

Common string encodings are:
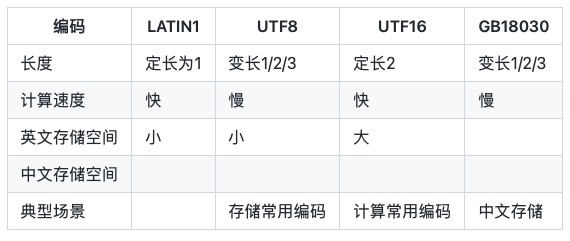
LATIN1 can only save ASCII characters, also known as ISO -8859-1.
UTF-8 is a variable-length byte encoding that uses 1, 2 or 3 bytes to represent a character. Since Chinese usually requires 3 bytes to represent, Chinese scene UTF-8 encoding usually requires more space, and the alternative is GBK/GB2312/GB18030.
UTF-16 2 bytes, one character needs to be represented by 2 bytes, also known as UCS-2 (2-byte Universal Character Set). According to the distinction between big and small ends, UTF-16 has two forms, UTF-16BE and UTF-16LE. The default UTF-16 refers to UTF-16BE. char in Java language is UTF-16LE encoding.
GB18030 adopts variable-length byte encoding, and each character is represented by 1, 2 or 3 bytes. Similar to UTF8, using 2 characters to represent Chinese can save bytes, but this method is not universal internationally.
#For the convenience of calculation, strings in memory usually use equal-width characters. Both char in Java language and char in .NET use UTF-16. Early Windows-NT only supported UTF-16.
Conversion between UTF-16 and UTF-8 is more complicated and usually has poor performance.
The following is an implementation of converting UTF-16 to UTF-8 encoding. It can be seen that the algorithm is more complex, so the performance is poor. This operation cannot use the vector API. Do optimization.
static int encodeUTF8(char[] utf16, int off, int len, byte[] dest, int dp) {
int sl = off + len, last_offset = sl - 1;
while (off < sl) {
char c = utf16[off++];
if (c < 0x80) {
// Have at most seven bits
dest[dp++] = (byte) c;
} else if (c < 0x800) {
// 2 dest, 11 bits
dest[dp++] = (byte) (0xc0 | (c >> 6));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
} else if (c >= '\uD800' && c < '\uE000') {
int uc;
if (c < '\uDC00') {
if (off > last_offset) {
dest[dp++] = (byte) '?';
return dp;
}
char d = utf16[off];
if (d >= '\uDC00' && d < '\uE000') {
uc = (c << 10) + d + 0xfca02400;
} else {
throw new RuntimeException("encodeUTF8 error", new MalformedInputException(1));
}
} else {
uc = c;
}
dest[dp++] = (byte) (0xf0 | ((uc >> 18)));
dest[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f));
dest[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (uc & 0x3f));
off++; // 2 utf16
} else {
// 3 dest, 16 bits
dest[dp++] = (byte) (0xe0 | ((c >> 12)));
dest[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f));
dest[dp++] = (byte) (0x80 | (c & 0x3f));
}
}
return dp;
}Since char in Java is UTF-16LE encoded, if you need to convert char[] to UTF-16LE encoded byte[], you can use the sun.misc.Unsafe#copyMemory method to quickly copy. For example:
static int writeUtf16LE(char[] chars, int off, int len, byte[] dest, final int dp) {
UNSAFE.copyMemory(chars
, CHAR_ARRAY_BASE_OFFSET + off * 2
, dest
, BYTE_ARRAY_BASE_OFFSET + dp
, len * 2
);
dp += len * 2;
return dp;
}Since different versions of JDK implement different string processing methods, different performance will occur. After JDK 9, String can also use LATIN1 encoding internally, although char still uses UTF-16 encoding.
static class String {
final char[] value;
final int offset;
final int count;
}Before Java 6, the String object generated by the String.subString method shares a char[] value with the original String object, which will cause the subString method to The char[] of the returned String is referenced and cannot be recycled by GC. Many libraries avoid using the subString method to prevent problems in JDK 6 and below.
static class String {
final char[] value;
}After JDK 7, the offset and count fields are removed from the string, and value.length is the original count. This avoids the problem of subString referencing large char[] and makes optimization easier. As a result, the String operation performance in JDK7/8 is greatly improved compared to Java 6.
static class String {
final byte code;
final byte[] value;
static final byte LATIN1 = 0;
static final byte UTF16 = 1;
}After JDK 9, the value type changes from char[] to byte[], and a field code is added. If all characters are ASCII Characters, use value to use LATIN encoding; if there is any non-ASCII character, use UTF16 encoding. This mixed encoding method makes English scenes occupy less memory. The disadvantage is that the performance of the String API of Java 9 may not be as good as that of JDK 8. In particular, when char[] is passed in to construct a string, it will be compressed into latin-encoded byte[], which may decrease by 10% in some scenarios.
In order to realize the immutability of strings, when constructing a string, there will be a copy process. If you want to increase the cost of constructing a string, It is necessary to avoid such copies.
For example, the following is the implementation of a constructor of String in JDK8
public final class String {
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
}In JDK8, there is a constructor that does not copy, but this method is not public and needs to be implemented with a trick MethodHandles.Lookup & LambdaMetafactory are bound to reflection to call. There is code introducing this technique later in the article.
public final class String {
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
}There are three ways to quickly construct characters:
Use MethodHandles.Lookup and LambdaMetafactory to bind reflection
Use Related methods of JavaLangAccess
Use Unsafe to construct directly
The performance of 1 and 2 is similar, 3 is slightly slower, but it is different from directly using the new character Compared to string, they are both faster. The data of JDK8 using JMH test is as follows: 936.754 ops/ms
StringCreateBenchmark.langAccess thrpt 5 784029.186 ± 2734.300 ops/msStringCreateBenchmark.unsafe thrpt 5 761176.319 ± 11914.549 ops/msStringCreateBenchmark.newString thrpt 5 140883.533 ± 2217.773 ops/ms
After JDK 9, for all For scenes with ASCII characters, direct construction can achieve better results.4.1 基于MethodHandles.Lookup & LambdaMetafactory绑定反射的快速构造字符串的方法
4.1.1 JDK8快速构造字符串
public static BiFunction<char[], Boolean, String> getStringCreatorJDK8() throws Throwable { Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class); constructor.setAccessible(true); MethodHandles lookup = constructor.newInstance( String.class , -1 // Lookup.TRUSTED ); MethodHandles.Lookup caller = lookup.in(String.class); MethodHandle handle = caller.findConstructor( String.class, MethodType.methodType(void.class, char[].class, boolean.class) ); CallSite callSite = LambdaMetafactory.metafactory( caller , "apply" , MethodType.methodType(BiFunction.class) , handle.type().generic() , handle , handle.type() ); return (BiFunction) callSite.getTarget().invokeExact(); }Copy after login4.1.2 JDK 11快速构造字符串的方法
public static ToIntFunction<String> getStringCode11() throws Throwable { Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class); constructor.setAccessible(true); MethodHandles.Lookup lookup = constructor.newInstance( String.class , -1 // Lookup.TRUSTED ); MethodHandles.Lookup caller = lookup.in(String.class); MethodHandle handle = caller.findVirtual( String.class, "coder", MethodType.methodType(byte.class) ); CallSite callSite = LambdaMetafactory.metafactory( caller , "applyAsInt" , MethodType.methodType(ToIntFunction.class) , MethodType.methodType(int.class, Object.class) , handle , handle.type() ); return (ToIntFunction<String>) callSite.getTarget().invokeExact(); }Copy after loginif (JDKUtils.JVM_VERSION == 11) { Function<byte[], String> stringCreator = JDKUtils.getStringCreatorJDK11(); byte[] bytes = new byte[]{'a', 'b', 'c'}; String apply = stringCreator.apply(bytes); assertEquals("abc", apply); }Copy after login4.1.3 JDK 17快速构造字符串的方法
在JDK 17中,MethodHandles.Lookup使用Reflection.registerFieldsToFilter对lookupClass和allowedModes做了保护,网上搜索到的通过修改allowedModes的办法是不可用的。
在JDK 17中,要通过配置JVM启动参数才能使用MethodHandlers。如下:
--add-opens java.base/java.lang.invoke=ALL-UNNAMEDCopy after loginpublic static BiFunction<byte[], Charset, String> getStringCreatorJDK17() throws Throwable { Constructor<MethodHandles.Lookup> constructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, Class.class, int.class); constructor.setAccessible(true); MethodHandles.Lookup lookup = constructor.newInstance( String.class , null , -1 // Lookup.TRUSTED ); MethodHandles.Lookup caller = lookup.in(String.class); MethodHandle handle = caller.findStatic( String.class, "newStringNoRepl1", MethodType.methodType(String.class, byte[].class, Charset.class) ); CallSite callSite = LambdaMetafactory.metafactory( caller , "apply" , MethodType.methodType(BiFunction.class) , handle.type().generic() , handle , handle.type() ); return (BiFunction<byte[], Charset, String>) callSite.getTarget().invokeExact(); }Copy after loginif (JDKUtils.JVM_VERSION == 17) { BiFunction<byte[], Charset, String> stringCreator = JDKUtils.getStringCreatorJDK17(); byte[] bytes = new byte[]{'a', 'b', 'c'}; String apply = stringCreator.apply(bytes, StandardCharsets.US_ASCII); assertEquals("abc", apply); }Copy after login4.2 基于JavaLangAccess快速构造
通过SharedSecrets提供的JavaLangAccess,也可以不拷贝构造字符串,但是这个比较麻烦,JDK 8/11/17的API都不一样,对一套代码兼容不同的JDK版本不方便,不建议使用。
JavaLangAccess javaLangAccess = SharedSecrets.getJavaLangAccess(); javaLangAccess.newStringNoRepl(b, StandardCharsets.US_ASCII);Copy after login4.3 基于Unsafe实现快速构造字符串
public static final Unsafe UNSAFE; static { Unsafe unsafe = null; try { Field theUnsafeField = Unsafe.class.getDeclaredField("theUnsafe"); theUnsafeField.setAccessible(true); unsafe = (Unsafe) theUnsafeField.get(null); } catch (Throwable ignored) {} UNSAFE = unsafe; } //////////////////////////////////////////// Object str = UNSAFE.allocateInstance(String.class); UNSAFE.putObject(str, valueOffset, chars);Copy after login注意:在JDK 9之后,实现是不同,比如:
Object str = UNSAFE.allocateInstance(String.class); UNSAFE.putByte(str, coderOffset, (byte) 0); UNSAFE.putObject(str, valueOffset, (byte[]) bytes);Copy after login4.4 快速构建字符串的技巧应用:
如下的方法格式化日期为字符串,性能就会非常好。
public String formatYYYYMMDD(Calendar calendar) throws Throwable { int year = calendar.get(Calendar.YEAR); int month = calendar.get(Calendar.MONTH) + 1; int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH); byte y0 = (byte) (year / 1000 + '0'); byte y1 = (byte) ((year / 100) % 10 + '0'); byte y2 = (byte) ((year / 10) % 10 + '0'); byte y3 = (byte) (year % 10 + '0'); byte m0 = (byte) (month / 10 + '0'); byte m1 = (byte) (month % 10 + '0'); byte d0 = (byte) (dayOfMonth / 10 + '0'); byte d1 = (byte) (dayOfMonth % 10 + '0'); if (JDKUtils.JVM_VERSION >= 9) { byte[] bytes = new byte[] {y0, y1, y2, y3, m0, m1, d0, d1}; if (JDKUtils.JVM_VERSION == 17) { return JDKUtils.getStringCreatorJDK17().apply(bytes, StandardCharsets.US_ASCII); } if (JDKUtils.JVM_VERSION <= 11) { return JDKUtils.getStringCreatorJDK11().apply(bytes); } return new String(bytes, StandardCharsets.US_ASCII); } char[] chars = new char[]{ (char) y0, (char) y1, (char) y2, (char) y3, (char) m0, (char) m1, (char) d0, (char) d1 }; if (JDKUtils.JVM_VERSION == 8) { return JDKUtils.getStringCreatorJDK8().apply(chars, true); } return new String(chars); }Copy after login5.快速遍历字符串的办法
无论JDK什么版本,String.charAt都是一个较大的开销,JIT的优化效果并不好,无法消除参数index范围检测的开销,不如直接操作String里面的value数组。
public final class String { private final char value[]; public char charAt(int index) { if ((index < 0) || (index >= value.length)) { throw new StringIndexOutOfBoundsException(index); } return value[index]; } }Copy after login在JDK 9之后的版本,charAt开销更大
public final class String { private final byte[] value; private final byte coder; public char charAt(int index) { if (isLatin1()) { return StringLatin1.charAt(value, index); } else { return StringUTF16.charAt(value, index); } } }Copy after login5.1 获取String.value的方法
获取String.value的方法有如下:
使用Field反射
使用Unsafe
Unsafe和Field反射在JDK 8 JMH的比较数据如下:
Benchmark Mode Cnt Score Error Units
StringGetValueBenchmark.reflect thrpt 5 438374.685 ± 1032.028 ops/ms
StringGetValueBenchmark.unsafe thrpt 5 1302654.150 ± 59169.706 ops/ms5.1.1 使用反射获取String.value
static Field valueField; static { try { valueField = String.class.getDeclaredField("value"); valueField.setAccessible(true); } catch (NoSuchFieldException ignored) {} } //////////////////////////////////////////// char[] chars = (char[]) valueField.get(str);Copy after login5.1.2 使用Unsafe获取String.value
static long valueFieldOffset; static { try { Field valueField = String.class.getDeclaredField("value"); valueFieldOffset = UNSAFE.objectFieldOffset(valueField); } catch (NoSuchFieldException ignored) {} } //////////////////////////////////////////// char[] chars = (char[]) UNSAFE.getObject(str, valueFieldOffset);Copy after loginstatic long valueFieldOffset; static long coderFieldOffset; static { try { Field valueField = String.class.getDeclaredField("value"); valueFieldOffset = UNSAFE.objectFieldOffset(valueField); Field coderField = String.class.getDeclaredField("coder"); coderFieldOffset = UNSAFE.objectFieldOffset(coderField); } catch (NoSuchFieldException ignored) {} } //////////////////////////////////////////// byte coder = UNSAFE.getObject(str, coderFieldOffset); byte[] bytes = (byte[]) UNSAFE.getObject(str, valueFieldOffset);Copy after login6.更快的encodeUTF8方法
当能直接获取到String.value时,就可以直接对其做encodeUTF8操作,会比String.getBytes(StandardCharsets.UTF_8)性能好很多。
6.1 JDK8高性能encodeUTF8的方法
public static int encodeUTF8(char[] src, int offset, int len, byte[] dst, int dp) { int sl = offset + len; int dlASCII = dp + Math.min(len, dst.length); // ASCII only optimized loop while (dp < dlASCII && src[offset] < '\u0080') { dst[dp++] = (byte) src[offset++]; } while (offset < sl) { char c = src[offset++]; if (c < 0x80) { // Have at most seven bits dst[dp++] = (byte) c; } else if (c < 0x800) { // 2 bytes, 11 bits dst[dp++] = (byte) (0xc0 | (c >> 6)); dst[dp++] = (byte) (0x80 | (c & 0x3f)); } else if (c >= '\uD800' && c < ('\uDFFF' + 1)) { //Character.isSurrogate(c) but 1.7 final int uc; int ip = offset - 1; if (c >= '\uD800' && c < ('\uDBFF' + 1)) { // Character.isHighSurrogate(c) if (sl - ip < 2) { uc = -1; } else { char d = src[ip + 1]; // d >= '\uDC00' && d < ('\uDFFF' + 1) if (d >= '\uDC00' && d < ('\uDFFF' + 1)) { // Character.isLowSurrogate(d) uc = ((c << 10) + d) + (0x010000 - ('\uD800' << 10) - '\uDC00'); // Character.toCodePoint(c, d) } else { dst[dp++] = (byte) '?'; continue; } } } else { // if (c >= '\uDC00' && c < ('\uDFFF' + 1)) { // Character.isLowSurrogate(c) dst[dp++] = (byte) '?'; continue; } else { uc = c; } } if (uc < 0) { dst[dp++] = (byte) '?'; } else { dst[dp++] = (byte) (0xf0 | ((uc >> 18))); dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f)); dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f)); dst[dp++] = (byte) (0x80 | (uc & 0x3f)); offset++; // 2 chars } } else { // 3 bytes, 16 bits dst[dp++] = (byte) (0xe0 | ((c >> 12))); dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f)); dst[dp++] = (byte) (0x80 | (c & 0x3f)); } } return dp; }Copy after login使用encodeUTF8方法举例
char[] chars = UNSAFE.getObject(str, valueFieldOffset); // ensureCapacity(chars.length * 3) byte[] bytes = ...; // int bytesLength = IOUtils.encodeUTF8(chars, 0, chars.length, bytes, bytesOffset);Copy after login这样encodeUTF8操作,不会有多余的arrayCopy操作,性能会得到提升。
6.1.1 性能测试比较
测试代码
public class EncodeUTF8Benchmark { static String STR = "01234567890ABCDEFGHIJKLMNOPQRSTUVWZYZabcdefghijklmnopqrstuvwzyz一二三四五六七八九十"; static byte[] out; static long valueFieldOffset; static { out = new byte[STR.length() * 3]; try { Field valueField = String.class.getDeclaredField("value"); valueFieldOffset = UnsafeUtils.UNSAFE.objectFieldOffset(valueField); } catch (NoSuchFieldException e) { e.printStackTrace(); } } @Benchmark public void unsafeEncodeUTF8() throws Exception { char[] chars = (char[]) UnsafeUtils.UNSAFE.getObject(STR, valueFieldOffset); int len = IOUtils.encodeUTF8(chars, 0, chars.length, out, 0); } @Benchmark public void getBytesUTF8() throws Exception { byte[] bytes = STR.getBytes(StandardCharsets.UTF_8); System.arraycopy(bytes, 0, out, 0, bytes.length); } public static void main(String[] args) throws RunnerException { Options options = new OptionsBuilder() .include(EncodeUTF8Benchmark.class.getName()) .mode(Mode.Throughput) .timeUnit(TimeUnit.MILLISECONDS) .forks(1) .build(); new Runner(options).run(); } }Copy after login测试结果
EncodeUTF8Benchmark.getBytesUTF8 thrpt 5 20690.960 ± 5431.442 ops/ms
EncodeUTF8Benchmark.unsafeEncodeUTF8 thrpt 5 34508.606 ± 55.510 ops/ms从结果来看,通过unsafe + 直接调用encodeUTF8方法, 编码的所需要开销是newStringUTF8的58%。
6.2 JDK9/11/17高性能encodeUTF8的方法
public static int encodeUTF8(byte[] src, int offset, int len, byte[] dst, int dp) { int sl = offset + len; while (offset < sl) { byte b0 = src[offset++]; byte b1 = src[offset++]; if (b1 == 0 && b0 >= 0) { dst[dp++] = b0; } else { char c = (char)(((b0 & 0xff) << 0) | ((b1 & 0xff) << 8)); if (c < 0x800) { // 2 bytes, 11 bits dst[dp++] = (byte) (0xc0 | (c >> 6)); dst[dp++] = (byte) (0x80 | (c & 0x3f)); } else if (c >= '\uD800' && c < ('\uDFFF' + 1)) { //Character.isSurrogate(c) but 1.7 final int uc; int ip = offset - 1; if (c >= '\uD800' && c < ('\uDBFF' + 1)) { // Character.isHighSurrogate(c) if (sl - ip < 2) { uc = -1; } else { b0 = src[ip + 1]; b1 = src[ip + 2]; char d = (char) (((b0 & 0xff) << 0) | ((b1 & 0xff) << 8)); // d >= '\uDC00' && d < ('\uDFFF' + 1) if (d >= '\uDC00' && d < ('\uDFFF' + 1)) { // Character.isLowSurrogate(d) uc = ((c << 10) + d) + (0x010000 - ('\uD800' << 10) - '\uDC00'); // Character.toCodePoint(c, d) } else { return -1; } } } else { // if (c >= '\uDC00' && c < ('\uDFFF' + 1)) { // Character.isLowSurrogate(c) return -1; } else { uc = c; } } if (uc < 0) { dst[dp++] = (byte) '?'; } else { dst[dp++] = (byte) (0xf0 | ((uc >> 18))); dst[dp++] = (byte) (0x80 | ((uc >> 12) & 0x3f)); dst[dp++] = (byte) (0x80 | ((uc >> 6) & 0x3f)); dst[dp++] = (byte) (0x80 | (uc & 0x3f)); offset++; // 2 chars } } else { // 3 bytes, 16 bits dst[dp++] = (byte) (0xe0 | ((c >> 12))); dst[dp++] = (byte) (0x80 | ((c >> 6) & 0x3f)); dst[dp++] = (byte) (0x80 | (c & 0x3f)); } } } return dp; }Copy after login使用encodeUTF8方法举例
byte coder = UNSAFE.getObject(str, coderFieldOffset); byte[] value = UNSAFE.getObject(str, coderFieldOffset); if (coder == 0) { // ascii arraycopy } else { // ensureCapacity(chars.length * 3) byte[] bytes = ...; // int bytesLength = IOUtils.encodeUTF8(value, 0, value.length, bytes, bytesOffset); }Copy after login这样encodeUTF8操作,不会有多余的arrayCopy操作,性能会得到提升。
The above is the detailed content of How to improve Java string encoding and decoding performance. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



