
 Operation and Maintenance
Nginx
How to troubleshoot Nginx service startup failure in Kubernetes
Operation and Maintenance
Nginx
How to troubleshoot Nginx service startup failure in Kubernetes
How to troubleshoot Nginx service startup failure in Kubernetes

❌The pod node failed to start, the nginx service could not be accessed normally, and the service status was displayed as ImagePullBackOff.
[root@m1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-f89759699-cgjgp 0/1 ImagePullBackOff 0 103m
View the Pod node details of the nginx service.
[root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgp
Name: nginx-f89759699-cgjgp
Namespace: default
Priority: 0
Service Account: default
Node: n1/192.168.200.84
Start Time: Fri, 10 Mar 2023 08:40:33 +0800
Labels: app=nginx
pod-template-hash=f89759699
Annotations: <none>
Status: Pending
IP: 10.244.3.20
IPs:
IP: 10.244.3.20
Controlled By: ReplicaSet/nginx-f89759699
Containers:
nginx:
Container ID:
Image: nginx
Image ID:
Port: <none>
Host Port: <none>
State: Waiting
Reason: ImagePullBackOff
Ready: False
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-zk8sj (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
default-token-zk8sj:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-zk8sj
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal BackOff 57m (x179 over 100m) kubelet Back-off pulling image "nginx"
Normal Pulling 7m33s (x22 over 100m) kubelet Pulling image "nginx"
Warning Failed 2m30s (x417 over 100m) kubelet Error: ImagePullBackOff found that obtaining the nginx image failed. It may be caused by Docker service.
So, check whether Docker starts normally
systemctl status docker
Found that the docker service failed to start????, and tried to restart manually.
systemctl restart docker
However, restarting the docker service failed and the following error message appeared.
[root@m1 ~]# systemctl restart docker Job for docker.service failed because the control process exited with error code. See "systemctl status docker.service" and "journalctl -xe" for details.
The execution of the systemctl restart docker command fails.
Then, when executing the docker version command, it was found that it failed to connect to the Docker daemon
[root@m1 ~]# docker version Client: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:03:11 2022 OS/Arch: linux/amd64 Context: default Experimental: true Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
So, again executed the systemctl status docker command , check that the docker service failed to start, and read the output error message, as shown below.
[root@m1 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Fri 2023-03-10 10:28:16 CST; 4min 35s ago
Docs: https://docs.docker.com
Main PID: 2221 (code=exited, status=1/FAILURE)
Mar 10 10:28:13 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILURE
Mar 10 10:28:13 m1 systemd[1]: docker.service: Failed with result 'exit-code'.
Mar 10 10:28:13 m1 systemd[1]: Failed to start Docker Application Container Engine.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 3.
Mar 10 10:28:16 m1 systemd[1]: Stopped Docker Application Container Engine.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Start request repeated too quickly.
Mar 10 10:28:16 m1 systemd[1]: docker.service: Failed with result 'exit-code'.
Mar 10 10:28:16 m1 systemd[1]: Failed to start Docker Application Container Engine.
[root@m1 ~]#The above output shows that the startup of the Docker service process failed and the status is 1/FAILURE.
✅Next, try the following steps to troubleshoot and resolve the issue:
1️⃣View the Docker service log: Use the following command to view the Docker service log to understand the cause of the failure in more detail.
sudo journalctl -u docker.service
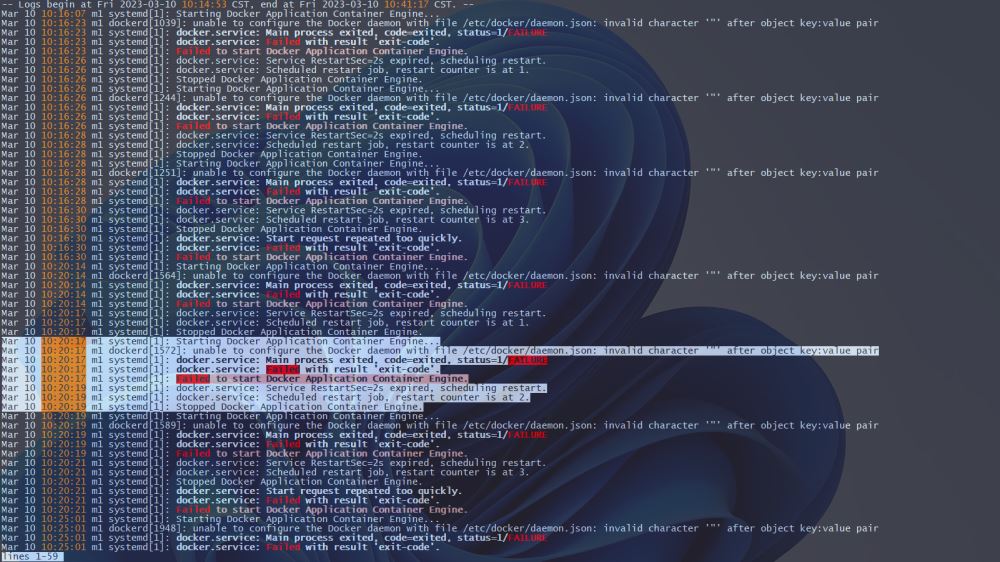
2️⃣ By outputting Ddocker log analysis, we extracted the relevant error message fragments and found that it was /etc/docker/daemon.json in the daemon configuration. Caused by an error in the configuration file.
Mar 10 10:20:17 m1 systemd[1]: Starting Docker Application Container Engine... Mar 10 10:20:17 m1 dockerd[1572]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character '"' after object key:value pair Mar 10 10:20:17 m1 systemd[1]: docker.service: Main process exited, code=exited, status=1/FAILURE Mar 10 10:20:17 m1 systemd[1]: docker.service: Failed with result 'exit-code'. Mar 10 10:20:17 m1 systemd[1]: Failed to start Docker Application Container Engine. Mar 10 10:20:19 m1 systemd[1]: docker.service: Service RestartSec=2s expired, scheduling restart. Mar 10 10:20:19 m1 systemd[1]: docker.service: Scheduled restart job, restart counter is at 2. Mar 10 10:20:19 m1 systemd[1]: Stopped Docker Application Container Engine.
3️⃣At this point, check whether the daemon configuration file /etc/docker/daemon.json is configured correctly.
[root@m1 ~]# cat /etc/docker/daemon.json
{
# 设置 Docker 镜像的注册表镜像源为阿里云镜像源。
"registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"]
# 指定 Docker 守护进程使用 systemd 作为 cgroup driver。
"exec-opts": ["native.cgroupdriver=systemd"]
}At first glance, there is nothing wrong with the configuration information and it is all correct, but if you look closely, you will find that a comma should be added at the end of the "registry-mirrors" option. I made a grammatical error caused by missing commas (,), and finally found the source of the problem.
After modification:
[root@m1 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
[root@m1 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://w2kavmmf.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}Press: wq to exit with an error.
4️⃣ Reload the system and restart the Docker service
systemctl daemon-reload systemctl restart docker systemctl status docker
5️⃣ Check whether the docker version information is output normally
[root@m1 ~]# docket version -bash: docket: command not found [root@m1 ~]# docker version Client: Docker Engine - Community Version: 20.10.17 API version: 1.41 Go version: go1.17.11 Git commit: 100c701 Built: Mon Jun 6 23:03:11 2022 OS/Arch: linux/amd64 Context: default Experimental: true Server: Docker Engine - Community Engine: Version: 20.10.17 API version: 1.41 (minimum version 1.12) Go version: go1.17.11 Git commit: a89b842 Built: Mon Jun 6 23:01:29 2022 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.6.6 GitCommit: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 runc: Version: 1.1.2 GitCommit: v1.1.2-0-ga916309 docker-init: Version: 0.19.0 GitCommit: de40ad0
[root@m1 ~]# docker info Client: Context: default Debug Mode: false Plugins: app: Docker App (Docker Inc., v0.9.1-beta3) buildx: Docker Buildx (Docker Inc., v0.8.2-docker) scan: Docker Scan (Docker Inc., v0.17.0) Server: Containers: 20 Running: 8 Paused: 0 Stopped: 12 Images: 20 Server Version: 20.10.17 Storage Driver: overlay2 Backing Filesystem: xfs Supports d_type: true Native Overlay Diff: true userxattr: false Logging Driver: json-file Cgroup Driver: systemd Cgroup Version: 1 Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog Swarm: inactive Runtimes: io.containerd.runc.v2 io.containerd.runtime.v1.linux runc Default Runtime: runc Init Binary: docker-init containerd version: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 runc version: v1.1.2-0-ga916309 init version: de40ad0 Security Options: seccomp Profile: default Kernel Version: 4.18.0-372.9.1.el8.x86_64 Operating System: Rocky Linux 8.6 (Green Obsidian) OSType: linux Architecture: x86_64 CPUs: 2 Total Memory: 9.711GiB Name: m1 ID: 4YIS:FHSB:YXRI:CED5:PJSJ:EAS2:BCR3:GJJF:FDPK:EDJH:DVKU:AIYJ Docker Root Dir: /var/lib/docker Debug Mode: false Registry: https://index.docker.io/v1/ Labels: Experimental: false Insecure Registries: 127.0.0.0/8 Registry Mirrors: https://w2kavmmf.mirror.aliyuncs.com/ Live Restore Enabled: false
At this point, the Docker service restarts successfully, the pod node returns to normal, and Nginx The service can be accessed normally.
[root@m1 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE nginx-f89759699-cgjgp 1/1 Running 0 174m
Check the pod details and the display is normal.
[root@m1 ~]# kubectl describe pod nginx-f89759699-cgjgp
Name: nginx-f89759699-cgjgp
Namespace: default
Priority: 0
Service Account: default
Node: n1/192.168.200.84
Start Time: Fri, 10 Mar 2023 08:40:33 +0800
Labels: app=nginx
pod-template-hash=f89759699
Annotations: <none>
Status: Running
IP: 10.244.3.20
IPs:
IP: 10.244.3.20
Controlled By: ReplicaSet/nginx-f89759699
Containers:
nginx:
Container ID: docker://88bdc2bfa592f60bf99bac2125b0adae005118ae8f2f271225245f20b7cfb3c8
Image: nginx
Image ID: docker-pullable://nginx@sha256:aa0afebbb3cfa473099a62c4b32e9b3fb73ed23f2a75a65ce1d4b4f55a5c2ef2
Port: <none>
Host Port: <none>
State: Running
Started: Fri, 10 Mar 2023 10:37:42 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-zk8sj (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-zk8sj:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-zk8sj
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal BackOff 58m (x480 over 171m) kubelet Back-off pulling image "nginx"
[root@m1 ~]#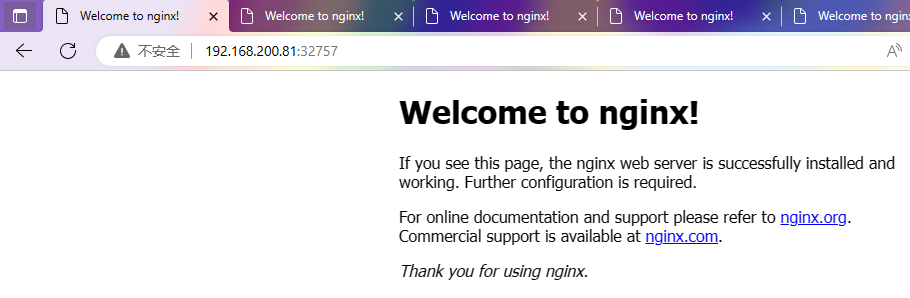
The above is the detailed content of How to troubleshoot Nginx service startup failure in Kubernetes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to configure cloud server domain name in nginx
Apr 14, 2025 pm 12:18 PM
How to configure cloud server domain name in nginx
Apr 14, 2025 pm 12:18 PM
How to configure an Nginx domain name on a cloud server: Create an A record pointing to the public IP address of the cloud server. Add virtual host blocks in the Nginx configuration file, specifying the listening port, domain name, and website root directory. Restart Nginx to apply the changes. Access the domain name test configuration. Other notes: Install the SSL certificate to enable HTTPS, ensure that the firewall allows port 80 traffic, and wait for DNS resolution to take effect.
 How to check whether nginx is started
Apr 14, 2025 pm 01:03 PM
How to check whether nginx is started
Apr 14, 2025 pm 01:03 PM
How to confirm whether Nginx is started: 1. Use the command line: systemctl status nginx (Linux/Unix), netstat -ano | findstr 80 (Windows); 2. Check whether port 80 is open; 3. Check the Nginx startup message in the system log; 4. Use third-party tools, such as Nagios, Zabbix, and Icinga.
 How to create a mirror in docker
Apr 15, 2025 am 11:27 AM
How to create a mirror in docker
Apr 15, 2025 am 11:27 AM
Steps to create a Docker image: Write a Dockerfile that contains the build instructions. Build the image in the terminal, using the docker build command. Tag the image and assign names and tags using the docker tag command.
 How to check nginx version
Apr 14, 2025 am 11:57 AM
How to check nginx version
Apr 14, 2025 am 11:57 AM
The methods that can query the Nginx version are: use the nginx -v command; view the version directive in the nginx.conf file; open the Nginx error page and view the page title.
 How to start nginx server
Apr 14, 2025 pm 12:27 PM
How to start nginx server
Apr 14, 2025 pm 12:27 PM
Starting an Nginx server requires different steps according to different operating systems: Linux/Unix system: Install the Nginx package (for example, using apt-get or yum). Use systemctl to start an Nginx service (for example, sudo systemctl start nginx). Windows system: Download and install Windows binary files. Start Nginx using the nginx.exe executable (for example, nginx.exe -c conf\nginx.conf). No matter which operating system you use, you can access the server IP
 How to check whether nginx is started?
Apr 14, 2025 pm 12:48 PM
How to check whether nginx is started?
Apr 14, 2025 pm 12:48 PM
In Linux, use the following command to check whether Nginx is started: systemctl status nginx judges based on the command output: If "Active: active (running)" is displayed, Nginx is started. If "Active: inactive (dead)" is displayed, Nginx is stopped.
 How to start nginx in Linux
Apr 14, 2025 pm 12:51 PM
How to start nginx in Linux
Apr 14, 2025 pm 12:51 PM
Steps to start Nginx in Linux: Check whether Nginx is installed. Use systemctl start nginx to start the Nginx service. Use systemctl enable nginx to enable automatic startup of Nginx at system startup. Use systemctl status nginx to verify that the startup is successful. Visit http://localhost in a web browser to view the default welcome page.
 How to solve nginx403
Apr 14, 2025 am 10:33 AM
How to solve nginx403
Apr 14, 2025 am 10:33 AM
How to fix Nginx 403 Forbidden error? Check file or directory permissions; 2. Check .htaccess file; 3. Check Nginx configuration file; 4. Restart Nginx. Other possible causes include firewall rules, SELinux settings, or application issues.
