

In the past time, we have learned the RNN recurrent neural network, and its structural diagram is as follows:
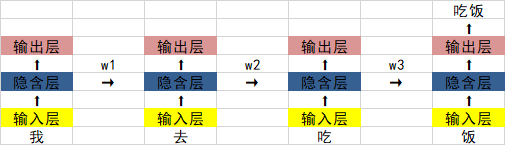
The biggest problem is that when the values of w1, w2, and w3 are less than 0, if a sentence is long enough, then when the neural network performs back propagation and forward propagation, there will be The problem of vanishing gradient.
0.925=0.07. If a sentence has 20 to 30 words, then the hidden layer output of the first word will be 0.07 times larger than the output of the last word. The impact is greatly reduced.
The specific situation is as follows:
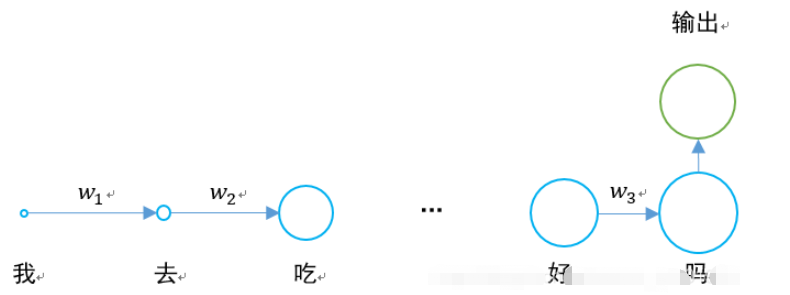
The long short-term memory network emerged to solve the problem of gradient disappearance.
The hidden layer of the original RNN has only one state h, which is passed from beginning to end. It is very sensitive to short-term input.
If we add another state c and let it save the long-term state, the problem can be solved.
For RNN and LSTM, the comparison of the two step units is as follows.

We expand the structure of LSTM according to the time dimension:
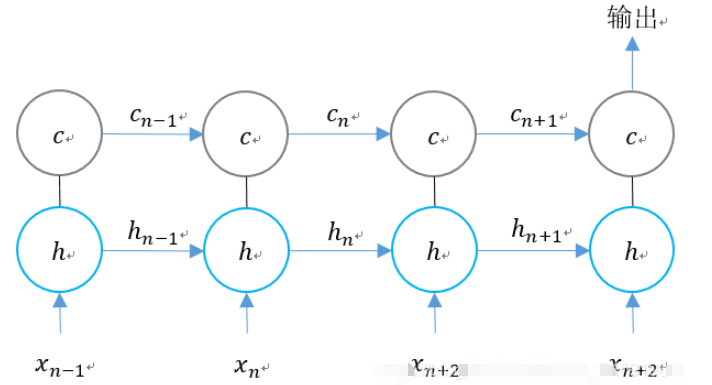
We can see that at n time, LSTM There are three inputs:
1. The input value of the network at the current moment;
2. The output value of the LSTM at the previous moment ;
3. The unit status at the last moment.
There are two outputs of LSTM:
1. LSTM output value at the current moment;
2. The unit status at the current moment.
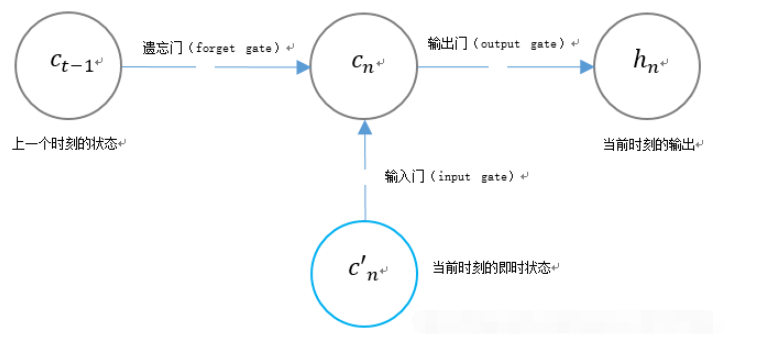
3. LSTM’s unique gate structure
LSTM uses two gates to control the content of unit state cn:
1. Forgetting Gate (forget gate), which determines how much of the unit state cn-1 of the previous moment is retained to the current moment;
2. Input gate (input gate), which It determines how much of the input c’n of the network at the current moment is saved to the unit state.
LSTM uses a gate to control the content of the current output value hn:
Output gate (output gate), which determines the unit state cn at the current moment. How much output.
tf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)num_units: RNN unit The number of neurons, that is, the number of output neurons.
forget_bias: Bias added to forget gate. Manually set the restored CudnnLSTM training checkpoint to 0.0.
state_is_tuple: If True, the accepted and returned states are 2-tuples of c_state and m_state; if False, they are connected along the column axis. False is about to be deprecated.
activation: activation function.
reuse: Describes whether to reuse the variable in the existing scope. If an existing scope already has the given variable and it is not True, an error is raised.
name: The name of the layer.
dtype: The data type of this layer.
When used, it can be defined as:
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
After the definition is completed, the state can be initialized:
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)cell: lstm_cell defined above.
inputs: RNN input. If time_major==false (default), must be a tensor of shape: [batch_size, max_time, …] or a nested tuple of such elements. If time_major==true, it must be a tensor of shape: [max_time, batch_size, …] or a nested tuple of such elements.
The size of the vector is determined by the sequence_length parameter, and its type is Int32/Int64. Used to copy through status and zero output when the sequence length of batch elements is exceeded. So it's more about performance than correctness.
initial_state: _init_state defined above.
dtype: data type.
parallel_iterations: Number of iterations to run in parallel. Those operations will be those that do not have any time dependency and can be run in parallel. This parameter trades time for space. Larger values consume more memory but operate faster, while smaller values use less memory but require longer computation time.
time_major:输入和输出tensor的形状格式。这些张量的形状必须为[max_time, batch_size, depth],若表述正确,则它为真。这些张量的形状必须是[batch_size,max_time,depth],如果为假。time_major=true可以提高效率,因为它避免了在RNN计算的开头和结尾进行转置操作。默认情况下,此函数为False,因为大多数的 TensorFlow 数据以批处理主数据的形式存在。
scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))The above is the detailed content of How to use tensorflow to build long short-term memory LSTM in python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



