
 Operation and Maintenance
Linux Operation and Maintenance
In what file is the source code of the linux kernel placed?
Operation and Maintenance
Linux Operation and Maintenance
In what file is the source code of the linux kernel placed?
In what file is the source code of the linux kernel placed?

The source code of the Linux kernel is stored in the directory /usr/src/linux. The composition of the kernel source code: 1. The arch directory, which contains the core code related to the hardware architecture supported by the core source code; 2. The include directory, which contains most of the core's include files; 3. The init directory, which contains the core startup Code; 4. mm directory, contains all memory management code; 5. drivers directory, contains all device drivers in the system; 6. Ipc directory, contains core inter-process communication code.
Where to put the Linux kernel source code
Linux kernel source code can be obtained from many ways. Normally, after the Linux system is installed, the directory /usr/src/linux contains the kernel source code.
For source code reading, if you want to go smoothly, it is best to have a certain understanding of the source code knowledge background in advance.
The Linux kernel source code is composed as follows (assumed relative to the linux directory):
arch
This subdirectory contains The core code related to the hardware architecture supported by this core source code. For example, for the X86 platform, it is i386.
include
This directory contains most of the core include files. There is also a subdirectory for each supported architecture.
init
This directory contains the core startup code.
mm
This directory contains all memory management code. The memory management code related to the specific hardware architecture is located in the arch/*/mm directory. For example, the one corresponding to X86 is arch/i386/mm/fault.c.
drivers
All device drivers in the system are located in this directory. Device drivers are further subdivided into categories, with corresponding subdirectories for each category. For example, the sound card driver corresponds to "drivers/sound".
Ipc
This directory contains the core inter-process communication code.
modules
This directory contains modules that have been built and can be dynamically loaded.
fs Linux
Supported file system codes. Different file systems have different corresponding subdirectories. For example, the ext2 file system corresponds to the ext2 subdirectory.
Kernel
Main core code. At the same time, the code related to the processor structure is placed in the arch/*/kernel directory.
Net
#The core network part code. Each subdirectory inside corresponds to an aspect of the network.
Lib
This directory contains the core library code. Library code related to the processor architecture is placed in the arch/*/lib/ directory.
Scripts
This directory contains script files used to configure the core.
Documentation
This directory contains some documents for reference.
Linux kernel source code analysis method
1 Clarity of the kernel source code
If you want to analyze Linux, do in-depth operations The nature of the system, reading the kernel source code is the most effective way. We all know that becoming a good programmer requires a lot of practice and code writing. Programming is important, but people who only program can easily limit themselves to their own knowledge areas. If we want to expand the breadth of our knowledge, we need to be exposed to more code written by others, especially code written by people who are more advanced than us. Through this approach, we can break out of the constraints of our own knowledge circle, enter the knowledge circle of others, and learn more about information that we generally cannot learn in the short term. The Linux kernel is carefully maintained by countless "masters" in the open source community, and these people can all be called top code masters. By reading the Linux kernel code, we not only learn kernel-related knowledge, but in my opinion, what is more valuable is learning and understanding their programming skills and understanding of computers.
I also came into contact with the analysis of Linux kernel source code through a project. I benefited a lot from the analysis of source code. In addition to acquiring relevant kernel knowledge, it also changed my past understanding of kernel code:
1. Analysis of kernel source code is not "out of reach". The difficulty of kernel source code analysis does not lie in the source code itself, but in how to use more appropriate methods and means to analyze the code. The hugeness of the kernel means that we cannot analyze it step by step starting from the main function as we do with ordinary demo programs. We need a way to intervene from the middle to "break through" the kernel source code one by one. This "request on demand" approach allows us to grasp the main line of the source code instead of getting too hung up on specific details.
2. The design of the core is beautiful. The special status of the kernel determines that the execution efficiency of the kernel must be high enough to respond to the real-time requirements of current computer applications. For this reason, the Linux kernel uses a hybrid programming of C language and assembly. But we all know that software execution efficiency and software maintainability run counter to each other in many cases. How to improve the maintainability of the kernel while ensuring the efficiency of the kernel depends on the "beautiful" design in the kernel.
3. Amazing programming skills. In the general field of application software design, the status of coding may not be overemphasized, because developers pay more attention to the good design of software, and coding is just a matter of implementation means-just like using an ax to chop wood, without too much thinking. But this is not true in the kernel. Good coding design not only improves maintainability, but also improves code performance.
Everyone’s understanding of the kernel will be different. As our understanding of the kernel continues to deepen, we will have more thoughts and experiences about its design and implementation. Therefore, this article hopes to guide more people who are wandering outside the door of the Linux kernel to enter the world of Linux and experience the magic and greatness of the kernel for themselves. And I am not an expert in kernel source code. I just hope to share my own experience and experience in analyzing source code and provide reference and help to those who need it. To put it "high-sounding", it can be regarded as for the computer industry. Especially in terms of the operating system kernel, contribute your own modest efforts. Without further ado (it’s already too long-winded, sorry~), let me share my own Linux kernel source code analysis method.
2 Is the kernel source code difficult?
Essentially speaking, analyzing Linux kernel code is no different from looking at other people’s code, because what is in front of you Generally it is not the code you wrote yourself. Let’s take a simple example first. A stranger randomly gives you a program and asks you to explain the functional design of the program after reading the source code. I think many people who feel that their programming skills are okay must think this is nothing, as long as they can If you patiently read his code from beginning to end, you will definitely find the answer, and it is indeed the case. So now let's change the hypothesis. If this person is Linus, and what he gives you is the code of a module of the Linux kernel, will you still feel so relaxed? Many people may hesitate. Why does the code given to you by a stranger (of course not if Linus knows you, haha~) give us such different feelings? I think there are the following reasons:
1. The Linux kernel code is somewhat mysterious to the "outside world", and it is so huge that it may feel impossible to start when it is suddenly placed in front of you. For example, it may come from a very small reason-the main function cannot be found. For a simple demo program, we can analyze the meaning of the code from beginning to end, but the method of analyzing the kernel code is completely ineffective, because no one can read the Linux code from beginning to end (because it is really not necessary, and when used, Just look at it).
2. Many people have also come into contact with the code of large-scale software, but most of them are application projects. The form and meaning of the code are related to the business logic they often come into contact with. The kernel code is different. Most of the information it processes is closely related to the bottom layer of the computer. For example, the lack of relevant knowledge about operating systems, compilers, assembly, architecture, etc. will also make reading kernel code difficult.
3. The method of analyzing the kernel code is not reasonable enough. Faced with a large amount of complex kernel code, if you don't start from a global perspective, it's easy to get bogged down in the details of the code. Although the kernel code is huge, it also has its design principles and architecture, otherwise maintaining it would be a nightmare for anyone! If we clarify the overall design idea of the code module and then analyze the implementation of the code, analyzing the source code may be an easy and happy thing.
This is my personal understanding of these issues. If you have not been exposed to large-scale software projects, analyzing Linux kernel code may be a good opportunity to accumulate experience in large-scale projects (indeed, Linux code is the largest project I have been exposed to so far!). If you don’t understand the underlying computer thoroughly enough, then we can choose to accumulate underlying knowledge by analyzing and learning at the same time. The progress of analyzing the code may be a little slow at first, but as knowledge continues to accumulate, our "business logic" of the Linux kernel will gradually become clearer. The last point is how to grasp the source code of analysis from a global perspective. This is also the experience I want to share with you.
3 Kernel source code analysis method
3.1 Data collection
From the perspective of people understanding new things, in exploring Before understanding the essence of things, there must be a process of understanding new things. This process allows us to have a preliminary concept of new things. For example, if we want to learn piano, we need to first understand that playing piano requires us to learn basic music theory, simplified notation, staff and other basic knowledge, and then learn piano playing techniques and fingerings, and finally we can actually start practicing piano.
The same is true for analyzing kernel code. First, we need to locate the content involved in the code to be analyzed. Is it the code for process synchronization and scheduling, the code for memory management, the code for device management, the code for system startup, etc. The huge size of the kernel determines that we cannot analyze all the kernel code at once, so we need to give ourselves a reasonable division of labor. As algorithm design tells us, to solve a big problem, we must first solve the sub-problems it involves.
After locating the code range to be analyzed, we can use all the resources at hand to understand the overall structure and general functions of this part of the code as comprehensively as possible.
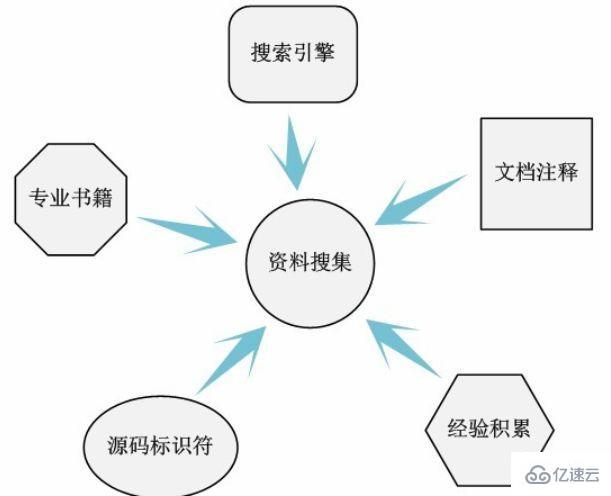
All the resources mentioned here refer to Baidu, Google large-scale online search engines, operating system principle textbooks and professional books , or the experience and information provided by others, or even the names of documents, comments and source code identifiers provided by the Linux source code (don't underestimate the naming of identifiers in the code, sometimes they can provide key information). In short, all the resources here refer to all the available resources you can think of. Of course, it is impossible for us to obtain all the information we want through this form of information collection. We just want to be as comprehensive as possible. Because the more comprehensive the information is collected, the more information can be used in the subsequent process of analyzing the code, and the less difficult the analysis process will be.
Here is a simple example, assuming that we want to analyze the code implemented by the Linux frequency conversion mechanism. So far we only know this term. From the literal meaning, we can roughly guess that it should be related to the frequency adjustment of the CPU. Through information collection, we should be able to obtain the following relevant information:
1. CPUFreq mechanism.
2. performance, powersave, userspace, ondemand, conservative frequency regulation strategies.
3. /driver/cpufreq/.
4. /documention/cpufreq.
5. P state and C state.
If you can collect this information when analyzing the Linux kernel code, you should be very "lucky". After all, the information about the Linux kernel is indeed not as rich as .NET and JQuery. However, compared with more than ten years ago, when there were no powerful search engines and no relevant research materials, it should be called the "Great Harvest" era! Through a simple "search" (it may take one or two days), we even found the source code file directory where this part of the code is located. I have to say that this kind of information is simply "priceless"!
3.2 Source code location
From the data collection, we were "lucky" to find the source code directory related to the source code. But this does not mean that we are indeed analyzing the source code in this directory. Sometimes the directories we find may be scattered, and sometimes the directories we find contain a lot of code related to specific machines, and we are more concerned about the main mechanism of the code to be analyzed rather than the specialized code related to the machine ( This will help us understand the nature of the kernel more). Therefore, we need to carefully select the information involving code files in the information. Of course, this step is unlikely to be completed at one time, and no one can guarantee that all source code files to be analyzed can be selected at one time and none of them will be missed. But we don’t have to worry. As long as we can capture the core source files related to most modules, we can naturally find them all through detailed analysis of the code later.
Back to the above example, we carefully read the documentation under /documention/cpufreq. The current Linux source code will save module-related documentation in the documentation folder of the source code directory. If the module to be analyzed does not have documentation, this will somewhat increase the difficulty of locating key source code files, but it will not cause us to find them. The source code we want to analyze. By reading the documentation, we can at least pay attention to the source file /driver/cpufreq/cpufreq.c. Through this documentation of the source files, combined with the previously collected frequency modulation strategies, we can easily pay attention to the five source files: cpufreq_performance.c, cpufreq_powersave.c, cpufreq_userspace.c, cpufreq_ondemand, and cpufreq_conservative.c. Have all the documents involved been found? Don't worry, start analyzing from them and sooner or later you will find other source files. If you use sourceinsight to read the kernel source code under Windows, we can easily find other files freq_table.c, cpufreq_stats.c and /include/linux/cpufreq through functions such as function calling and symbol reference searching, combined with code analysis. h.
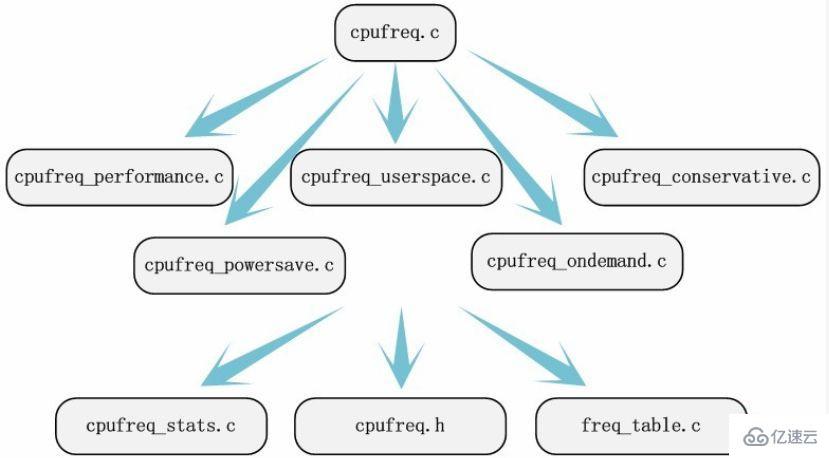
According to the searched information flow direction, we can completely locate the source code file that needs to be analyzed. The step of locating the source code is not very critical, because we do not need to find all the source code files, and we can defer part of the work to the process of analyzing the code. Source code positioning is also critical. Finding a part of the source code files is the basis for analyzing the source code.
3.3 Simple comments
Simple comments
In the located source code file, analyze each variable, macro, function, structure, etc. The approximate meaning and function of code elements. The reason why this is called a simple annotation does not mean that the annotation work in this part is very simple, but it means that the annotation in this part does not need to be too detailed, as long as it roughly describes the meaning of the relevant code elements. On the contrary, the work here is actually the most difficult step in the entire analysis process. Because this is the first time to go deep into the kernel code, especially for those who are analyzing the kernel source code for the first time, the large number of unfamiliar GNU C syntax and overwhelming macro definitions will be very disappointing. At this time, as long as you calm down and understand each key difficulty, you can ensure that you will not be trapped when encountering similar difficulties in the future. Moreover, our other knowledge related to the kernel will continue to expand like a tree.
For example, the use of the "DEFINE_PER_CPU" macro will appear at the beginning of the cpufreq.c file. We can basically understand the meaning and function of this macro by consulting the information. The method used here is basically the same as the method used to collect data before. In addition, we can also use the go to definition function provided by sourceinsight to view its definition, or use LKML (Linux Kernel Mail List) to view it. In short, using all possible means, we can always get the meaning of this macro - define an independently used variable for each CPU.
We don’t insist on accurately describing the comments in one go (we don’t even need to figure out the specific implementation process of each function, just figure out the general functional meaning), we combine the collected The analysis of data and subsequent code continuously improves the meaning of comments (the original comments and identifier naming in the source code are of great use here). Through constant annotation, constant reference to information, and constant modification of the meaning of annotations.
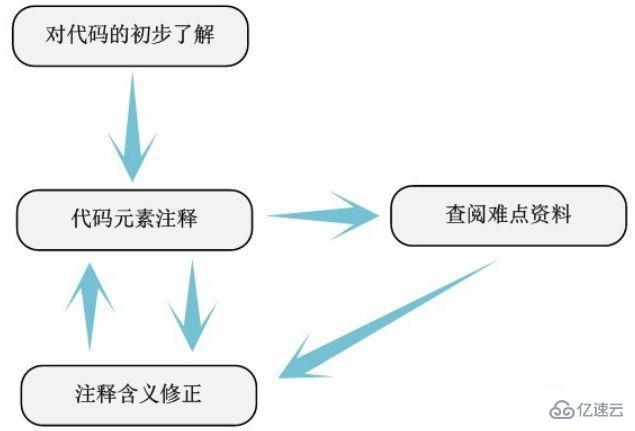
After we simply comment out all the source code files involved, we can achieve the following results:
1. Basically understand the meaning of the code elements in the source code.
2. Basically all the key source code files involved in this module were found.
Combined with the overall or architectural description of the code to be analyzed based on the previously collected information and data, we can compare the analysis results with the data to determine and revise our understanding of the code. In this way, through a simple comment, we can grasp the main structure of the source code module as a whole. This also achieves the basic purpose of our simple annotation.
3.4 Detailed comments
After completing the simple comments of the code, it can be considered that half of the analysis of the module is completed, and the remaining content is an in-depth analysis of the code and thorough understanding. Simple comments cannot always describe the specific meaning of code elements very accurately, so detailed comments are very necessary. In this step, we need to clarify the following:
1. When the variable definition is used.
2. When the code defined by the macro is used.
3. The meaning of function parameters and return values.
4. The execution flow and calling relationship of the function.
5. The specific meaning and usage conditions of the structure fields.
We can even call this step detailed function annotation, because the meaning of code elements outside the function is basically clear in simple comments. The execution flow and algorithm of the function itself are the main tasks of this part of annotation and analysis.
For example, how the implementation algorithm of cpufreq_ondemand policy (in function dbs_check_cpu) is implemented. We need to gradually analyze the variables used by the function and the functions called to understand the ins and outs of the algorithm. For the best results, we need the execution flow chart and function call diagram of these complex functions, which is the most intuitive way of expression.
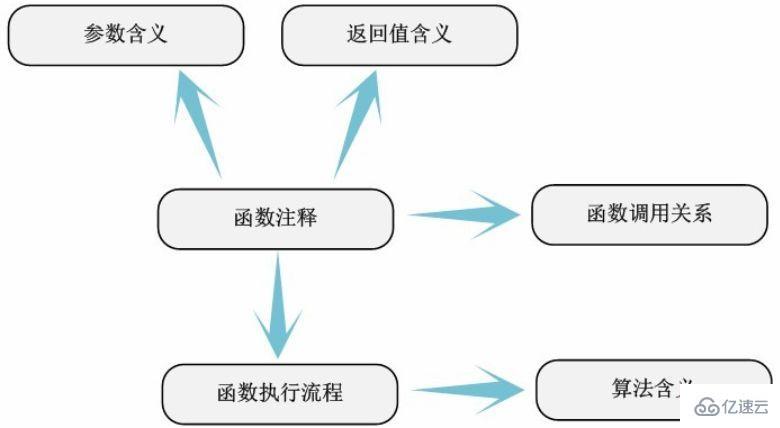
Through the comments in this step, we can basically fully grasp the overall implementation mechanism of the code to be analyzed. All analysis work can be considered 80% completed. This step is particularly critical. We must try to make the annotation information accurate enough to better understand the division of internal modules of the code to be analyzed. Although the Linux kernel uses the macro syntax "module_init" and "module_exit" to declare module files, the division of sub-functions within the module is based on a full understanding of the module's functions. Only by dividing the module correctly can we figure out what external functions and variables the module provides (using symbols exported by EXPORT_SYMBOL_GPL or EXPORT_SYMBOL). Only then can we proceed to the next step of analyzing the identifier dependencies within the module.
3.5 Module Internal Identifier Dependencies
Through the division of code modules in the fourth step, we can "easily" analyze the modules one by one. Generally, we can start from the module entry and exit functions at the bottom of the file (the functions declared by "module_init" and "module_exit" are usually at the end of the file), based on the functions they call (functions defined by ourselves or other modules) and the functions used Key variables (global variables in this file or external variables of other modules) draw a "function-variable-function" dependency diagram - we call it an identifier dependency diagram.
Of course, the identifier dependency relationship within the module is not a simple tree structure, but in many cases is an intricate network relationship. At this time, the role of our detailed comments on the code is reflected. We divide the module into sub-functions based on the meaning of the function itself, and extract the identifier dependency tree of each sub-function.
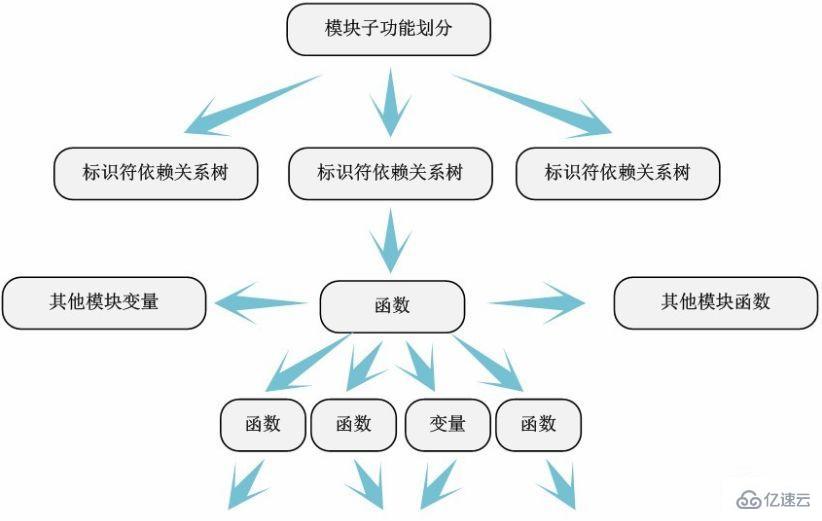
Through identifier dependency analysis, it can be clearly displayed which functions are called by the functions defined by the module and which variables are used. And the dependencies between module sub-functions - which functions and variables are shared, etc.
3.6 Interdependence between modules
Interdependence between modules
Once all module internal identifier dependency diagrams are sorted out, according to Dependencies between modules can be easily obtained by using variables or functions of other modules.
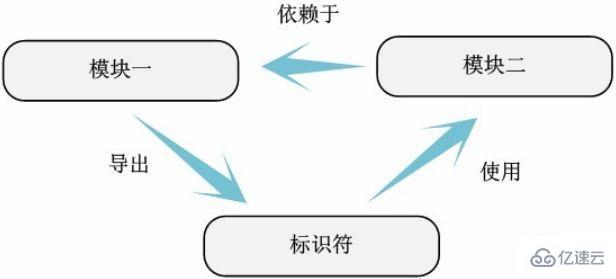
The module dependency relationship of cpufreq code can be expressed as the following relationship.
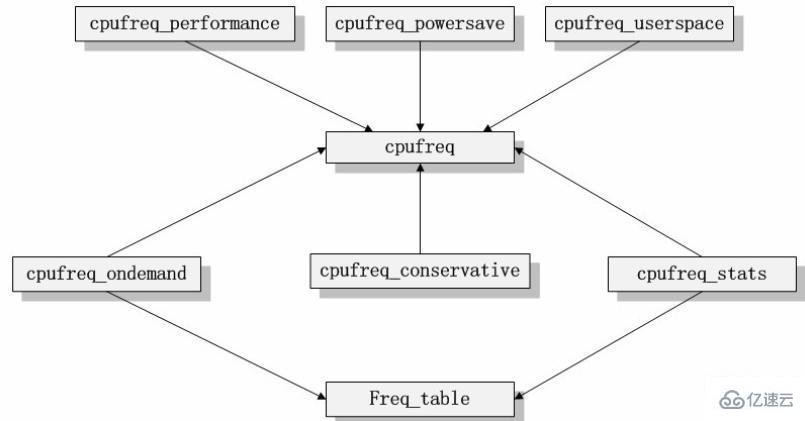
3.7 Module architecture diagram
Through the dependency diagram between modules, you can Clearly express the status and function of the module in the entire code to be analyzed. Based on this, we can classify the modules and sort out the architectural relationship of the code.
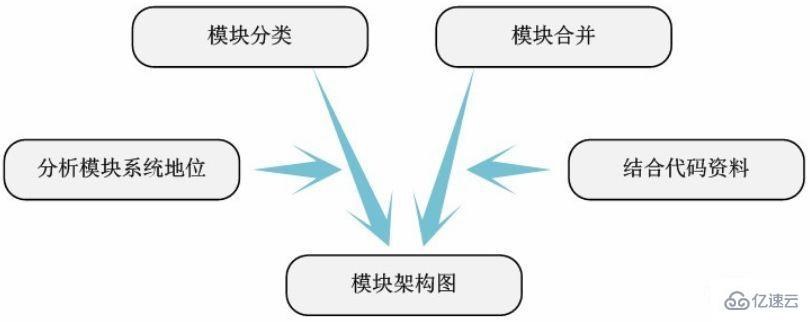
As shown in the module dependency diagram of cpufreq, we can clearly see that all frequency modulation strategy modules depend on The core modules cpufreq, cpufreq_stats and freq_table. If we abstract the three dependent modules into the core framework of the code, these frequency modulation strategy modules are built on this framework, and they are responsible for interacting with the user layer. The core module cpufreq provides drivers and other related interfaces that are responsible for interacting with the underlying system. Therefore, we can get the following module architecture diagram.
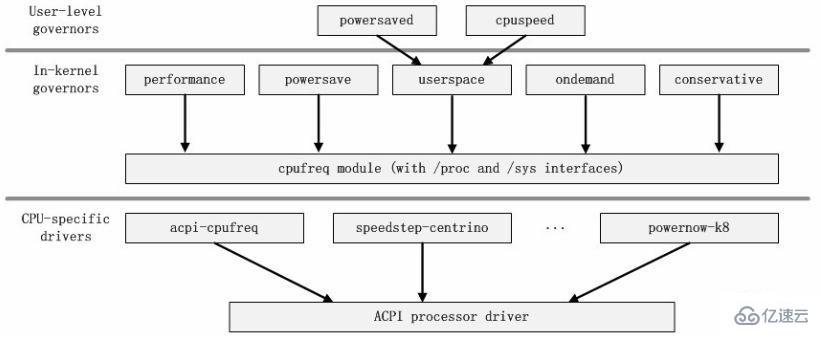
# Of course, the architecture diagram is not an inorganic splicing of modules. We also need to combine the information we consult to enrich the meaning of the architecture diagram. Therefore, the details of the architecture diagram here will vary according to different people's understanding. But the meaning of the main body of the architecture diagram is basically the same. At this point, we have completed all analysis of the kernel code to be analyzed.
The above is the detailed content of In what file is the source code of the linux kernel placed?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
Difference between centos and ubuntu
Apr 14, 2025 pm 09:09 PM
The key differences between CentOS and Ubuntu are: origin (CentOS originates from Red Hat, for enterprises; Ubuntu originates from Debian, for individuals), package management (CentOS uses yum, focusing on stability; Ubuntu uses apt, for high update frequency), support cycle (CentOS provides 10 years of support, Ubuntu provides 5 years of LTS support), community support (CentOS focuses on stability, Ubuntu provides a wide range of tutorials and documents), uses (CentOS is biased towards servers, Ubuntu is suitable for servers and desktops), other differences include installation simplicity (CentOS is thin)
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 Centos stops maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos stops maintenance 2024
Apr 14, 2025 pm 08:39 PM
CentOS will be shut down in 2024 because its upstream distribution, RHEL 8, has been shut down. This shutdown will affect the CentOS 8 system, preventing it from continuing to receive updates. Users should plan for migration, and recommended options include CentOS Stream, AlmaLinux, and Rocky Linux to keep the system safe and stable.
 How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use docker desktop
Apr 15, 2025 am 11:45 AM
How to use Docker Desktop? Docker Desktop is a tool for running Docker containers on local machines. The steps to use include: 1. Install Docker Desktop; 2. Start Docker Desktop; 3. Create Docker image (using Dockerfile); 4. Build Docker image (using docker build); 5. Run Docker container (using docker run).
 How to install centos
Apr 14, 2025 pm 09:03 PM
How to install centos
Apr 14, 2025 pm 09:03 PM
CentOS installation steps: Download the ISO image and burn bootable media; boot and select the installation source; select the language and keyboard layout; configure the network; partition the hard disk; set the system clock; create the root user; select the software package; start the installation; restart and boot from the hard disk after the installation is completed.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How to mount hard disk in centos
Apr 14, 2025 pm 08:15 PM
How to mount hard disk in centos
Apr 14, 2025 pm 08:15 PM
CentOS hard disk mount is divided into the following steps: determine the hard disk device name (/dev/sdX); create a mount point (it is recommended to use /mnt/newdisk); execute the mount command (mount /dev/sdX1 /mnt/newdisk); edit the /etc/fstab file to add a permanent mount configuration; use the umount command to uninstall the device to ensure that no process uses the device.
 What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
What to do after centos stops maintenance
Apr 14, 2025 pm 08:48 PM
After CentOS is stopped, users can take the following measures to deal with it: Select a compatible distribution: such as AlmaLinux, Rocky Linux, and CentOS Stream. Migrate to commercial distributions: such as Red Hat Enterprise Linux, Oracle Linux. Upgrade to CentOS 9 Stream: Rolling distribution, providing the latest technology. Select other Linux distributions: such as Ubuntu, Debian. Evaluate other options such as containers, virtual machines, or cloud platforms.
