

smarty中英文多编码字符截取乱码问题解决方法

本文实例讲述了smarty中英文多编码字符截取乱码问题解决方法,分享给大家供大家参考。具体方法如下:
一般网站页面的显示都不可避免的会涉及子字符串的截取,这个时候truncate就派上用场了,但是它只适合英文用户,对与中文用户来说,使用 truncate会出现乱码,而且对于中文英文混合串来说,截取同样个数的字符串,实际显示长度上却不同,视觉上会显得参差不齐,影响美观。这是因为一个中文的长度大致相当于两个英文的长度。此外,truncate也不能同时兼容GB2312, UTF-8等编码。
改良的smartTruncate: 文件名:modifier.smartTruncate.php
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
|
以上代码完整实现了truncate的原有功能,而且可以同时兼容GB2312和UTF-8编码,在判断字符长度的时候,一个中文字符算1.0,一个英文字符算0.5,所以在截取子字符串的时候不会出现参差不齐的情况.
插件的使用方式没有特别之处,这里简单测试一下:
代码如下:
1 |
|
显示:A中B华C.. (中文符号长度算1.0,英文符号长度算0.5,并且考虑省略符号的长度)
不管你是使用GB2312编码还是UTF-8编码,你会发现结果都正确,这也是为什么我在插件名字里加上smart字样的原因之一。
希望本文所述对大家的PHP程序设计有所帮助。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1374
1374
 52
52

 Use java's Character.isDigit() function to determine whether a character is a number
Jul 27, 2023 am 09:32 AM
Use java's Character.isDigit() function to determine whether a character is a number
Jul 27, 2023 am 09:32 AM
Use Java's Character.isDigit() function to determine whether a character is a numeric character. Characters are represented in the form of ASCII codes internally in the computer. Each character has a corresponding ASCII code. Among them, the ASCII code values corresponding to the numeric characters 0 to 9 are 48 to 57 respectively. To determine whether a character is a number, you can use the isDigit() method provided by the Character class in Java. The isDigit() method is of the Character class
 How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to type arrows in Word
Apr 16, 2023 pm 11:37 PM
How to use AutoCorrect to type arrows in Word One of the fastest ways to type arrows in Word is to use the predefined AutoCorrect shortcuts. If you type a specific sequence of characters, Word automatically converts those characters into arrow symbols. You can draw many different arrow styles using this method. To type an arrow in Word using AutoCorrect: Move your cursor to the location in the document where you want the arrow to appear. Type one of the following character combinations: If you don't want what you type to be corrected to an arrow symbol, press the backspace key on your keyboard to
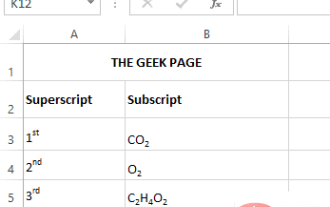 How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
How to apply superscript and subscript formatting options in Microsoft Excel
Apr 14, 2023 pm 12:07 PM
A superscript is a character or characters, either letters or numbers, that you need to set slightly above the normal line of text. For example, if you need to write 1st, the letter st needs to be slightly higher than the character 1. Likewise, a subscript is a group of characters or a single character and needs to be set slightly lower than normal text level. For example, when you write a chemical formula, you need to place the numbers below the normal line of characters. The following screenshots show some examples of superscript and subscript formatting. Although it may seem like a daunting task, applying superscript and subscript formatting to your text is actually quite simple. In this article, we will explain in some simple steps how to easily format text using superscript or subscript. Hope you enjoyed reading this article. How to apply superscript in Excel
 How do you enter extended characters, such as the degree symbol, on iPhone and Mac?
Apr 22, 2023 pm 02:01 PM
How do you enter extended characters, such as the degree symbol, on iPhone and Mac?
Apr 22, 2023 pm 02:01 PM
Your physical or numeric keyboard provides a limited number of character options on the surface. However, there are several ways to access accented letters, special characters, and more on iPhone, iPad, and Mac. The standard iOS keyboard gives you quick access to uppercase and lowercase letters, standard numbers, punctuation, and characters. Of course, there are many other characters. You can choose from letters with diacritics to upside-down question marks. You may have stumbled upon a hidden special character. If not, here's how to access them on iPhone, iPad, and Mac. How to Access Extended Characters on iPhone and iPad Getting extended characters on your iPhone or iPad is very simple. In "Information", "
 Correct way to display Chinese characters in matplotlib
Jan 13, 2024 am 11:03 AM
Correct way to display Chinese characters in matplotlib
Jan 13, 2024 am 11:03 AM
Correctly displaying Chinese characters in matplotlib is a problem often encountered by many Chinese users. By default, matplotlib uses English fonts and cannot display Chinese characters correctly. To solve this problem, we need to set the correct Chinese font and apply it to matplotlib. Below are some specific code examples to help you display Chinese characters correctly in matplotlib. First, we need to import the required libraries: importmatplot
 How to use Golang to determine whether a character is a letter
Dec 23, 2023 am 11:57 AM
How to use Golang to determine whether a character is a letter
Dec 23, 2023 am 11:57 AM
How to use Golang to determine whether a character is a letter. In Golang, determining whether a character is a letter can be achieved by using the IsLetter function in the Unicode package. The IsLetter function checks whether the given character is a letter. Next, we will introduce in detail how to use Golang to write code to determine whether a character is a letter. First, you need to create a new Go file in which to write the code. You can name the file "main.go". code
 Regarding the character representation of the Enter key in Java, which one is it?
Mar 29, 2024 am 11:48 AM
Regarding the character representation of the Enter key in Java, which one is it?
Mar 29, 2024 am 11:48 AM
The character representation of the Enter key in Java is `. In Java, ` represents a newline character, and when this character is encountered, the text output will wrap. Here is a simple code example that demonstrates how to use `` to represent the Enter key: publicclassMain{publicstaticvoidmain(String[]args){System.out.println("This is the first line of this
 Detailed explanation of string interception method in Go language
Mar 13, 2024 am 08:03 AM
Detailed explanation of string interception method in Go language
Mar 13, 2024 am 08:03 AM
Detailed explanation of string interception methods in Go language. In Go language, strings are immutable byte sequences, so some methods need to be used to implement string interception. String interception is a common operation to obtain a specific part of a string. You can intercept the first few characters, the last few characters of the string, or a certain length of characters from a specific position according to your needs. This article will introduce in detail how to intercept strings in Go language and provide specific code examples. Using slicing to implement string interception In Go language, you can use slicing to
