
 Technology peripherals
AI
Generating videos is so easy, just give a hint, and you can also try it online
Technology peripherals
AI
Generating videos is so easy, just give a hint, and you can also try it online
Generating videos is so easy, just give a hint, and you can also try it online

You enter text and let AI generate a video. This idea only appeared in people's imagination before. Now, with the development of technology, this function has been realized.
In recent years, generative artificial intelligence has attracted huge attention in the field of computer vision. With the advent of diffusion models, generating high-quality images from text prompts, i.e., text-to-image synthesis, has become very popular and successful.
Recent research has attempted to successfully extend the text-to-image diffusion model to the task of text-to-video generation and editing by reusing it in the video domain. Although such methods have achieved promising results, most of them require extensive training using large amounts of labeled data, which may be too expensive for many users.
In order to make video generation cheaper, Tune-A-Video proposed by Jay Zhangjie Wu et al. last year introduced a mechanism to apply the Stable Diffusion (SD) model to the video field . Only one video needs to be adjusted, greatly reducing training workload. Although this is much more efficient than previous methods, it still requires optimization. Furthermore, Tune-A-Video's generation capabilities are limited to text-guided video editing applications, and compositing videos from scratch remains beyond its capabilities.
In this article, researchers from Picsart AI Resarch (PAIR), the University of Texas at Austin and other institutions have used zero-shot and no training to achieve a new method of text-to-video synthesis. A step forward in the problem direction of generating videos based on text prompts without any optimization or fine-tuning.

- ##Paper address: https://arxiv.org/ pdf/2303.13439.pdf
- Project address: https://github.com/Picsart-AI-Research/Text2Video-Zero
- Trial address: https://huggingface.co/spaces/PAIR/Text2Video-Zero
Let’s see how it works. For example, a panda is surfing; a bear is dancing in Times Square:

This research can also generate actions based on the target :

In addition, edge detection can also be performed:

A key concept of the approach proposed in this paper is to modify a pre-trained text-to-image model (such as Stable Diffusion) to enrich it with time-consistent generation. By building on already trained text-to-image models, our approach leverages their excellent image generation quality, enhancing their applicability to the video domain without requiring additional training.
In order to enhance temporal consistency, this paper proposes two innovative modifications: (1) first enrich the latent encoding of the generated frame with motion information to keep the global scene and background temporally consistent; (2) ) then uses a cross-frame attention mechanism to preserve the context, appearance, and identity of foreground objects throughout the sequence. Experiments show that these simple modifications can produce high-quality and temporally consistent videos (shown in Figure 1).

Although other people’s work trained on large-scale video data, our method achieves similar and sometimes better performance (shown in Figures 8 and 9).

#The method in this article is not limited to text-to-video synthesis, but is also suitable for conditional (see Figures 6 and 5) and specialized video generation (see Figure 7), as well as instruction-guided video editing, which can be called It is Video Instruct-Pix2Pix driven by Instruct-Pix2Pix (see Figure 9).


#In this paper, this paper uses the text-to-image synthesis capability of Stable Diffusion (SD) to handle the text-to-video task in zero-shot situations. For the needs of video generation rather than image generation, SD should focus on the operation of underlying code sequences. The naive approach is to independently sample m potential codes from a standard Gaussian distribution, i.e.
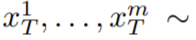 N (0, I) , and apply DDIM Sample to get the corresponding tensor
N (0, I) , and apply DDIM Sample to get the corresponding tensor
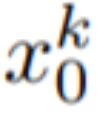
, where k = 1,…,m, then decode to Get the generated video sequence
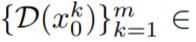
. However, as shown in the first row of Figure 10, this results in completely random image generation, sharing only the semantics described by 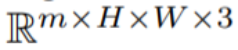
without consistency in object appearance or motion. 

# Introduce motion dynamics between ## to maintain the temporal consistency of the global scene; (ii) Use a cross-frame attention mechanism to preserve the appearance and identity of foreground objects. Each component of the method used in this paper is described in detail below, and an overview of the method can be found in Figure 2 .
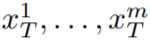
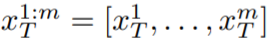
## All applications of Text2Video-Zero show that it successfully generates videos with temporal consistency of global scene and background, foreground The context, appearance, and identity of the object are maintained throughout the sequence.
In the case of text-to-video, it can be observed that it produces high-quality videos that are well aligned with the text prompts (see Figure 3). For example, a panda is drawn to walk naturally on the street. Likewise, using additional edge or pose guidance (see Figure 5, Figure 6, and Figure 7), high-quality videos matching prompts and guidance were generated, showing good temporal consistency and identity preservation.

In the case of Video Instruct-Pix2Pix (see Figure 1), the generated video High fidelity relative to the input video while strictly following instructions.
Comparison with Baseline
This paper compares its method with two publicly available baselines: CogVideo and Tune -A-Video. Since CogVideo is a text-to-video method, this article compares it with it in a plain text-guided video synthesis scenario; using Video Instruct-Pix2Pix for comparison with Tune-A-Video.
For quantitative comparison, this article uses the CLIP score to evaluate the model. The CLIP score represents the degree of video text alignment. By randomly obtaining 25 videos generated by CogVideo, and synthesizing the corresponding videos using the same tips according to the method in this article. The CLIP scores of our method and CogVideo are 31.19 and 29.63 respectively. Therefore, our method is slightly better than CogVideo, although the latter has 9.4 billion parameters and requires large-scale training on videos.
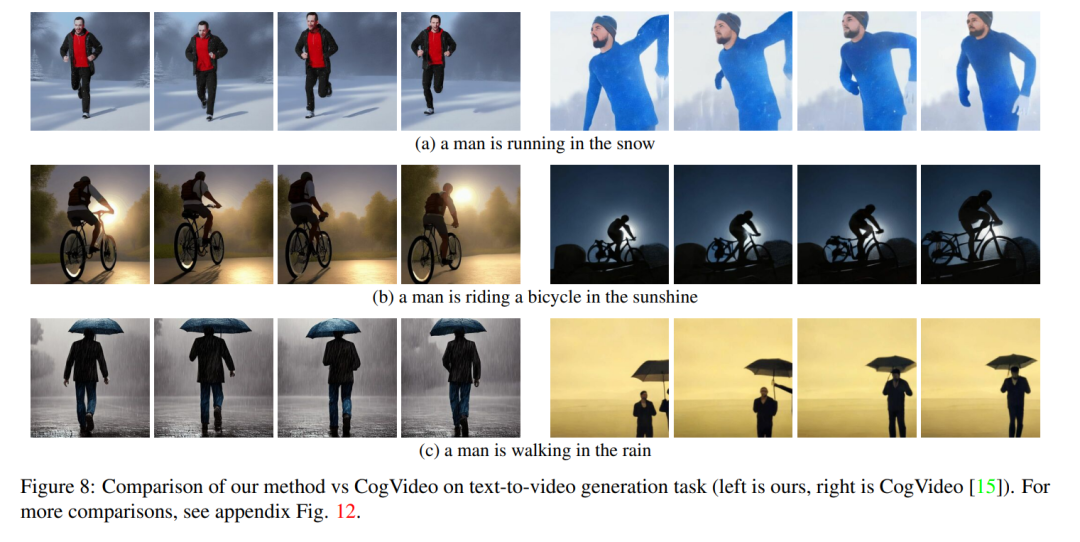
Figure 8 shows several results of the method proposed in this paper and provides a qualitative comparison with CogVideo. Both methods show good temporal consistency throughout the sequence, preserving the identity of the object as well as its context. Our method shows better text-video alignment capabilities. For example, our method correctly generates a video of a person riding a bicycle in the sun in Figure 8 (b), while CogVideo sets the background to moonlight. Also in Figure 8 (a), our method correctly shows a person running in the snow, while the snow and the running person are not clearly visible in the video generated by CogVideo.
Video Qualitative results for Instruct-Pix2Pix and visual comparison with per-frame Instruct-Pix2Pix and Tune-AVideo are shown in Figure 9. While Instruct-Pix2Pix shows good editing performance per frame, it lacks temporal consistency. This is especially noticeable in videos depicting skiers, where the snow and sky are drawn using different styles and colors. These issues were solved using the Video Instruct-Pix2Pix method, resulting in temporally consistent video editing throughout the sequence.
Although Tune-A-Video creates time-consistent video generation, compared with this article's method, it is less consistent with instruction guidance, difficult to create local edits, and Details of the input sequence are lost. This becomes apparent when looking at the edit of the dancer's video depicted in Figure 9 , left. Compared to Tune-A-Video, our method paints the entire outfit brighter while better preserving the background, such as the wall behind the dancer remaining almost unchanged. Tune-A-Video paints a heavily deformed wall. In addition, our method is more faithful to the input details. For example, compared to Tune-A-Video, Video Instruction-Pix2Pix draws dancers using the provided poses (Figure 9 left) and displays all skiers appearing in the input video. (As shown in the last frame on the right side of Figure 9). All the above mentioned weaknesses of Tune-A-Video can also be observed in Figures 23, 24.


The above is the detailed content of Generating videos is so easy, just give a hint, and you can also try it online. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1242
24
14
1423
52
1317
25
1268
29
1242
24

 Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
Is it infringing to post other people's videos on Douyin? How does it edit videos without infringement?
Mar 21, 2024 pm 05:57 PM
With the rise of short video platforms, Douyin has become an indispensable part of everyone's daily life. On TikTok, we can see interesting videos from all over the world. Some people like to post other people’s videos, which raises a question: Is Douyin infringing upon posting other people’s videos? This article will discuss this issue and tell you how to edit videos without infringement and how to avoid infringement issues. 1. Is it infringing upon Douyin’s posting of other people’s videos? According to the provisions of my country's Copyright Law, unauthorized use of the copyright owner's works without the permission of the copyright owner is an infringement. Therefore, posting other people’s videos on Douyin without the permission of the original author or copyright owner is an infringement. 2. How to edit a video without infringement? 1. Use of public domain or licensed content: Public
 How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
How to publish Xiaohongshu video works? What should I pay attention to when posting videos?
Mar 23, 2024 pm 08:50 PM
With the rise of short video platforms, Xiaohongshu has become a platform for many people to share their lives, express themselves, and gain traffic. On this platform, publishing video works is a very popular way of interaction. So, how to publish Xiaohongshu video works? 1. How to publish Xiaohongshu video works? First, make sure you have a video content ready to share. You can use your mobile phone or other camera equipment to shoot, but you need to pay attention to the image quality and sound clarity. 2. Edit the video: In order to make the work more attractive, you can edit the video. You can use professional video editing software, such as Douyin, Kuaishou, etc., to add filters, music, subtitles and other elements. 3. Choose a cover: The cover is the key to attracting users to click. Choose a clear and interesting picture as the cover to attract users to click on it.
 How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
How to make money from posting videos on Douyin? How can a newbie make money on Douyin?
Mar 21, 2024 pm 08:17 PM
Douyin, the national short video platform, not only allows us to enjoy a variety of interesting and novel short videos in our free time, but also gives us a stage to show ourselves and realize our values. So, how to make money by posting videos on Douyin? This article will answer this question in detail and help you make more money on TikTok. 1. How to make money from posting videos on Douyin? After posting a video and gaining a certain amount of views on Douyin, you will have the opportunity to participate in the advertising sharing plan. This income method is one of the most familiar to Douyin users and is also the main source of income for many creators. Douyin decides whether to provide advertising sharing opportunities based on various factors such as account weight, video content, and audience feedback. The TikTok platform allows viewers to support their favorite creators by sending gifts,
 Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
This AI-assisted programming tool has unearthed a large number of useful AI-assisted programming tools in this stage of rapid AI development. AI-assisted programming tools can improve development efficiency, improve code quality, and reduce bug rates. They are important assistants in the modern software development process. Today Dayao will share with you 4 AI-assisted programming tools (and all support C# language). I hope it will be helpful to everyone. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot is an AI coding assistant that helps you write code faster and with less effort, so you can focus more on problem solving and collaboration. Git
 How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
How to post videos on Weibo without compressing the image quality_How to post videos on Weibo without compressing the image quality
Mar 30, 2024 pm 12:26 PM
1. First open Weibo on your mobile phone and click [Me] in the lower right corner (as shown in the picture). 2. Then click [Gear] in the upper right corner to open settings (as shown in the picture). 3. Then find and open [General Settings] (as shown in the picture). 4. Then enter the [Video Follow] option (as shown in the picture). 5. Then open the [Video Upload Resolution] setting (as shown in the picture). 6. Finally, select [Original Image Quality] to avoid compression (as shown in the picture).
 Douyin 15 seconds is too short and I want to extend it. How can I extend it? How to make a video longer than 15 seconds?
Mar 22, 2024 pm 08:11 PM
Douyin 15 seconds is too short and I want to extend it. How can I extend it? How to make a video longer than 15 seconds?
Mar 22, 2024 pm 08:11 PM
With the popularity of Douyin, more and more people like to share their lives, talents and creativity on this platform. Douyin's 15-second limit makes many users feel that it is not enjoyable enough and hope to extend the video duration. So, how can you extend the video duration on Douyin? 1. Douyin 15 seconds is too short and I want to extend it. How can I extend it? 1. The most convenient way to shoot multiple videos and splice them is to record multiple 15-second videos, and then use the editing function of Douyin to combine them. When recording, make sure to leave some blank space at the beginning and end of each video for later splicing. The length of the spliced video can be several minutes, but this may cause the video screen to switch too frequently, affecting the viewing experience. 2. Use Douyin special effects and stickers Douyin provides a series of special effects
 In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology
Mar 25, 2024 am 09:16 AM
In addition to CNN, Transformer, and Uniformer, we finally have more efficient video understanding technology
Mar 25, 2024 am 09:16 AM
The core goal of video understanding is to accurately understand spatiotemporal representation, but it faces two main challenges: there is a large amount of spatiotemporal redundancy in short video clips, and complex spatiotemporal dependencies. Three-dimensional convolutional neural networks (CNN) and video transformers have performed well in solving one of these challenges, but they have certain shortcomings in addressing both challenges simultaneously. UniFormer attempts to combine the advantages of both approaches, but encounters difficulties in modeling long videos. The emergence of low-cost solutions such as S4, RWKV and RetNet in the field of natural language processing has opened up new avenues for visual models. Mamba stands out with its Selective State Space Model (SSM), which enables long-term dynamics while maintaining linear complexity.
 Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
On March 3, 2022, less than a month after the birth of the world's first AI programmer Devin, the NLP team of Princeton University developed an open source AI programmer SWE-agent. It leverages the GPT-4 model to automatically resolve issues in GitHub repositories. SWE-agent's performance on the SWE-bench test set is similar to Devin, taking an average of 93 seconds and solving 12.29% of the problems. By interacting with a dedicated terminal, SWE-agent can open and search file contents, use automatic syntax checking, edit specific lines, and write and execute tests. (Note: The above content is a slight adjustment of the original content, but the key information in the original text is retained and does not exceed the specified word limit.) SWE-A
