
 Technology peripherals
AI
What are the differences between llama, alpaca, vicuña and ChatGPT? Evaluation of seven large-scale ChatGPT models
Technology peripherals
AI
What are the differences between llama, alpaca, vicuña and ChatGPT? Evaluation of seven large-scale ChatGPT models
What are the differences between llama, alpaca, vicuña and ChatGPT? Evaluation of seven large-scale ChatGPT models

Large-scale language models (LLM) are becoming popular all over the world. One of their important applications is chatting, and they are used in question and answer, customer service and many other aspects. However, chatbots are notoriously difficult to evaluate. Exactly under what circumstances these models are best used is not yet clear. Therefore, the assessment of LLM is very important.
Previously, a Medium blogger named Marco Tulio Ribeiro conducted some complex tasks on Vicuna-13B, MPT-7b-Chat and ChatGPT 3.5 test. The results show that Vicuna is a viable alternative to ChatGPT (3.5) for many tasks, while MPT is not yet ready for real-world use.
Recently, CMU associate professor Graham Neubig conducted a detailed evaluation of seven existing chatbots, produced an open source tool for automatic comparison, and finally formed an evaluation report.
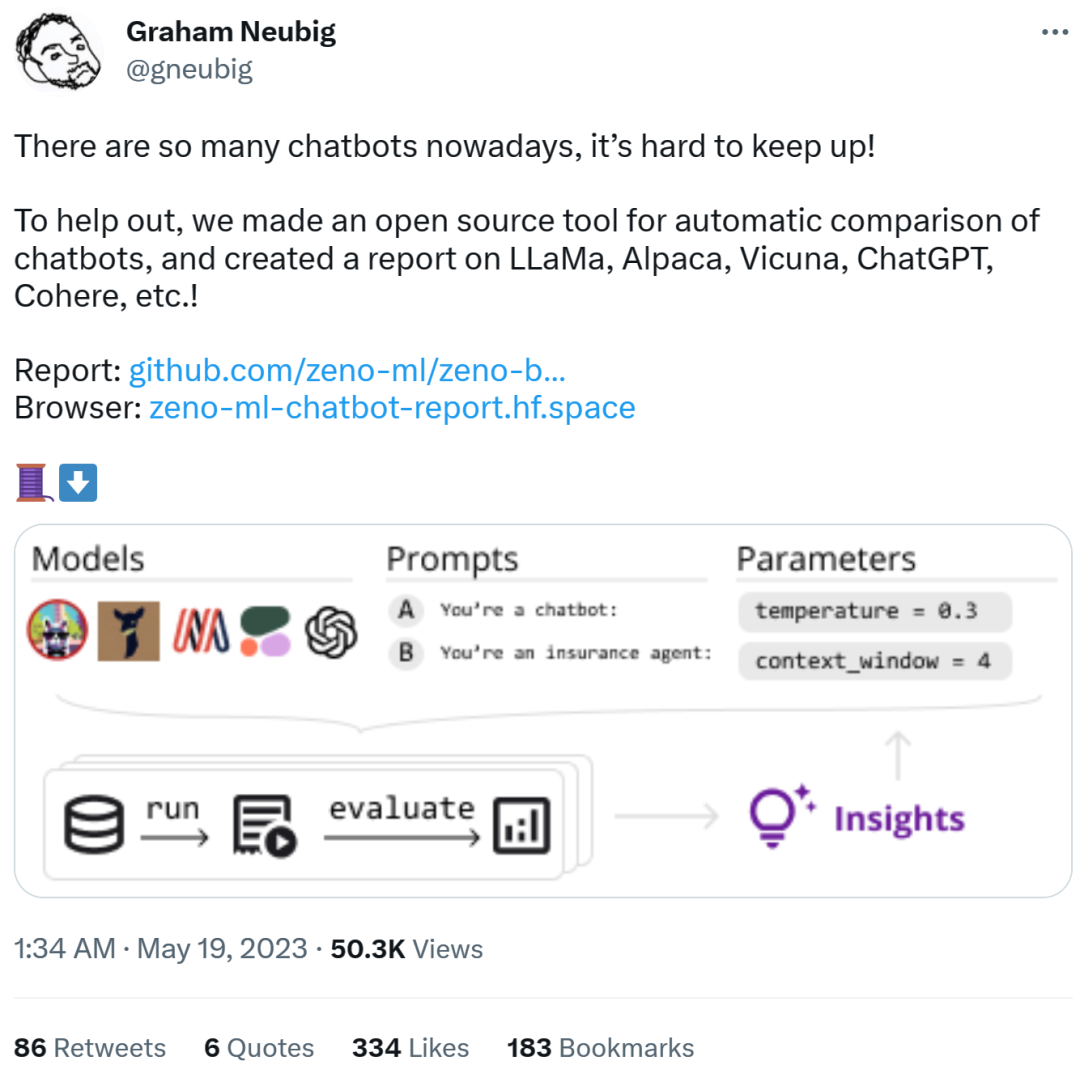
In this report, the evaluator shows the preliminary evaluation and comparison results of some chatbots. The goal is to make it easier for people to understand all the recent open source models and the current status of API-based models.
Specifically, the reviewers created a new open source toolkit, Zeno Build, for evaluating LLM. The toolkit combines: (1) a unified interface for using open source LLM via Hugging Face or the online API; (2) an online interface for browsing and analyzing results using Zeno, and (3) metrics for SOTA evaluation of text using Critique.
Specific results to participate: https://zeno-ml-chatbot-report.hf .space/
The following is a summary of the evaluation results:
- The reviewers evaluated 7 language models: GPT- 2. LLaMa, Alpaca, Vicuna, MPT-Chat, Cohere Command and ChatGPT (gpt-3.5-turbo);
- These models are based on which human-like images are created on the customer service data set The responsiveness of , it is important to use a chat-tuned model with a long context window;
- In the first few turns of the conversation, the prompt project is very useful for improving the performance of the model conversation, but when there are more In the later rounds of multi-context, the effect is not so obvious;
- Even a powerful model like ChatGPT has many obvious problems, such as hallucinations and failure to explore more information, give duplicate content, etc.
- The following are the details of the review.
- Settings
Model Overview
The reviewerused DSTC11 Customer Service Dataset. DSTC11 is a dataset from the Dialogue Systems Technology Challenge that aims to support more informative and engaging task-oriented conversations by leveraging subjective knowledge in comment posts.
The DSTC11 data set contains multiple subtasks, such as multi-turn dialogue, multi-domain dialogue, etc. For example, one of the subtasks is a multi-turn dialogue based on movie reviews, where the dialogue between the user and the system is designed to help the user find movies that suit their tastes. They tested the following
7 models:
- GPT-2: A classic language model in 2019. The reviewers included it as a baseline to see how much recent advances in language modeling impact building better chat models.
- LLaMa: A language model originally trained by Meta AI using the direct language modeling objective. The 7B version of the model was used in the test, and the following open source models also use the same scale version;
- Alpaca: a model based on LLaMa, but with instruction tuning;
- Vicuna: a model based on LLaMa, further explicitly adapted for chatbot-based applications;
- MPT-Chat: a model based on something similar to A model trained from scratch in Vicuna's way, which has a more commercial license;
- Cohere Command: An API-based model launched by Cohere that is fine-tuned for command compliance;
- ChatGPT (gpt-3.5-turbo): Standard API-based chat model, developed by OpenAI.
For all models, the reviewer used the default parameter settings. These include a temperature of 0.3, a context window of 4 previous conversation turns, and a standard prompt: "You are a chatbot tasked with making small-talk with people."
Evaluation Metrics
Evaluators evaluate these models based on how closely their output resembles human customer service responses . This is done using the metrics provided by the Critique toolbox:
- #chrf: measures the overlap of strings;
- BERTScore: Measures the degree of overlap in embeddings between two discourses;
- UniEval Coherence: Predicts how coherent the output is with the previous chat turn.
They also measured length ratio, dividing the length of the output by the length of the gold standard human reply, to measure whether the chatbot was verbose.
Further analysis
In order to dig deeper into the results, the reviewer used Zeno’s analysis interface. Specifically using its report generator, which segments examples based on position in the conversation (beginning, early, middle, and late) and the gold standard length of human responses (short, medium, long), use its explore interface to view Automatically score poor examples and better understand where each model fails.
Results
What is the overall performance of the model?
According to all these metrics, gpt-3.5-turbo is the clear winner; Vicuna is the open source winner; GPT-2 and LLaMa are not very good, indicating that directly in the chat The importance of training.

These rankings also roughly match those of lmsys chat arena, which uses human A/B testing to compare models, but Zeno Build’s The results were obtained without any human scoring.
Regarding output length, the output of gpt3.5-turbo is much verbose than other models, and it seems that models tuned in the chat direction generally give verbose output .
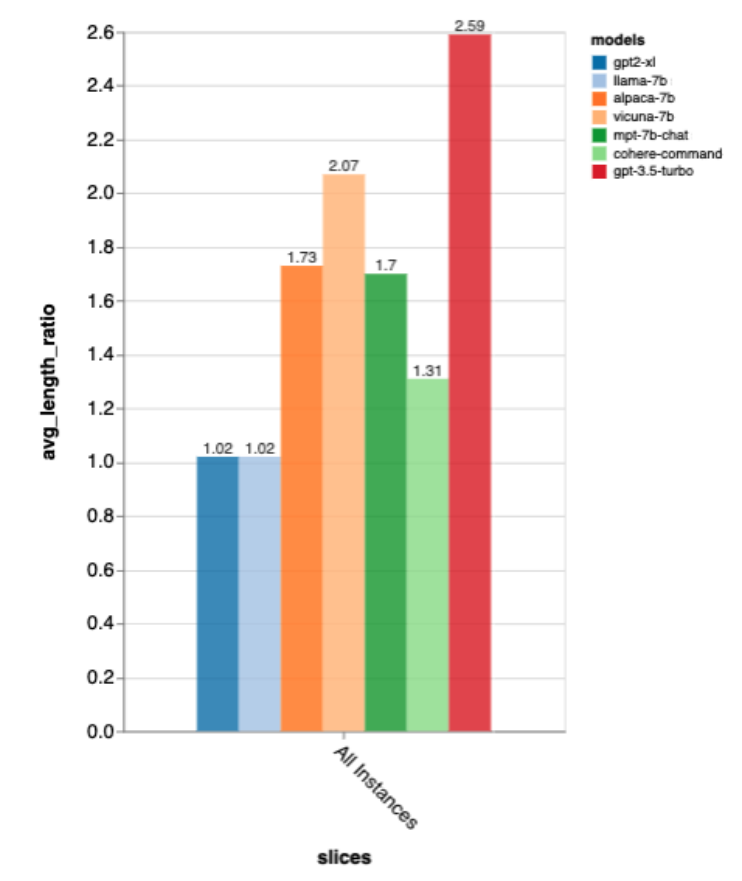
Accuracy of Gold Standard Response Length
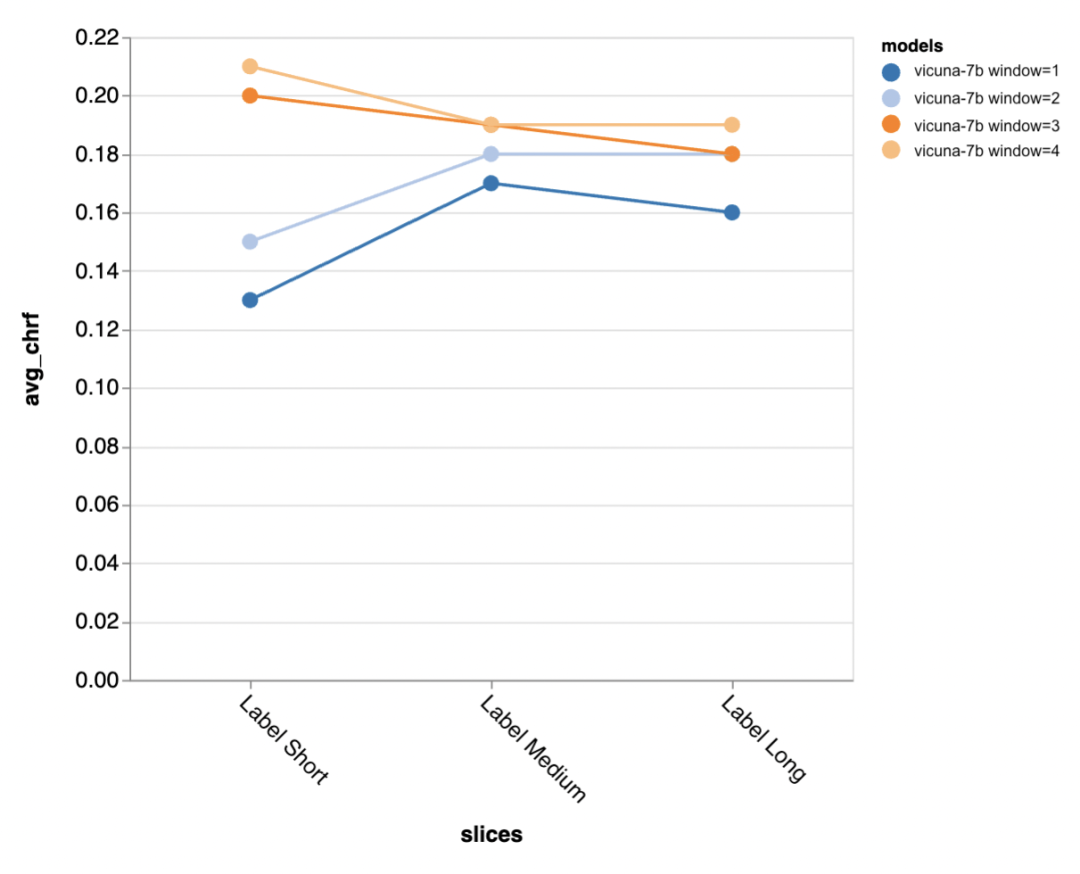
Next, the reviewer uses the Zeno report UI to dig deeper. First, they measured accuracy separately by the length of human responses. They classified responses into three categories: short (≤35 characters), medium (36-70 characters), and long (≥71 characters) and evaluated their accuracy individually.
gpt-3.5-turbo and Vicuna maintain accuracy even in longer dialogue rounds, while the other models suffer from a decrease in accuracy.
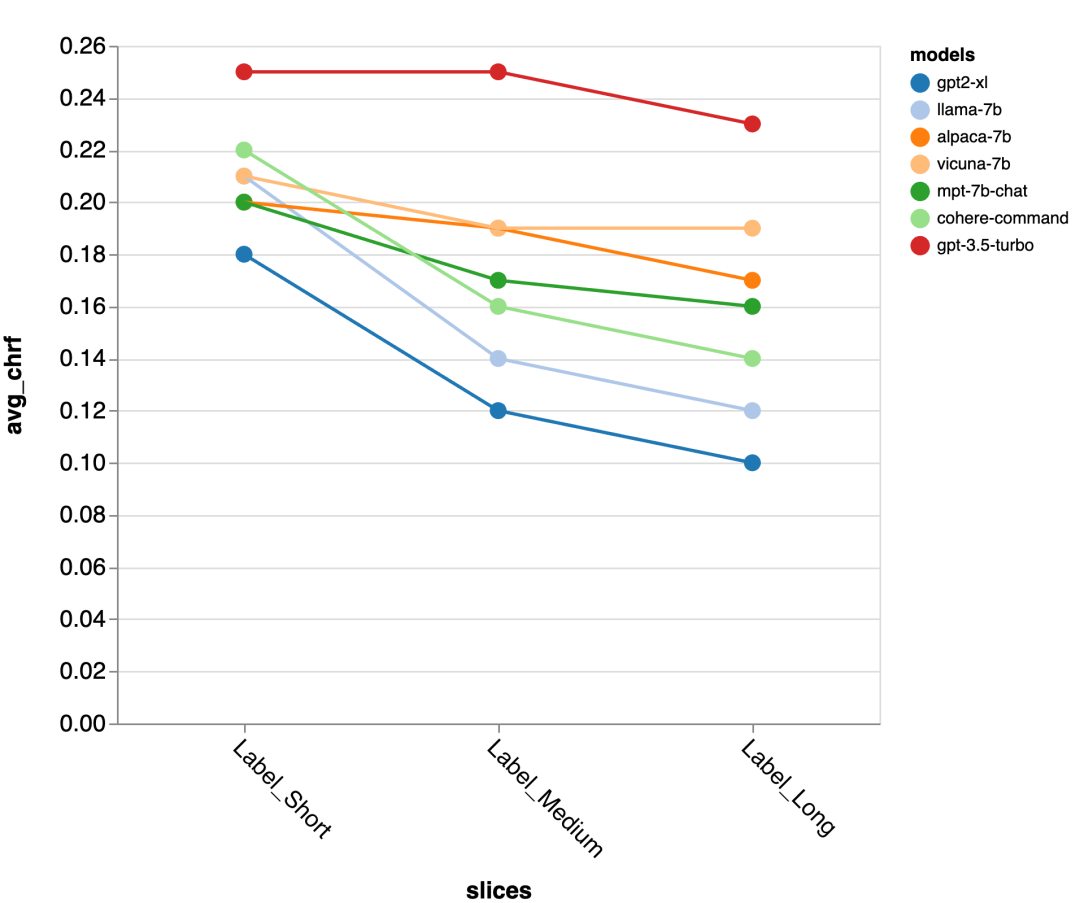
#The next question is how important is the context window size? The reviewers conducted experiments with Vicuna, and the context window ranged from 1-4 previous discourses. When they increased the context window, model performance increased, indicating that larger context windows are important.

The results show that longer context is especially important in the middle and later parts of the conversation, because these positions There are not so many templates for the reply, and it relies more on what has been said before.
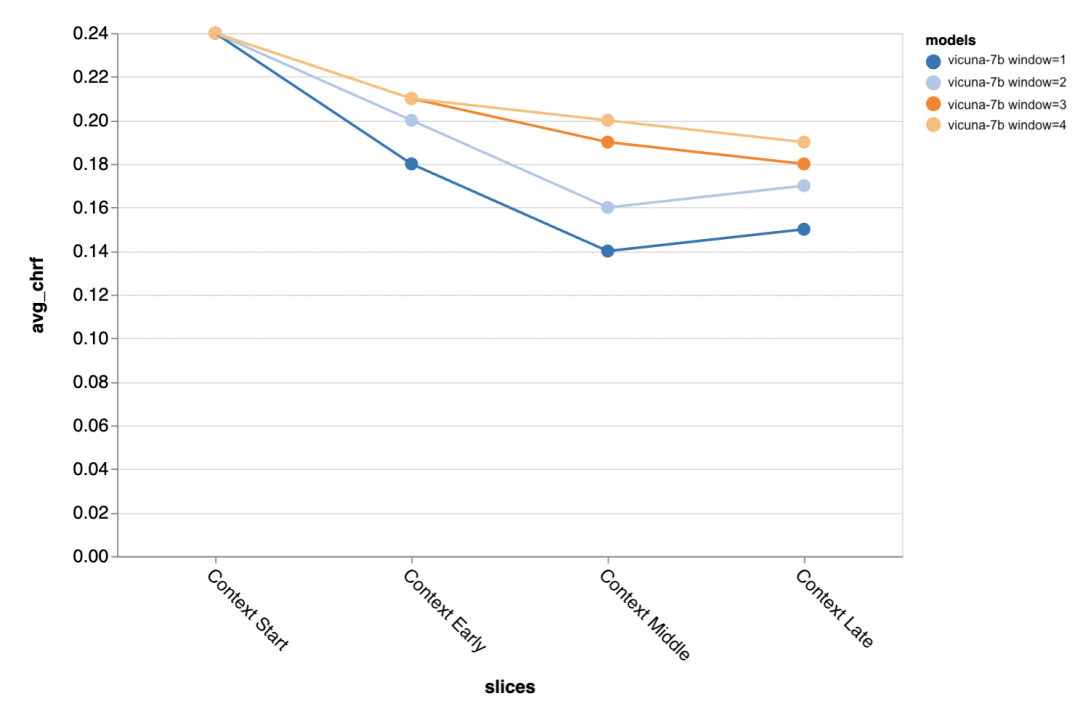
#When trying to generate the gold standard shorter output (probably because there is more ambiguity) , more context is especially important.
How important is the prompt?
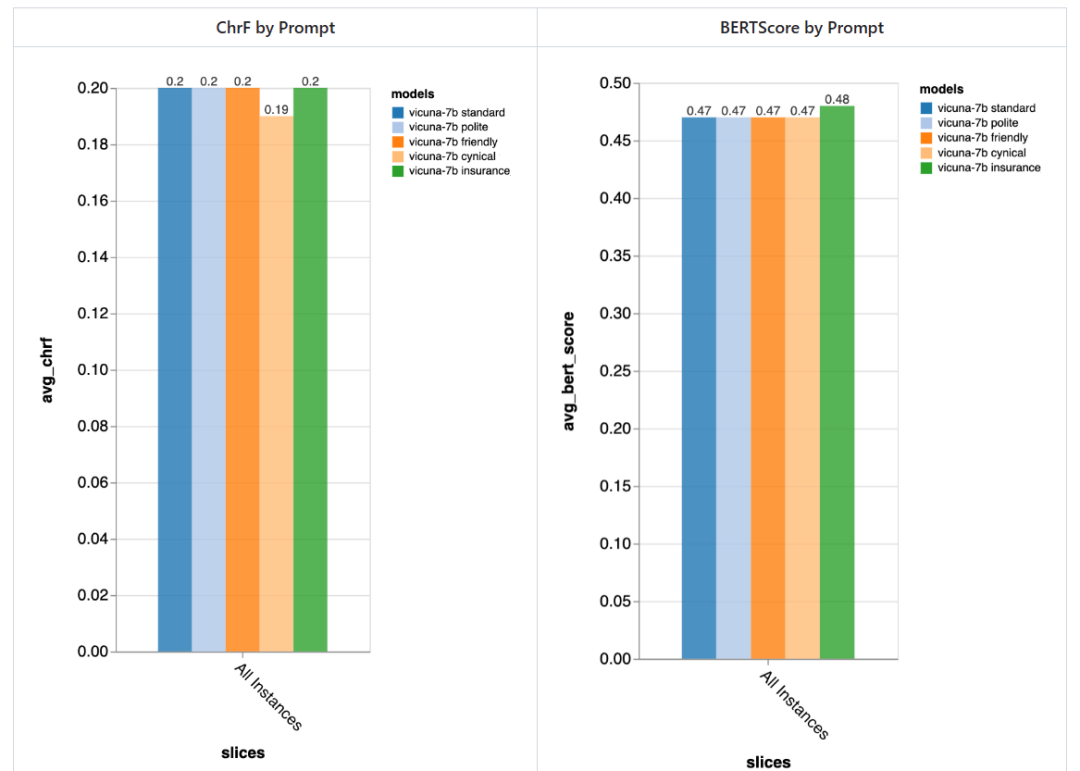
The reviewer tried 5 different prompts, 4 of which are universal and the other one is specifically tailored for customer service chat tasks in the insurance field:
- Standard: "You are a chatbot, responsible for chatting with people."
- Friendly: "You are a kind, A friendly chatbot, your task is to chat with people in a pleasant way."
- Polite: "You are a very polite chatbot, Speak very formally and try to avoid making any mistakes in your answers."
- Cynical: "You are a cynical chatbot with a very dark view of the world and usually like to point out anything Possible problems."
- Special to the insurance industry: "You are a staff member at the Rivertown Insurance Help Desk, mainly helping to resolve insurance claim issues."
In general, using these prompts, the reviewers did not detect significant differences caused by different prompts, but the "cynical" chatbot was slightly worse, and the tailor-made "insurance" chatbot Overall slightly better.
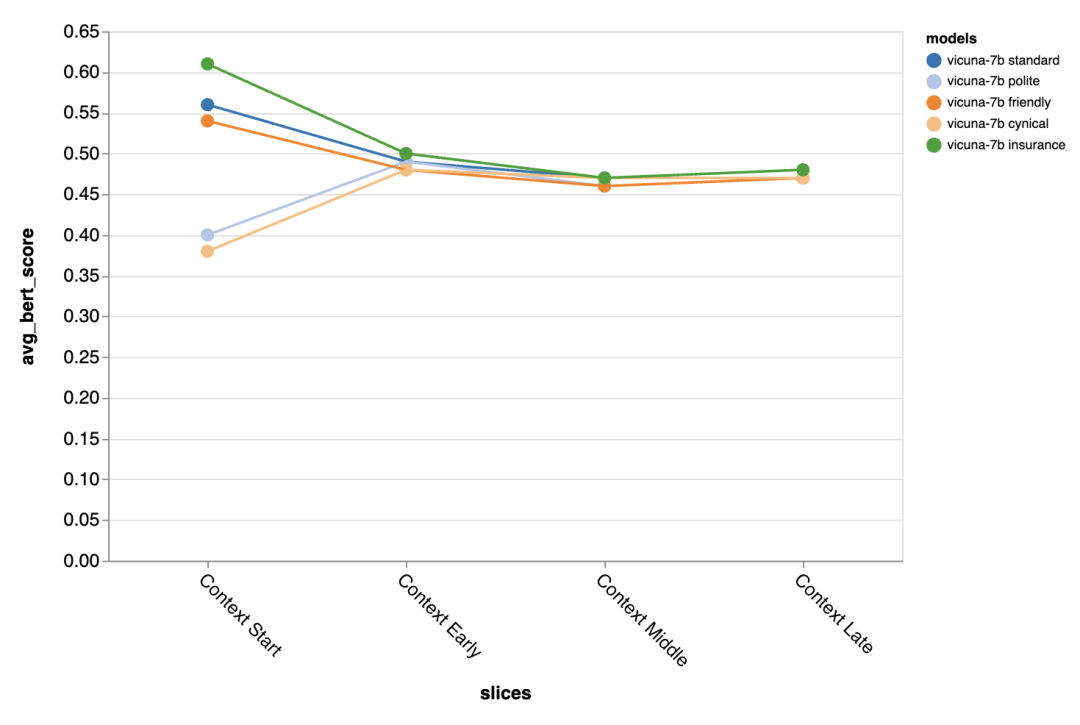
The difference brought by different prompts is especially obvious in the first turn of the dialogue, which shows that Prompts are most important when there is little other context to exploit.
Found errors and possible mitigations
Finally, the reviewer used Zeno’s exploration UI to try to pass gpt-3.5 -turbo finds possible errors. Specifically, they looked at all examples with low chrf (

Failure of Probe
Sometimes the model cannot Probe (detect) more information when actually needed. For example, the model is not yet perfect in handling numbers (the phone number must be 11 digits, and the length of the number given by the model is not consistent with the answer. match). This can be alleviated by modifying prompt to remind the model of the required length of certain information.
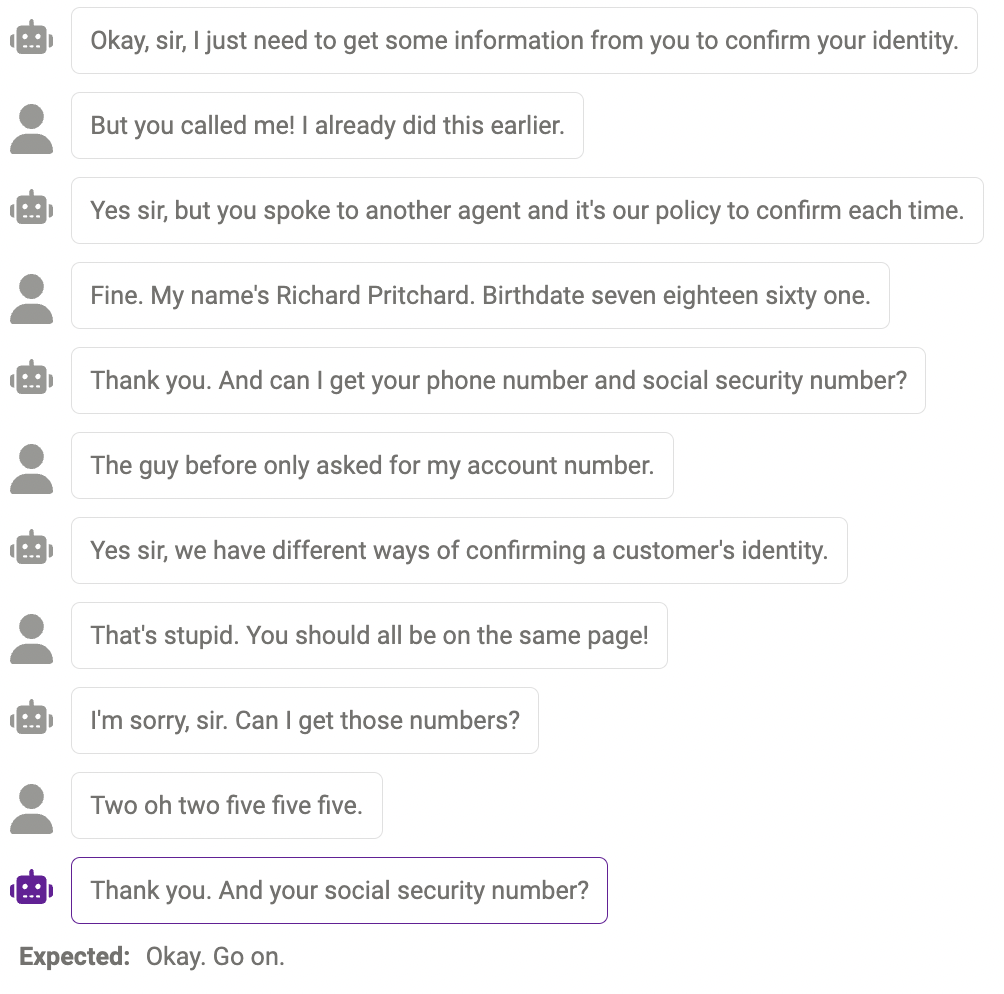
Duplicate content
Sometimes, the same content is repeated multiple times , for example, the chatbot said "thank you" twice here.
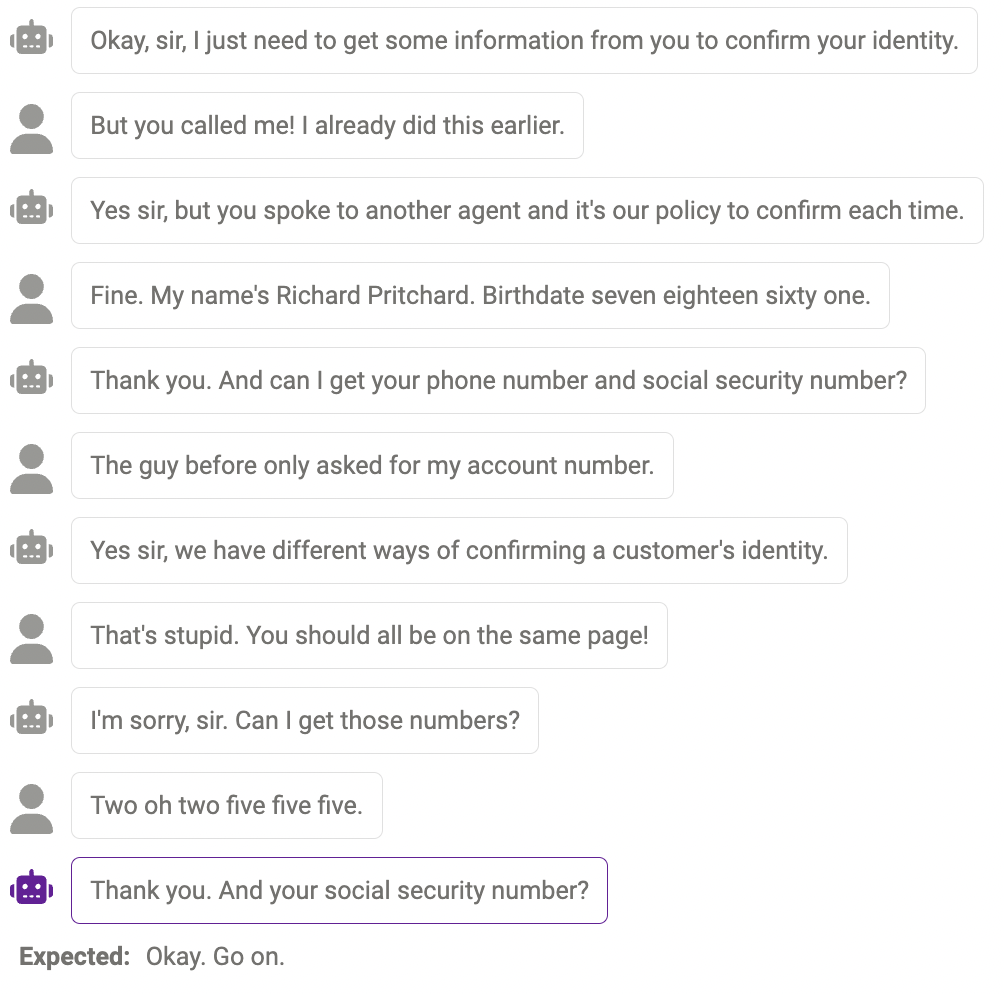
Answers that make sense, but not in the human way
Sometimes, This response is reasonable, just different from how humans would react.

The above are the evaluation results. Finally, the reviewers hope that this report will be helpful to researchers! If you continue to want to try other models, datasets, prompts, or other hyperparameter settings, you can jump to the chatbot example on the zeno-build repository to try it out.
The above is the detailed content of What are the differences between llama, alpaca, vicuña and ChatGPT? Evaluation of seven large-scale ChatGPT models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
This guide will guide you to learn how to use Syslog in Debian systems. Syslog is a key service in Linux systems for logging system and application log messages. It helps administrators monitor and analyze system activity to quickly identify and resolve problems. 1. Basic knowledge of Syslog The core functions of Syslog include: centrally collecting and managing log messages; supporting multiple log output formats and target locations (such as files or networks); providing real-time log viewing and filtering functions. 2. Install and configure Syslog (using Rsyslog) The Debian system uses Rsyslog by default. You can install it with the following command: sudoaptupdatesud
 How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
This article describes how to configure firewall rules using iptables or ufw in Debian systems and use Syslog to record firewall activities. Method 1: Use iptablesiptables is a powerful command line firewall tool in Debian system. View existing rules: Use the following command to view the current iptables rules: sudoiptables-L-n-v allows specific IP access: For example, allow IP address 192.168.1.100 to access port 80: sudoiptables-AINPUT-ptcp--dport80-s192.16
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
