

How to install Hadoop in linux

1: Install JDK
1. Execute the following command to download the JDK1.8 installation package.
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2. Execute the following command to decompress the downloaded JDK1.8 installation package.
tar -zxvf jdk-8u151-linux-x64.tar.gz
3. Move and rename the JDK package.
mv jdk1.8.0_151/ /usr/java8
4. Configure Java environment variables.
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile source /etc/profile
5. Check whether Java is successfully installed.
java -version
2: Install Hadoop
Note: To download the Hadoop installation package, you can choose Huawei source (the speed is medium, acceptable, the focus is on the full version), Tsinghua source (3.0.0 or above The version download speed is too slow and there are few versions), Beijing Foreign Studies University source (the download speed is very fast, but there are few versions) - I personally tested it
1. Execute the following command to download Hadoop installation Bag.
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2. Execute the following command to decompress the Hadoop installation package to /opt/hadoop.
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/ mv /opt/hadoop-3.1.3 /opt/hadoop
3. Execute the following command to configure Hadoop environment variables.
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile source /etc/profile
4. Execute the following command to modify the configuration files yarn-env.sh and hadoop-env.sh.
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
5. Execute the following command to test whether Hadoop is installed successfully.
hadoop version
If version information is returned, the installation is successful.
3: Configure Hadoop
1. Modify the Hadoop configuration file core-site.xml.
a. Execute the following command to enter the editing page.
vim /opt/hadoop/etc/hadoop/core-site.xml
b. Enter i to enter edit mode. c. Insert the following content into the <configuration></configuration> node.
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>d. Press the Esc key to exit the editing mode, enter: wq to save and exit.
2. Modify the Hadoop configuration file hdfs-site.xml.
a. Execute the following command to enter the editing page.
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
b. Enter i to enter edit mode. c. Insert the following content into the <configuration></configuration> node.
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>d. Press the Esc key to exit the editing mode, enter: wq to save and exit.
Four: Configure SSH password-free login
1. Execute the following command to create the public key and private key.
ssh-keygen -t rsa
2. Execute the following command to add the public key to the authorized_keys file.
cd ~ cd .ssh cat id_rsa.pub >> authorized_keys
If an error is reported, perform the following operations and then re-execute the above two commands; if no error is reported, go directly to step five:
Enter the following command in the environment variable Add the following configuration
vi /etc/profile
Then add the following content to it
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
Enter the following command to make the changes take effect
source /etc/profile
Five: Start Hadoop
1.Execute the following command to initialize the namenode.
hadoop namenode -format
2.Execute the following commands in sequence to start Hadoop.
start-dfs.sh
If Y/N is selected, select Y; otherwise press Enter directly
start-yarn.sh
3.After successful startup, execute the following command , to view the processes that have been successfully started.
jps
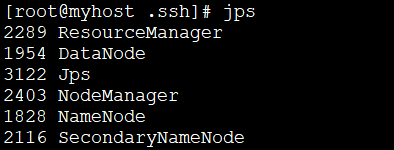
Normally there will be 6 processes;
4.Open the browser to visit http://:8088 and http://:50070. If the following interface is displayed, it means that the Hadoop pseudo-distributed environment is completed.
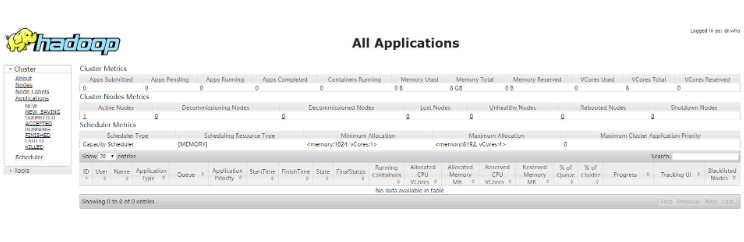
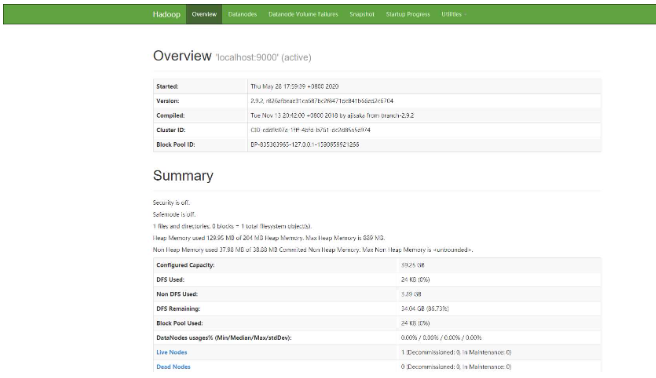
The above is the detailed content of How to install Hadoop in linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
The main reasons why you cannot log in to MySQL as root are permission problems, configuration file errors, password inconsistent, socket file problems, or firewall interception. The solution includes: check whether the bind-address parameter in the configuration file is configured correctly. Check whether the root user permissions have been modified or deleted and reset. Verify that the password is accurate, including case and special characters. Check socket file permission settings and paths. Check that the firewall blocks connections to the MySQL server.
 Solutions to the errors reported by MySQL on a specific system version
Apr 08, 2025 am 11:54 AM
Solutions to the errors reported by MySQL on a specific system version
Apr 08, 2025 am 11:54 AM
The solution to MySQL installation error is: 1. Carefully check the system environment to ensure that the MySQL dependency library requirements are met. Different operating systems and version requirements are different; 2. Carefully read the error message and take corresponding measures according to prompts (such as missing library files or insufficient permissions), such as installing dependencies or using sudo commands; 3. If necessary, try to install the source code and carefully check the compilation log, but this requires a certain amount of Linux knowledge and experience. The key to ultimately solving the problem is to carefully check the system environment and error information, and refer to the official documents.
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 Can mysql run on android
Apr 08, 2025 pm 05:03 PM
Can mysql run on android
Apr 08, 2025 pm 05:03 PM
MySQL cannot run directly on Android, but it can be implemented indirectly by using the following methods: using the lightweight database SQLite, which is built on the Android system, does not require a separate server, and has a small resource usage, which is very suitable for mobile device applications. Remotely connect to the MySQL server and connect to the MySQL database on the remote server through the network for data reading and writing, but there are disadvantages such as strong network dependencies, security issues and server costs.
 Unable to access mysql from terminal
Apr 08, 2025 pm 04:57 PM
Unable to access mysql from terminal
Apr 08, 2025 pm 04:57 PM
Unable to access MySQL from the terminal may be due to: MySQL service not running; connection command error; insufficient permissions; firewall blocks connection; MySQL configuration file error.
 What is the most use of Linux?
Apr 09, 2025 am 12:02 AM
What is the most use of Linux?
Apr 09, 2025 am 12:02 AM
Linux is widely used in servers, embedded systems and desktop environments. 1) In the server field, Linux has become an ideal choice for hosting websites, databases and applications due to its stability and security. 2) In embedded systems, Linux is popular for its high customization and efficiency. 3) In the desktop environment, Linux provides a variety of desktop environments to meet the needs of different users.
 Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Monitor MySQL and MariaDB Droplets with Prometheus MySQL Exporter
Apr 08, 2025 pm 02:42 PM
Effective monitoring of MySQL and MariaDB databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Prometheus MySQL Exporter is a powerful tool that provides detailed insights into database metrics that are critical for proactive management and troubleshooting.
 How to solve the problem of missing dependencies when installing MySQL
Apr 08, 2025 pm 12:00 PM
How to solve the problem of missing dependencies when installing MySQL
Apr 08, 2025 pm 12:00 PM
MySQL installation failure is usually caused by the lack of dependencies. Solution: 1. Use system package manager (such as Linux apt, yum or dnf, Windows VisualC Redistributable) to install the missing dependency libraries, such as sudoaptinstalllibmysqlclient-dev; 2. Carefully check the error information and solve complex dependencies one by one; 3. Ensure that the package manager source is configured correctly and can access the network; 4. For Windows, download and install the necessary runtime libraries. Developing the habit of reading official documents and making good use of search engines can effectively solve problems.
