


Today’s artificial intelligence (AI) is limited. It still has a long way to go.
Some AI researchers have discovered that machine learning algorithms, in which computers learn through trial and error, have become a "mysterious force."
Recent advances in artificial intelligence (AI) are improving many aspects of our lives.
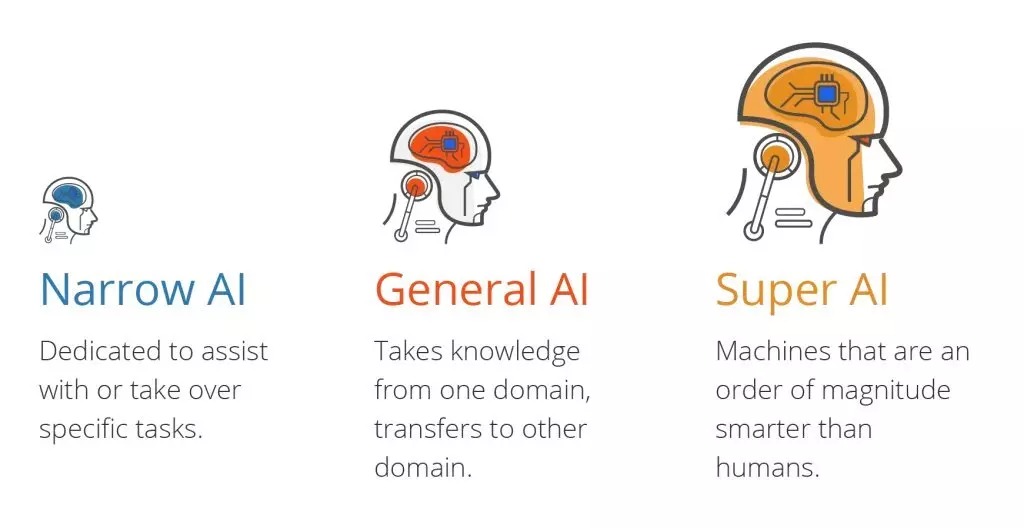
There are three types of artificial intelligence:
Today’s artificial intelligence is primarily driven by statistical learning models and algorithms called data analysis, machine learning, artificial neural networks, or deep learning. It is implemented as a combination of IT infrastructure (ML platform, algorithms, data, computation) and development stack (from libraries to languages, IDEs, workflows and visualizations).
In short, it involves:
Most AI applications in use today can be classified as narrow AI, known as weak AI.
They all lack general artificial intelligence and machine learning, which are defined by three key interaction engines:
General AI and ML and DL applications/machines/systems The difference lies in understanding the world as multiple plausible representations of world states, its reality machine and global knowledge engine and world data engine.
It is the most important component of the General/Real AI Stack, interacting with its real-world data engine and providing intelligent functions/capabilities:
In fact, it is mainly a statistical inductive reasoning engine that relies on big data computing, algorithm innovation, and statistical learning theory and connectionist philosophy.
For most people, it is just building a simple machine learning (ML) model, going through data collection, management, exploration, feature engineering, model training, evaluation, and finally deployment.
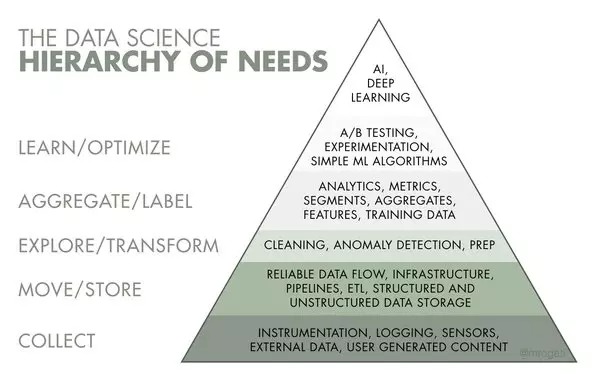
EDA: Exploratory Data Analysis
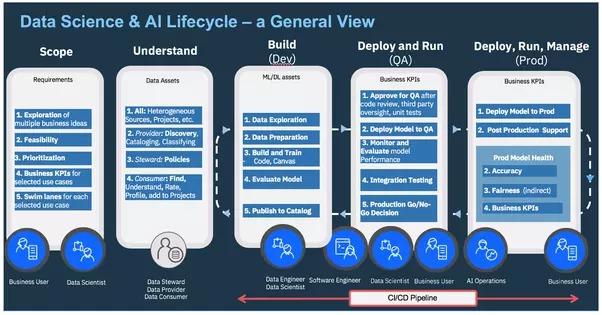
AI Ops — Managing the end-to-end lifecycle of AI
The capabilities of today’s artificial intelligence come from “machine learning,” which requires configuring and tuning algorithms for each different real-world scenario. This makes it very manual and requires a lot of time to oversee its development. This manual process is also error-prone, inefficient, and difficult to manage. Not to mention the lack of expertise in being able to configure and tune different types of algorithms.
Configuration, tuning and model selection are becoming increasingly automated, and all major technology companies such as Google, Microsoft, Amazon, and IBM have launched similar AutoML platforms to automate the machine learning model building process.
AutoML involves automating the tasks required to build predictive models based on machine learning algorithms. These tasks include data cleaning and preprocessing, feature engineering, feature selection, model selection, and hyperparameter tuning, which can be tedious to perform manually.
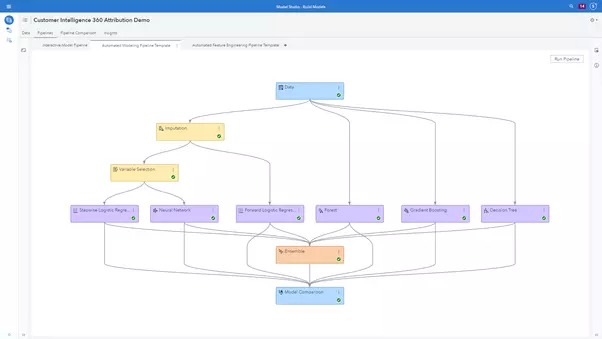
SAS4485-2020.pdf
The end-to-end ML pipeline presented consists of 3 key stages while missing the source of all data, which is the world Itself:
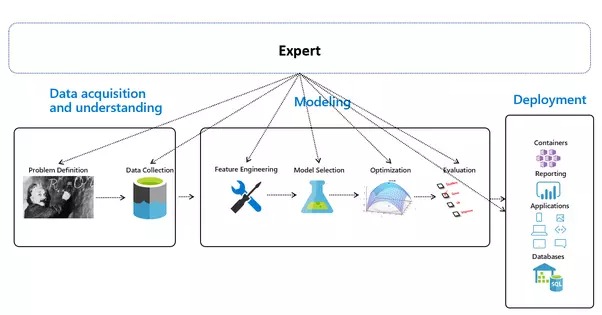
Automated Machine Learning - Overview
The key secret of Big-Tech AI is Skin-Deep Machine Learning as a dark deep neural network, which The model needs to be trained with large amounts of labeled data and a neural network architecture that contains as many layers as possible.
Each task requires its special network architecture:
ANN was introduced as an information processing paradigm that seems to be inspired by the way biological nervous systems/brains process information . And such artificial neural networks are represented as "universal function approximators", which can learn/compute various activation functions.
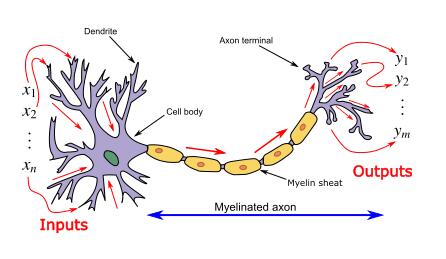
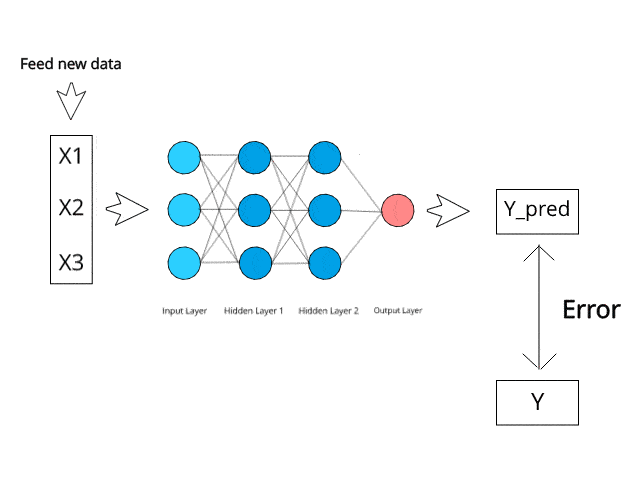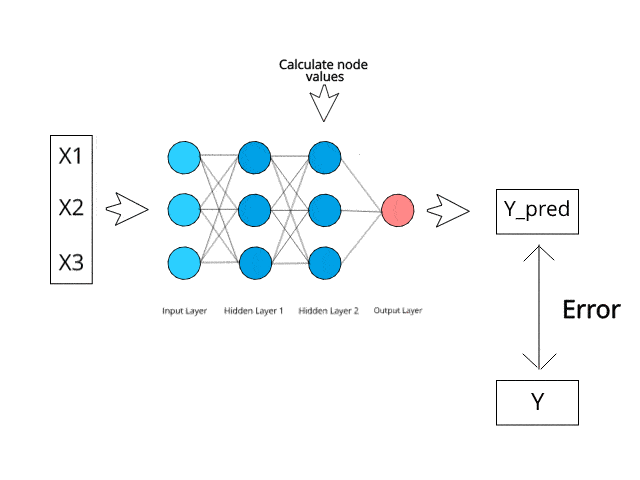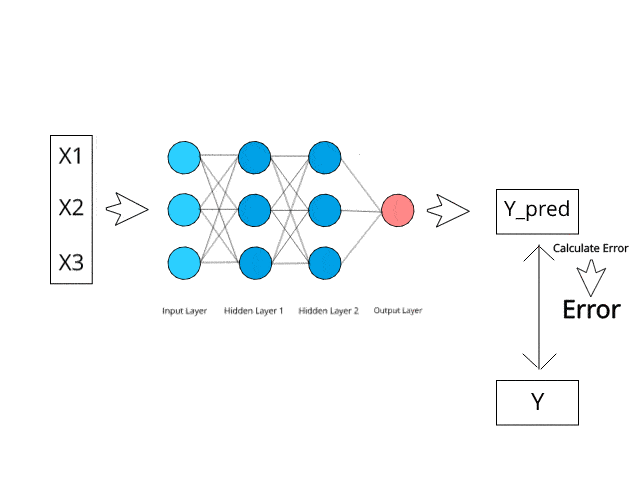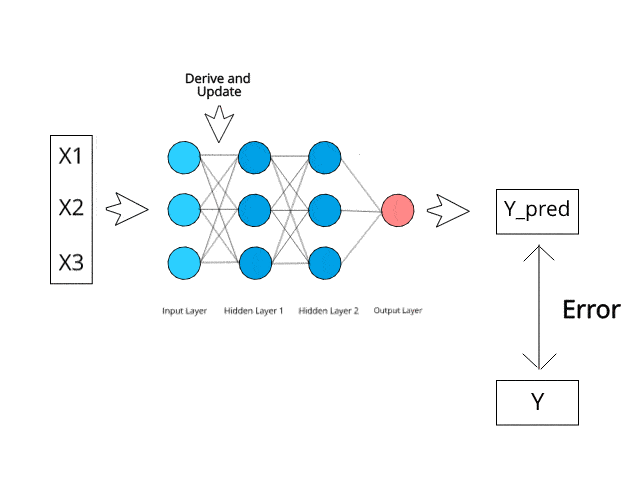
The neural network calculates/learns through specific backpropagation and error correction mechanisms during the test phase.
Imagine that by minimizing errors, these multi-layered systems could one day learn and conceptualize ideas on their own.
In summary, a few lines of R or Python code are enough to implement machine intelligence, and there are numerous online resources and tutorials for training quasi-neural networks of various depths Forge networks, manipulate images-video-audio-text, and have zero understanding of the world, such as Generative Adversarial Networks, BigGAN, CycleGAN, StyleGAN, GauGAN, Artbreeder, DeOldify, etc.
They create and modify faces, landscapes, generic images, etc. with zero understanding of what it's all about.
Using cycle-consistent adversarial networks for unpaired image-to-image translation makes 2019 the new AI era for 14 uses of deep learning and machine learning.
There are countless digital tools and frameworks that work in their own way:
Sadly, the data scientist’s work environment: scikit-learn, R, SparkML, Jupyter, R, Python, XGboost, Hadoop, Spark, TensorFlow, Keras, PyTorch, Docker, Plumbr The list goes on and on.
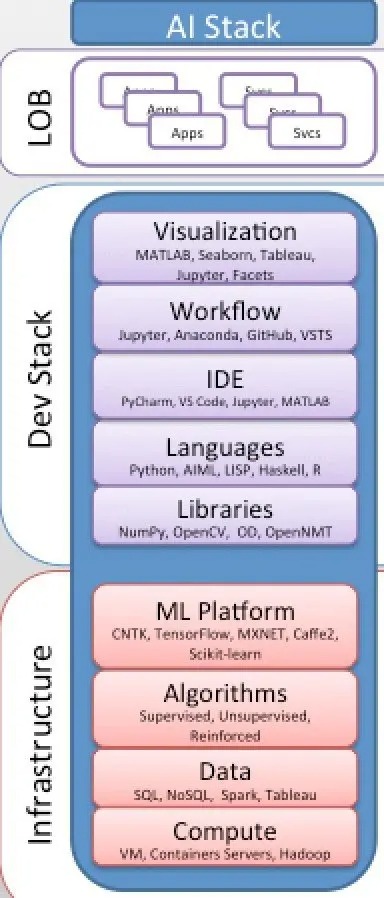
Modern AI Stack and AI-as-a-Service Consumption Model
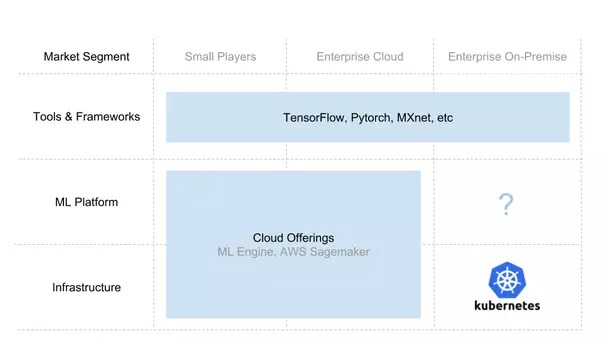
Building an AI Stack
Pretending to be artificial intelligence, In fact, it is fake artificial intelligence. At its best it is an automatic learning technique, a ML/DL/NN pattern recognizer, mathematical and statistical in nature, unable to act intuitively or model its environment, with zero intelligence, zero learning and zero understanding.
Despite its many advantages, artificial intelligence is not perfect. The following are 8 problems and fundamental mistakes that hinder the progress of artificial intelligence:
Artificial intelligence requires large data sets for training, and these data sets should be inclusive/unbiased , and the quality is good. Sometimes they have to wait for new data to be generated.
Artificial intelligence requires enough time for the algorithm to learn and develop enough to achieve its purpose with considerable accuracy and relevance. It also requires significant resources to function. This may mean additional requirements on your computer abilities.
Another major challenge is the ability to accurately interpret the results generated by an algorithm. Algorithms must also be carefully selected based on one's purpose.
Artificial intelligence is autonomous, but highly error-prone. Suppose the algorithm is trained on a data set that is small enough to make it non-inclusive. You end up with biased predictions from a biased training set. In the case of machine learning, such missteps can trigger a cascade of errors that can go undetected for a long time. When they do get noticed, it can take quite some time to identify the source of the problem, and even longer to correct it.
The idea of trusting data and algorithms over our own judgment has its advantages and disadvantages. Clearly, we benefit from these algorithms, otherwise, we wouldn't be using them in the first place. These algorithms allow us to automate processes by making informed judgments using available data. However, sometimes this means replacing someone's job with an algorithm, which has ethical consequences. Furthermore, if something goes wrong, who should we blame?
Artificial intelligence is still a relatively new technology. Machine learning experts are needed to maintain the process, from the startup code to the maintenance and monitoring of the process. The artificial intelligence and machine learning industry is still relatively new to the market. Finding adequate resources in human form is also difficult. Therefore, there is a lack of talented representatives available to develop and manage machine learning scientific material. Data researchers often require a mix of spatial insights, as well as mathematical, technical and scientific knowledge from start to finish.
Artificial intelligence requires a lot of data processing capabilities. Inheritance frameworks cannot handle responsibilities and constraints under pressure. The infrastructure should be checked if it can handle the issues in AI. If not, it should be completely upgraded with good hardware and adaptable storage.
Artificial intelligence is very time-consuming. Due to data and request overload, results are taking longer than expected to be delivered. Focusing on specific features in a database to generalize results is common in machine learning models, which can lead to bias.
Artificial intelligence has taken over many aspects of our lives. While not perfect, artificial intelligence is a growing field and is in high demand. It provides real-time results using already existing and processed data without human intervention. It helps analyze and evaluate large amounts of data, often by developing data-driven models. Although there are many problems with artificial intelligence, it is an evolving field. From medical diagnosis and vaccine development to advanced trading algorithms, artificial intelligence has become the key to scientific progress.
The above is the detailed content of Eight issues hindering the progress of artificial intelligence. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Will the Bitcoin inscription disappear?
Will the Bitcoin inscription disappear?
 How to open mobi file
How to open mobi file
 psrpc.dll not found solution
psrpc.dll not found solution
 Dual graphics card notebook
Dual graphics card notebook
 PHP simple website building tutorial
PHP simple website building tutorial
 The difference between shingled disks and vertical disks
The difference between shingled disks and vertical disks








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



