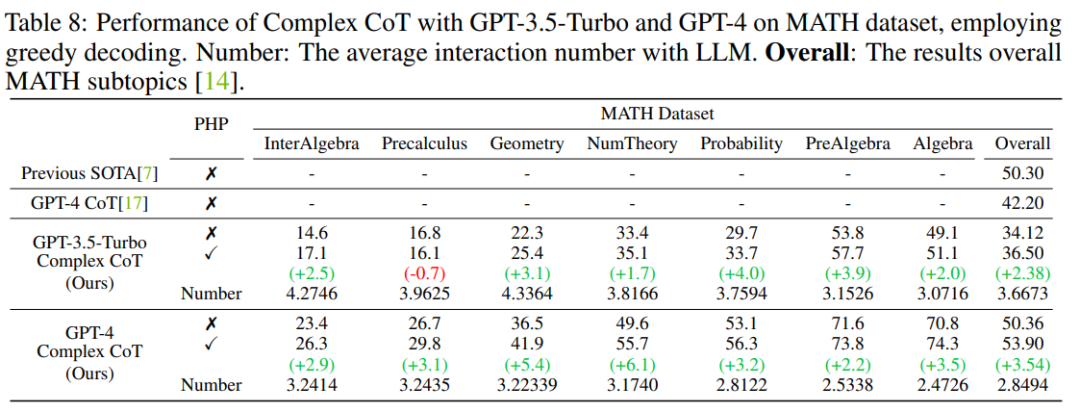
The results show that GP-T-4 PHP achieves SOTA results on multiple datasets, including SVAMP ( 91.9%), AQuA (79.9%), GSM8K (95.5%) and MATH (53.9%). This method significantly outperforms GPT-4 CoT. For example, on the most difficult mathematical reasoning data set MATH, GPT-4 CoT is only 42.5%, while GPT-4 PHP improves by 6.1% on the Nember Theory (number theory) subset of the MATH data set, raising the overall MATH to 53.9% , reaching SOTA.

- ##Paper link: https://arxiv .org/abs/2304.09797
- Code link: https://github.com/chuanyang-Zheng/Progressive-Hint
With the development of LLM, some work on prompting has emerged, among which there are two mainstream directions:
- One is represented by Chain-Of-Thought (CoT, chain of thought), which stimulates the reasoning ability of the model by clearly writing down the reasoning process;
- The other is represented by Self- Consistency (SC) is represented by sampling multiple answers and then voting to get the final answer.
Obviously, the two existing methods do not make any modifications to the question, which is equivalent to finishing the question once, without going back to the answer. double check. PHP tries to simulate a more human-like reasoning process: process the last reasoning process, then merge it into the original question, and ask LLM to reason again. When the two most recent inference answers are consistent, the obtained answer is accurate and the final answer will be returned. The specific flow chart is as follows:

When you interact with LLM for the first time, you should use Base Prompting ( Basic prompt), where the prompt (prompt) can be Standard prompt, CoT prompt or an improved version thereof. With Base Prompting, you can have a first interaction and get a preliminary answer. In subsequent interactions, PHP should be used until the two most recent answers agree.
PHP prompt is modified based on Base Prompt. Given a Base Prompt, the corresponding PHP prompt can be obtained through the formulated PHP prompt design principles. As shown in the figure below:

1) If the given Hint is the correct answer, the returned answer must still be the correct answer (specifically, "Hint is the correct answer" as shown in the figure above);
2) If the given Hint is an incorrect answer, then LLM must use reasoning to jump out of the Hint of the incorrect answer and return the correct answer (specifically, "Hint is the incorrect answer" as shown in the figure above).
According to this PHP prompt design rule, given any existing Base Prompt, the author can set the corresponding PHP Prompt.
The authors use seven data sets, including AddSub, MultiArith, SingleEQ, SVAMP, GSM8K, AQuA and MATH. At the same time, the author used a total of four models to verify the author's ideas, including text-davinci-002, text-davinci-003, GPT-3.5-Turbo and GPT-4. Main resultsExperiments
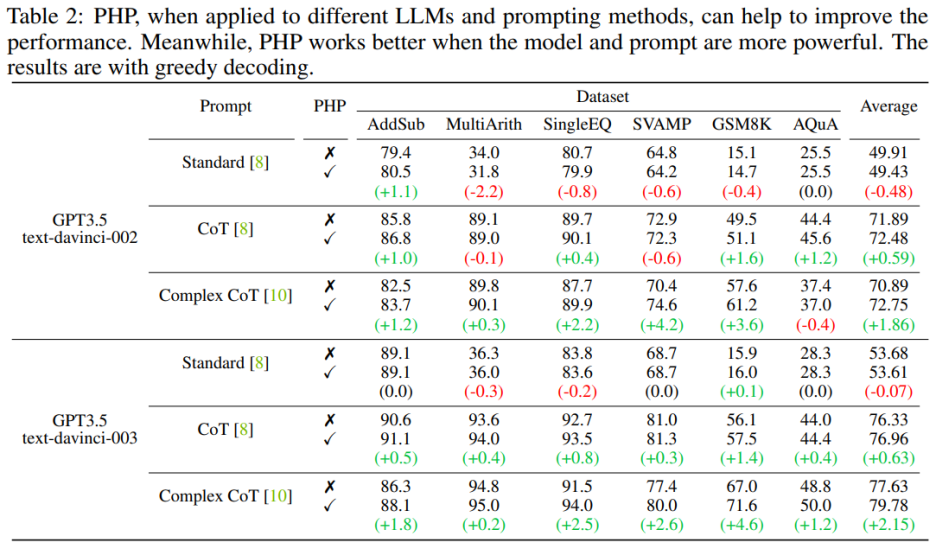
##When language model PHP works better when it is more powerful and prompts more effectively. Complex CoT prompt shows significant performance improvements compared to Standard Prompt and CoT Prompt. The analysis also shows that the text-davinci-003 language model fine-tuned using reinforcement learning performs better than the text-davinci-002 model fine-tuned using supervised instructions, improving document performance. The performance improvements of text-davinci-003 are attributed to its enhanced ability to better understand and apply a given prompt. At the same time, if you just use the Standard prompt, the improvement brought by PHP is not obvious. If PHP needs to be effective, at least CoT is needed to stimulate the model's reasoning capabilities.
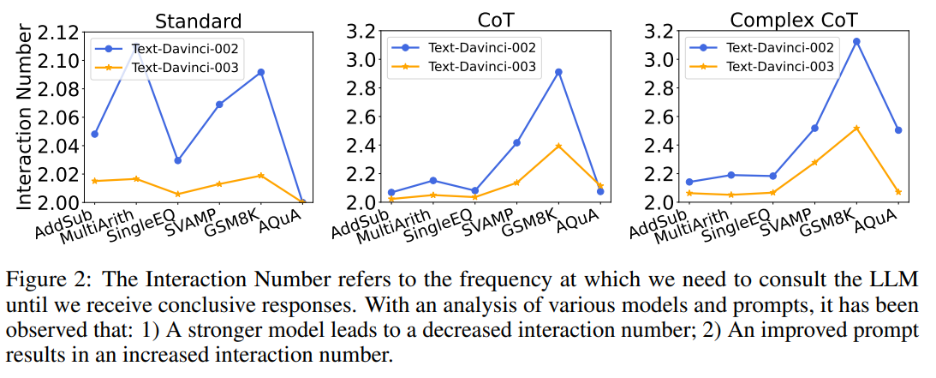
At the same time, the author also explored the relationship between the number of interactions and the model and prompt. When the language model is stronger and the cues are weaker, the number of interactions decreases. The number of interactions refers to the number of times the agent interacts with LLMs. When the first answer is received, the number of interactions is 1; when the second answer is received, the number of interactions increases to 2. In Figure 2, the authors show the number of interactions for various models and prompts. The author's research results show that:
1) Given the same prompt, the number of interactions of text-davinci-003 is generally lower than that of text-davinci-002. This is mainly due to the higher accuracy of text-davinci-003, which results in the base answer and subsequent answers being more correct, thus requiring less interaction to get the final correct answer;
2) When using the same model, the number of interactions usually increases as the prompt becomes more powerful. This is because when prompts become more effective, LLMs' reasoning abilities are better utilized, allowing them to use the prompts to jump to wrong answers, ultimately resulting in a higher number of interactions being required to reach the final answer, which increases the number of interactions .
Hint Quality Impact
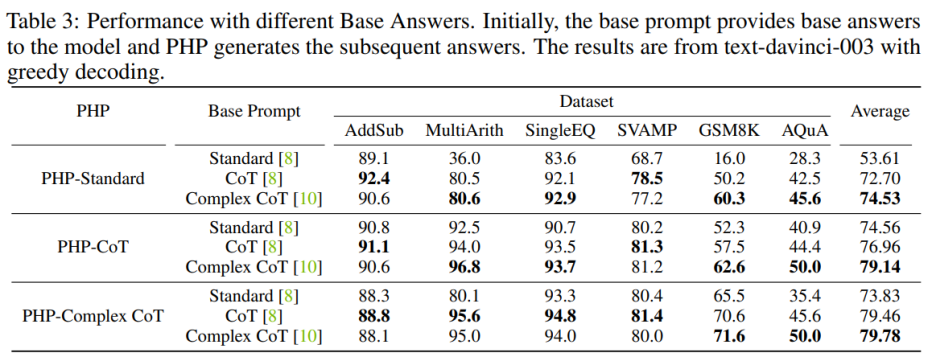
For To enhance the performance of PHP-Standard, replacing Base Prompt Standard with Complex CoT or CoT can significantly improve the final performance. For PHP-Standard, the authors observed that the performance of GSM8K improved from 16.0% under Base Prompt Standard to 50.2% under Base Prompt CoT to 60.3% under Base Prompt Complex CoT. Conversely, if you replace Base Prompt Complex CoT with Standard, you will end up with lower performance. For example, after replacing the base prompt Complex CoT with Standard, the performance of PHP-Complex CoT dropped from 71.6% to 65.5% on the GSM8K dataset.
If PHP is not designed based on the corresponding Base Prompt, the effect may be further improved. PHP-CoT using Base Prompt Complex CoT performed better than PHP-CoT using CoT on four of the six datasets. Likewise, PHP-Complex CoT using Base Prompt CoT performs better than PHP-Complex CoT using Base Prompt Complex CoT in four of the six datasets. The author speculates that this is because of two reasons: 1) on all six data sets, the performance of CoT and Complex CoT is similar; 2) because the Base Answer is provided by CoT (or Complex CoT), and the subsequent answers are based on PHP-Complex CoT (or PHP-CoT), which is the equivalent of two people working together to solve a problem. Therefore, in this case, the performance of the system may be further improved.
Ablation experiment
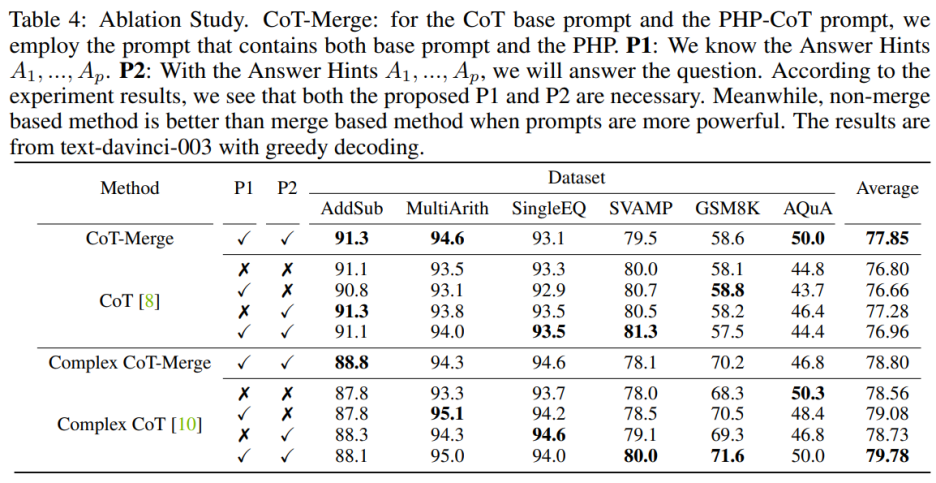
Incorporating sentences P1 and P2 into the model can improve the performance of CoT on the three data sets, but when using the Complex CoT method, these two The importance of this sentence is particularly obvious. After adding P1 and P2, the method's performance is improved in five of the six datasets. For example, the performance of Complex CoT improves from 78.0% to 80.0% on the SVAMP dataset and from 68.3% to 71.6% on the GSM8K dataset. This shows that, especially when the model's logical ability is stronger, the effect of sentences P1 and P2 is more significant.
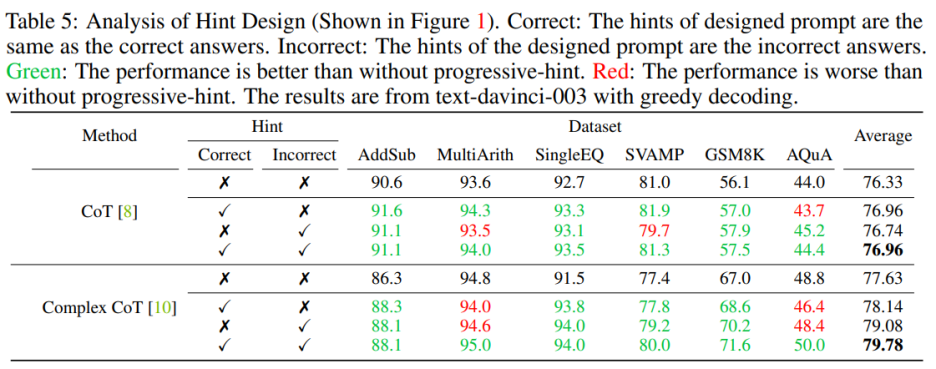
When designing prompts, you need to include both correct and incorrect prompts. When designing hints that contain both correct and incorrect hints, using PHP is better than not using PHP. Specifically, providing the correct hint in the prompt facilitates the generation of answers that are consistent with the given hint. Conversely, providing false hints in the prompt encourages the generation of alternative answers through the given prompt
PHP Self-Consistency
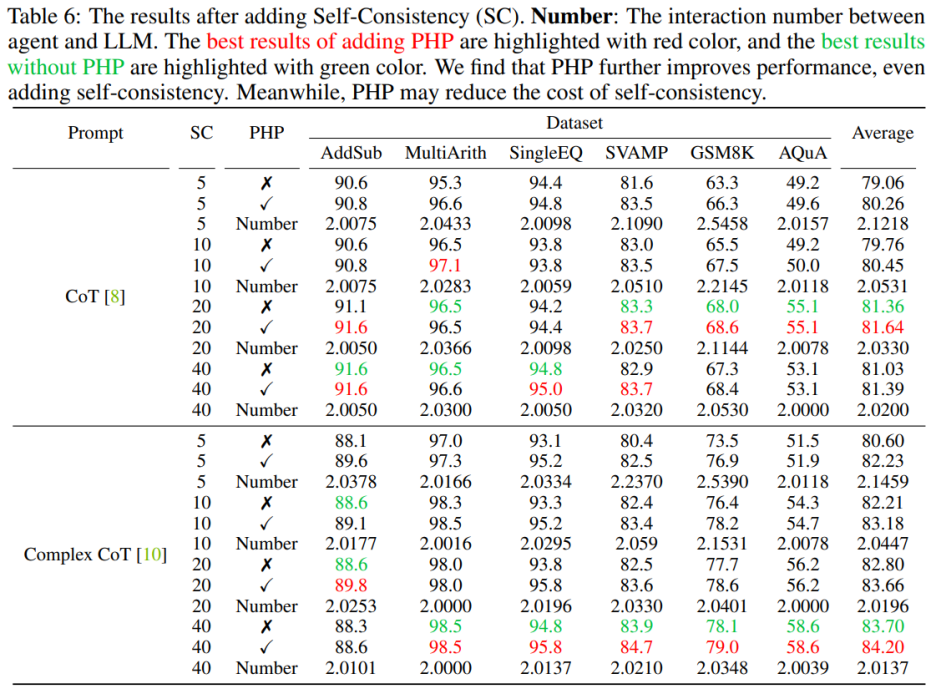
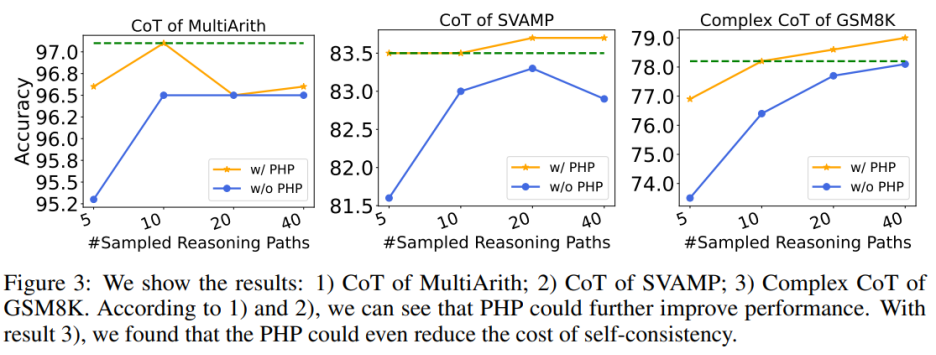
## Use PHP to further improve performance. By using similar number of hints and sample paths, the authors found that in Table 6 and Figure 3, the authors' proposed PHP-CoT and PHP-Complex CoT always performed better than CoT and Complex CoT. For example, CoT SC is able to achieve 96.5% accuracy on the MultiArith dataset with sample paths of 10, 20, and 40. Therefore, it can be concluded that the best performance of CoT SC is 96.5% using text-davinci-003. However, after implementing PHP, performance rose to 97.1%. Similarly, the authors also observed that on the SVAMP dataset, the best accuracy of CoT SC was 83.3%, which further improved to 83.7% after implementing PHP. This shows that PHP can break performance bottlenecks and further improve performance.
Using PHP can reduce the cost of SC. As we all know, SC involves more reasoning paths, resulting in higher costs. Table 6 illustrates that PHP can be an effective way to reduce costs while still maintaining performance gains. As shown in Figure 3, using SC Complex CoT, 40 sample paths can be used to achieve an accuracy of 78.1%, while adding PHP reduces the required average inference paths to 10×2.1531=21.531 paths, and the results are better and the accuracy is Reached 78.2%.
GPT-3.5-Turbo and GPT-4
The authors follow previous work settings and use text generation models conduct experiment. With the API release of GPT-3.5-Turbo and GPT-4, the authors verified the performance of Complex CoT with PHP on the same six datasets. The authors use greedy decoding (i.e. temperature = 0) and Complex CoT as hints for both models.
As shown in Table 7, the proposed PHP enhances the performance by 2.3% on GSM8K and 3.2% on AQuA. However, GPT-3.5-Turbo showed reduced ability to adhere to cues compared to text-davinci-003. The authors provide two examples to illustrate this point: a) In the case of missing hints, GPT-3.5-Turbo cannot answer the question and responds something like "I cannot answer this question because the answer hint is missing. Please provide an answer hint to Continue" statement. In contrast, text-davinci-003 autonomously generates and fills in missing answer hints before answering the question; b) when more than ten hints are provided, GPT-3.5-Turbo may reply "Due to multiple answers being given Hint, I am unable to determine the correct answer. Please provide an answer hint for the question."
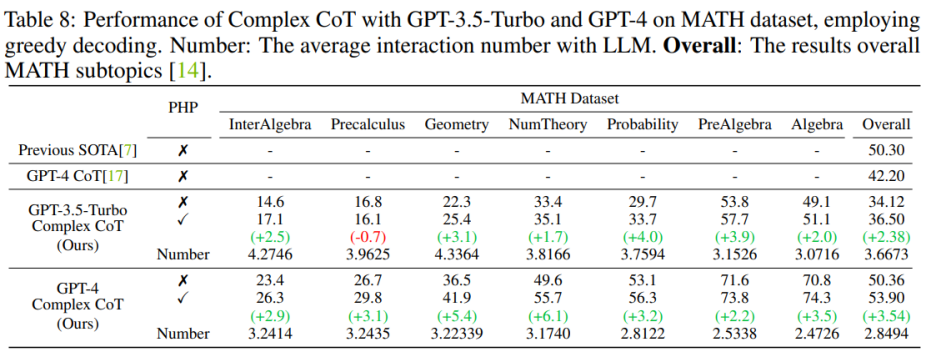
After deploying the GPT-4 model, the authors were able to achieve new SOTA performance on the SVAMP, GSM8K, AQuA, and MATH benchmarks. The PHP method proposed by the author continuously improves the performance of GPT-4. Additionally, the authors observed that GPT-4 required fewer interactions compared to the GPT-3.5-Turbo model, consistent with the finding that the number of interactions decreases when the model is more powerful.
Summary
This article introduces a new method for PHP to interact with LLMs, which has multiple advantages: 1) PHP achieves significant performance improvements on mathematical reasoning tasks , leading state-of-the-art results on multiple inference benchmarks; 2) PHP can better benefit LLMs using more powerful models and hints; 3) PHP can be easily combined with CoT and SC to further improve performance.
To better enhance the PHP method, future research can focus on improving the design of manual prompts in the question stage and prompt sentences in the answer part. Furthermore, in addition to treating answers as hints, new hints can be identified and extracted that help LLMs reconsider the problem.
The above is the detailed content of GPT-4 wins the new SOTA of the most difficult mathematical reasoning data set, and the new Prompting greatly improves the reasoning capabilities of large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 Sony confirms the possibility of using special GPUs on PS5 Pro to develop AI with AMD
Apr 13, 2025 pm 11:45 PM
Sony confirms the possibility of using special GPUs on PS5 Pro to develop AI with AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, chief architect of SonyInteractiveEntertainment (SIE, Sony Interactive Entertainment), has released more hardware details of next-generation host PlayStation5Pro (PS5Pro), including a performance upgraded AMDRDNA2.x architecture GPU, and a machine learning/artificial intelligence program code-named "Amethylst" with AMD. The focus of PS5Pro performance improvement is still on three pillars, including a more powerful GPU, advanced ray tracing and AI-powered PSSR super-resolution function. GPU adopts a customized AMDRDNA2 architecture, which Sony named RDNA2.x, and it has some RDNA3 architecture.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 What are the methods of tuning performance of Zookeeper on CentOS
Apr 14, 2025 pm 03:18 PM
What are the methods of tuning performance of Zookeeper on CentOS
Apr 14, 2025 pm 03:18 PM
Zookeeper performance tuning on CentOS can start from multiple aspects, including hardware configuration, operating system optimization, configuration parameter adjustment, monitoring and maintenance, etc. Here are some specific tuning methods: SSD is recommended for hardware configuration: Since Zookeeper's data is written to disk, it is highly recommended to use SSD to improve I/O performance. Enough memory: Allocate enough memory resources to Zookeeper to avoid frequent disk read and write. Multi-core CPU: Use multi-core CPU to ensure that Zookeeper can process it in parallel.
 Finally changed! Microsoft Windows search function will usher in a new update
Apr 13, 2025 pm 11:42 PM
Finally changed! Microsoft Windows search function will usher in a new update
Apr 13, 2025 pm 11:42 PM
Microsoft's improvements to Windows search functions have been tested on some Windows Insider channels in the EU. Previously, the integrated Windows search function was criticized by users and had poor experience. This update splits the search function into two parts: local search and Bing-based web search to improve user experience. The new version of the search interface performs local file search by default. If you need to search online, you need to click the "Microsoft BingWebSearch" tab to switch. After switching, the search bar will display "Microsoft BingWebSearch:", where users can enter keywords. This move effectively avoids the mixing of local search results with Bing search results
 How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
Efficient training of PyTorch models on CentOS systems requires steps, and this article will provide detailed guides. 1. Environment preparation: Python and dependency installation: CentOS system usually preinstalls Python, but the version may be older. It is recommended to use yum or dnf to install Python 3 and upgrade pip: sudoyumupdatepython3 (or sudodnfupdatepython3), pip3install--upgradepip. CUDA and cuDNN (GPU acceleration): If you use NVIDIAGPU, you need to install CUDATool
