
 Technology peripherals
AI
The training cost is less than 1,000 yuan, a 90% reduction! NUS and Tsinghua University release VPGTrans: Easily customize GPT-4-like multi-modal large models
Technology peripherals
AI
The training cost is less than 1,000 yuan, a 90% reduction! NUS and Tsinghua University release VPGTrans: Easily customize GPT-4-like multi-modal large models
The training cost is less than 1,000 yuan, a 90% reduction! NUS and Tsinghua University release VPGTrans: Easily customize GPT-4-like multi-modal large models

This year is the year of explosive development of AI technology, and large language models (LLM) represented by ChatGPT have become popular.
In addition to showing great potential in the field of natural language, language models have also begun to gradually radiate to other modalities. For example, the Vincent graph model Stable Diffusion also requires a language model.
Training a visual-language model (VL-LLM) from scratch often requires a large amount of resources, so existing solutions combine language models and visual cue generation models (Visual Prompt Generator, VPG), but even then, continuing to tune VPG still requires thousands of GPU hours and millions of training data.
Recently, researchers from the National University of Singapore and Tsinghua University proposed a solution, VPGTrans, to migrate existing VPG to the existing VL-LLM model. Obtain the target VL-LLM model in a low-cost way.

## Paper link: https://arxiv.org/abs/2305.01278
Code link: https://github.com/VPGTrans/VPGTrans
Multimodal dialogue model Demo :https://vpgtrans.github.io/
Authors: Zhang Ao, Fei Hao, Yao Yuan, Ji Wei, Li Li, Liu Zhiyuan, Chua Tat- Seng
Unit: National University of Singapore, Tsinghua University
The main innovations of the article include:
1. Extremely low training cost:
Through the VPGTrans method we proposed, we can Quickly (less than 10% training time)Migrate the visual module of the existing multi-modal dialogue model to the new language model, and achieve similar or better results.
For example, compared to training the vision module from scratch, we can reduce the training overhead of BLIP-2 FlanT5-XXL from 19,000 RMB to less than 1,000 RMB:
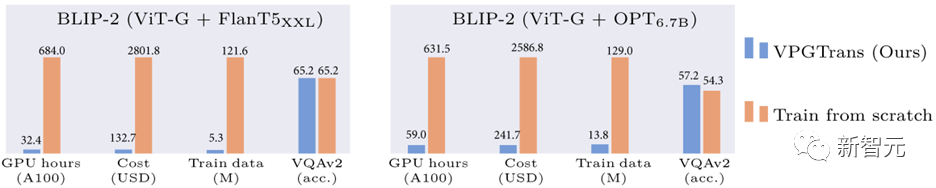
Figure 1: Comparison of BLIP-2 training overhead reduction based on our VPGTrans method
2. Multi-modal large model customization:
Can be done through our VPGTrans framework Flexibly add visual modules for various new large language models according to needs. For example, we produced VL-LLaMA and VL-Vicuna based on LLaMA-7B and Vicuna-7B.
3. Open source multi-modal dialogue model:
We have open sourced VL-Vicuna, a GPT-4-like multimodal dialogue model that can achieve high-quality multimodal dialogue:
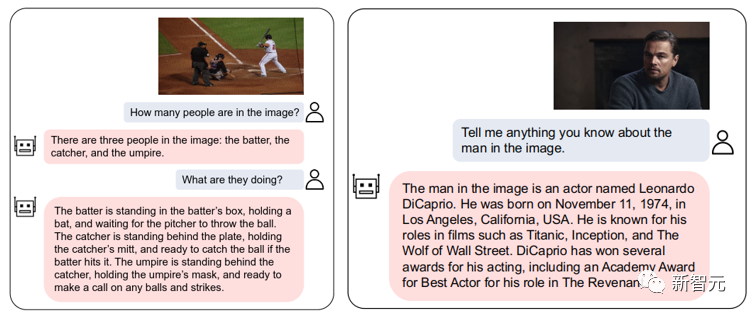
Figure 2: VL-Vicuna interaction example
1. Introduction to motivation1.1 Background
LLM has set off a revolution in the field of multi-modal understanding from traditional pre-trained visual language models (VLM) to visual language models based on large language models (VL-LLM).
By connecting the visual module to LLM, VL-LLM can inherit the knowledge of existing LLM, zero-sample generalization ability, reasoning ability and planning ability, etc. Related models include BLIP-2[1], Flamingo[2], PALM-E, etc.

Figure 3: Commonly used VL-LLM architecture
The existing commonly used VL-LLM basically adopts the architecture shown in Figure 3: a visual soft prompt generation module (Visual Prompt Generator, VPG) is trained based on a base LLM, and a linear linear model for dimension transformation. Layer (Projector).
In terms of parameter scale, LLM generally accounts for the main part (such as 11B) , VPG accounts for the minor part (such as 1.2B), and Projector is the smallest (4M).
During the training process, LLM parameters are generally not updated, or only a very small number of parameters are updated. Trainable parameters mainly come from VPG and projector.
1.2 Motivation
In fact, even if the parameters of the base LLM are frozen and not trained, due to the large parameter amount of the LLM, training a VL -The key overhead of LLM is still loading the base LLM.
Therefore, training a VL-LLM still cannot avoid huge computational costs. For example, to obtain BLIP-2 (the base LLM is FlanT5-XXL), more than 600 hours of A100 training time are required. If you rent Amazon's A100-40G machine, it will cost nearly 20,000 yuan.
Since training a VPG from scratch is so expensive, we began to think about whether we could migrate an existing VPG to a new LLM to save costs.
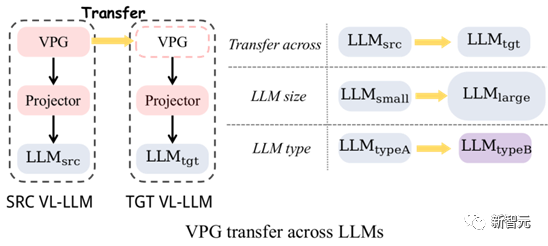
##Figure 4: VPG migration: cross-LLM size migration and cross-LLM type migration
As shown in Figure 4, we mainly explored the migration of two types of VPGs:
(1) Cross-LLM size migration (TaS) : For example, from OPT-2.7B to OPT-6.7B.
(2) Cross-LLM type migration (TaT): such as from OPT to FlanT5.
The significance of TaS is: in LLM-related scientific research, we usually need to adjust parameters on a small LLM and then expand to a large LLM. With TaS, we can directly migrate the VPG that has been trained on the small LLM to the large LLM after adjusting the parameters.
The significance of TaT is that LLMs with different functions emerge in endlessly. For example, there is LLaMA today, and Alpaca and Vicuna tomorrow. TaT allows us to use existing VPG to quickly add visual perception capabilities to new language models.
1.3 Contribution
(1) Propose efficient methods:
We first explored the key factors that affect VPG migration efficiency through a series of exploratory experiments. Based on the exploratory experimental findings, we propose a two-stage efficient migration framework VPGTrans. This framework can significantly reduce the computational overhead and required training data required to train VL-LLM.
For example, compared to training from scratch, we canonly use about 10% of the data and computing time by migrating BLIP-2 OPT-2.7B to 6.7B VPG Achieve similar or better results for each data set (Figure 1) . Training costs range from 17,901 RMB to 1,673 RMB.
(2) Obtain interesting discoveries:
We provide some interesting results in both TaS and TaT scenarios. Discover and try to explain:
a) In TaS scenario, using VPGTrans to migrate from small to large will not affect the final model effect.
b) In the TaS scenario, the smaller the VPG trained on the language model, the higher the efficiency when migrating to the large model, and the better the final effect.
c) In the TaT scenario, the smaller the model, the larger the migration gap is. In our verification experiments, mutual migration between OPT350M and FlanT5-base using VPGTrans is almost as slow as training from scratch.
(3) Open source:
We got two new ones using VPGTrans VL-LLMs: VL-LLaMA and VL-Vicuna, and are open sourced in the community. Among them, VL-Vicuna implements high-quality multi-modal dialogue similar to GPT4.
2. High-efficiency VPG migration solution: VPGTrans
First, we conduct a series of exploration and verification experiments to analyze how to maximize the migration efficiency of VPG. We then propose a solution based on these important observations.
2.1 Exploration Experiment
We select the BLIP-2 architecture as our basic model, and the pre-training corpus uses COCO and SBU, a total of 1.4M Picture and text pairs.
Downstream tasks are evaluated using the zero-shot settings of COCO Caption, NoCaps, VQAv2, GQA and OK-VQA (the caption task is not strictly zero-shot). The following are our key findings:
(1) Directly inheriting a trained VPG can accelerate convergence, but the effect is limited:
We found that directly migrating a VPG trained on an LLM to a large LLM can accelerate model convergence, but the acceleration effect is limited, and the model effect after convergence is compared to training VPG from scratch Points will drop (the highest points of the VQAv2 and GQA blue lines in Figure 5 are both lower than the orange line) .
We speculate that this drop is due to the fact that the randomly initialized projector will damage the existing visual perception ability in VPG at the beginning of training.

The following figure shows the results obtained by directly inheriting the implemented VPG (blue curve). Retrain VPG (orange line): Retrain VPG from scratch. The only training conducted is on the linear projector, with no training on VPG..
(2) Warm-up training the projector first can prevent points from dropping and further accelerate convergence:
So, we fixed the VPG and LLM, first warm-up trained the projector for 3 epochs, and then unfrozen the VPG for the next step of training.
We found that this can not only avoid point drops, but also further accelerate VPG convergence (Figure 6).
But it is worth emphasizing that since the main cost of training is LLM (huge parameters), the cost of just training the projector will not Much less expensive than training VPG and projector at the same time.
So, we began to explore the key technologies to accelerate projector warm-up.
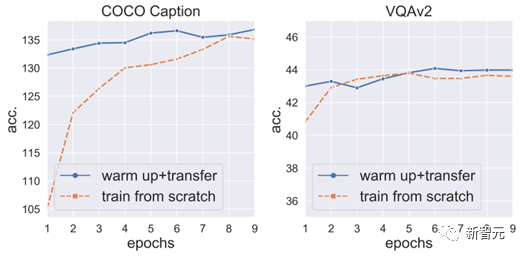
Figure 6: Warm-up training the projector first can prevent points from dropping and accelerate convergence
(3) Word vector converter initialization can speed up projector warm-up:
First of all, VPG produces effects by converting images into soft prompts that LLM can understand. The usage of soft prompt is actually very similar to word vector , all directly input the language model to prompt the model to generate corresponding content.
So, we used word vectors as a proxy for soft prompt and trained a
to 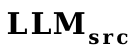
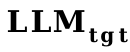
as the initialization of the projector . 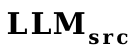
3 epochs to 2 epochs.
(4) Projector can quickly converge at a very large learning rate:
We further experimented and found that projector due to It has a small number of parameters and can be trained using 5 times the normal learning rate without crashing.Through training with 5 times the learning rate, projector warm-up can be
further shortened to 1 epoch.
(5) An additional finding:Although projector warm-up is important, training the projector alone is not enough. Especially for the caption task, the effect of training only the projector is worse than the effect of training VPG at the same time (the green line in Figure 5 is much lower than the blue line in both COCO Caption and NoCaps).
This also means that
merely training the projector will lead to underfitting, that is, cannot be fully aligned to the training data.
2.2 Our proposed method
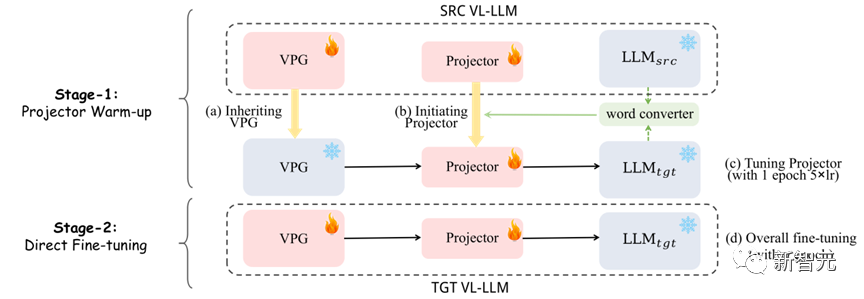
As shown in Figure 7, Our method is divided into two stages:
(1) The first stage: We first use the word vector converter to fuse with the original projector as the initialization of the new projector, and then use The new projector is trained with 5 times the learning rate for one epoch.
(2) The second stage: directly train VPG and projector normally.
3. Experimental results
3.1 Speedup ratio
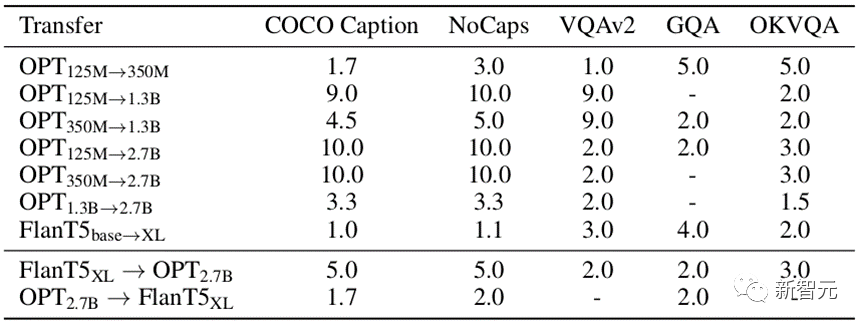
As shown in Table 1, we tested different migrations Type, speedup ratio of VPGTrans on different data sets.
The acceleration ratio of VPGTrans on a specified data set A is obtained by dividing the number of rounds of training from scratch to achieve the best effect a on A by the minimum number of training rounds where VPGTrans's effect on A exceeds a.
For example, training VPG on OPT-2.7B from scratch requires 10 epochs to achieve the best effect in COCO caption, but migrating VPG from OPT-125M to OPT-2.7B only takes It takes 1 epoch to achieve this optimal effect. The acceleration ratio is 10/1=10 times.
We can see that our VPGTrans can achieve stable acceleration whether in TaS or TaT scenarios.
3.2 Interesting findings
We have selected one of the more interesting findings to explain. For more interesting findings, please refer to us thesis.
#In the TaS scenario, the smaller the VPG trained on the language model, the higher the migration efficiency, and the better the final model effect. Referring to Table 1, we can find that the acceleration ratio from OPT-1.3B to OPT-2.7B is much smaller than the acceleration ratio from OPT-125M and OPT-350M to OPT-2.7b.
We tried to provide an explanation: Generally, the larger the language model, due to the higher dimensionality of its text space, will be more likely to damage the VPG (VPG is generally a pre-trained model similar to CLIP) its own visual perception ability. We verified it in a way similar to linear probing:
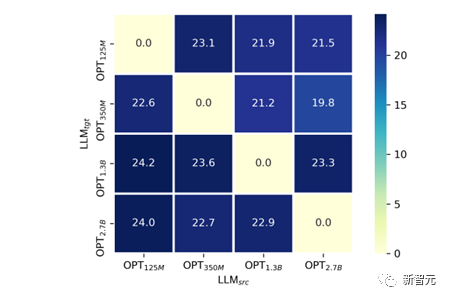
## Figure 8: Only train the linear projector layer Cross-LLM size migration (simulating linear probing)
As shown in Figure 8, we performed cross-LLM size migration between OPT-125M, 350M, 1.3B, and 2.7B size migration.
In the experiment, In order to fairly compare the visual perception capabilities of VPG trained under different model sizes, we fixed the parameters of VPG and only trained the linear projector layer. We selected the SPICE indicator on COCO Caption as a measure of visual perception ability.
It is not difficult to find that for each given, it is almost consistent that the smaller the  , the smaller the final SPICE A high phenomenon.
, the smaller the final SPICE A high phenomenon. 
The previous experiments are mainly to verify conjectures in small-scale scenarios. In order to prove the effectiveness of our method, we simulated the pre-training process of BLIP-2 and conducted large-scale experiments:
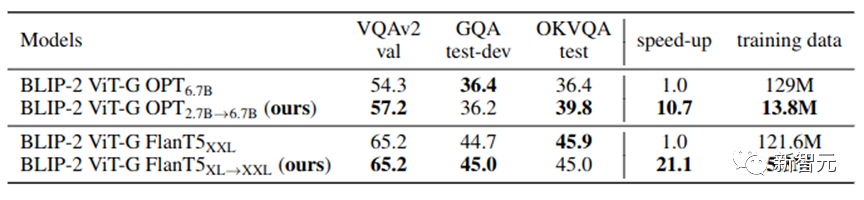
Table 2: Large-scale experimental results in real scenarios
As shown in Table 2, our VPGTrans is still effective in large-scale scenarios. By migrating from OPT-2.7B to OPT-6.7B, we only used 10.8% of the data and less than 10% of the training time to achieve similar or better results.In particular, our method achieves
4.7% training cost control in BLIP-2 VL-LLM based on FlanT5-XXL. 4. Customize your VL-LLMs
Our VPGTrans can quickly add visual perception modules to any new LLMs, thereby obtaining a brand new high-quality VL- LLM. In this work, we additionally train a VL-LLaMA and a VL-Vicuna. The effect of VL-LLaMA is as follows:
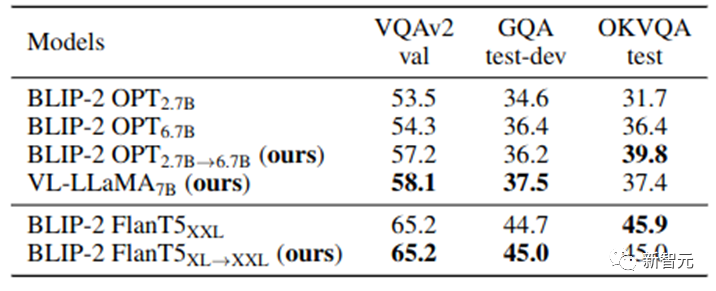
Table 3: Effect display of VL-LLaMA
At the same time, Our VL-Vicuna can conduct GPT-4-like multi-modal conversations. We made a simple comparison with MiniGPT-4:
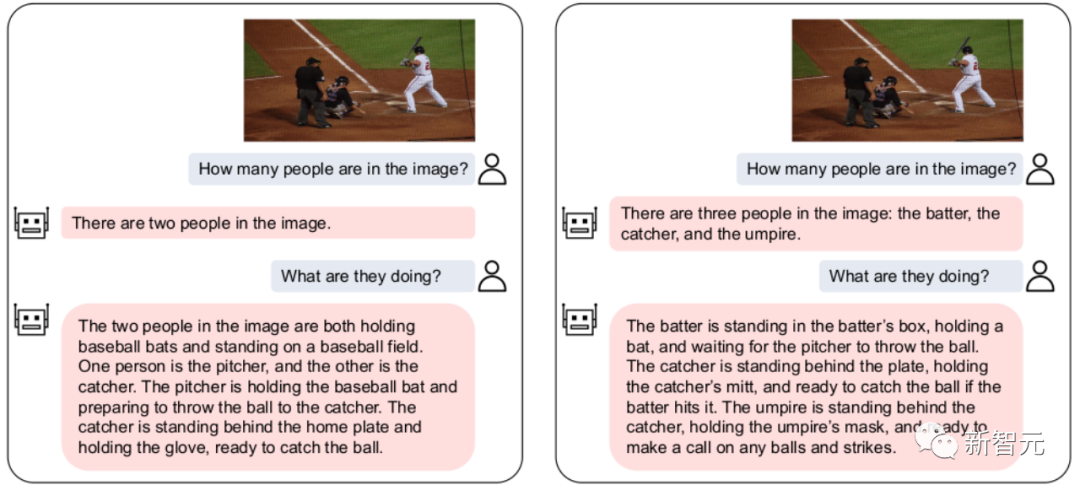
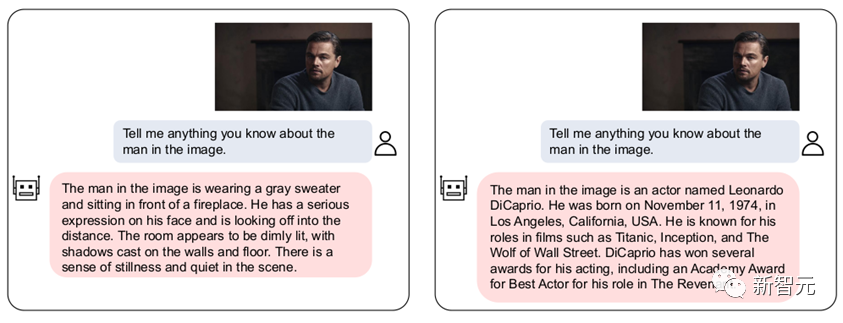
In this work, we conducted a comprehensive investigation on the portability issue of VPG between LLMs. We first explore the key factors that maximize migration efficiency.
Based on key observations, we propose a novel two-stage migration framework, namely VPGTrans. It can achieve equivalent or better performance while significantly reducing training costs.
Through VPGTrans, we achieved VPG migration from BLIP-2 OPT 2.7B to BLIP-2 OPT 6.7B. Compared to connecting VPG to OPT 6.7B from scratch, VPGTrans only requires 10.7% training data and less than 10% training time.
Furthermore, we present and discuss a series of interesting findings and the possible reasons behind them. Finally, we demonstrate the practical value of our VPGTrans in customizing new VL-LLM by training VL-LLaMA and LL-Vicuna.
The above is the detailed content of The training cost is less than 1,000 yuan, a 90% reduction! NUS and Tsinghua University release VPGTrans: Easily customize GPT-4-like multi-modal large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
