
 Technology peripherals
AI
13948 questions, covering 52 subjects such as calculus and line generation, were submitted to Tsinghua University to make a test set for the Chinese large model
Technology peripherals
AI
13948 questions, covering 52 subjects such as calculus and line generation, were submitted to Tsinghua University to make a test set for the Chinese large model
13948 questions, covering 52 subjects such as calculus and line generation, were submitted to Tsinghua University to make a test set for the Chinese large model

The emergence of ChatGPT has made the Chinese community aware of the gap with the international leading level. Recently, the development of Chinese large models has been in full swing, but there are few Chinese evaluation benchmarks.
In the development process of the OpenAI GPT series/Google PaLM series/DeepMind Chinchilla series/Anthropic Claude series, the three data sets of MMLU/MATH/BBH played a crucial role , because they relatively comprehensively cover the capabilities of each dimension of the model. The most noteworthy is the MMLU data set, which considers the comprehensive knowledge capabilities of 57 disciplines, from humanities to social sciences to science and engineering. DeepMind's Gopher and Chinchilla models only look at MMLU scores, so we want to construct a Chinese, sufficiently differentiated, multi-disciplinary benchmark list to assist developers in developing large Chinese models.
We spent about three months constructing a system covering four major directions: humanities, social sciences, science and engineering, and other majors, and 52 subjects (calculus, line generation... ), a Chinese knowledge and reasoning test set with a total of 13,948 questions from middle schools to university postgraduates and vocational examinations. We call it C-Eval to help the Chinese community develop large models.
This article is to record our process of constructing C-Eval and share with developers our thinking and R&D priorities from our perspective. Our most important goal is to assist model development, not to win rankings. Blindly pursuing a high ranking on the list will bring many adverse consequences, but if C-Eval can be used scientifically to help model iteration, C-Eval can be maximized. Therefore, we recommend to treat the C-Eval data set and list from the perspective of model development.
- ## Website: https://cevalbenchmark.com/
- Github: https://github.com/SJTU-LIT/ceval
- Paper: https://arxiv.org/abs/2305.08322

First, turn a model into a conversational robot Things are not difficult. There are already conversational robots like Alpaca, Vicuna, and RWKV in the open source world. It feels good to chat with them casually. But if you really want these models to become productive, casual chatting is not enough. Therefore, the first problem in constructing an evaluation benchmark is to find the degree of differentiation and figure out what kind of ability is the core indicator that distinguishes the strength of a model. We consider the two cores of Knowledge and Reasoning.
1.1 - Knowledge
Why is intellectual ability the core ability? There are several arguments as follows:
- # We hope that the model can be universal and contribute productivity in different fields, which naturally requires the model to know the knowledge in various fields.
- We also hope that the model will not talk nonsense and do not know what it is. This also requires expanding the knowledge of the model so that it can say that it does not know less often.
- In Stanford's HELM English evaluation list, an important conclusion is that the size of the model is significantly positively correlated with the effect of knowledge-intensive tasks. This is because the number of parameters of the model can be used to store knowledge.
- As mentioned above, existing important models, such as DeepMind’s Gopher/Chinchilla, almost only look at MMLU when evaluating. The core of MMLU is the knowledge coverage of the test model.
- In the release blog of GPT-4, the first thing is to list the performance of the model on various subject examinations as a measure of the model's ability.
Therefore, knowledge-based capabilities are a good measure of the potential of the base model.
1.2 - Reasoning
# Reasoning ability is the ability to further improve on the basis of knowledge. It represents whether the model can be made difficult. Very complicated thing. For a model to be strong, it first needs extensive knowledge, and then makes inferences based on the knowledge.
The reasoning is very important:
- In the release blog of GPT-4, OpenAI clearly wrote "The difference comes out when the complexity of the task reaches a sufficient threshold” (the difference between GPT-3.5 and GPT-4 will only become apparent after the task complexity reaches a certain level). This shows that strong models have significant inference capabilities, while weaker models do not have much ability.
- In the Tech Report of PaLM-2, the two inference data sets BBH and MATH are specially listed for discussion and focus.
- If you want the model to become a new generation of computing platform and breed a new application ecosystem on it, you need to make the model strong enough to complete complex tasks.
Here we also need to clarify the relationship between reasoning and knowledge:
- Knowledge-based capabilities are the basis of model capabilities , the reasoning ability is a further sublimation - the model needs to reason based on the existing knowledge graph.
- On the list of knowledge-based tasks, the model size and model score generally change continuously, and it is unlikely that there will be a cliff-like decline just because the model is small - from this perspective, knowledge-based tasks The tasks are a little more differentiated.
- On the list of inference tasks, there may be a phase change between the model size and the model score. Only when the model is large to a certain extent (probably 50B and up, that is, LLaMA 65B) magnitude), the model reasoning ability will improve.
- For knowledge-based tasks, the effects of Chain-of-thought (CoT) prompting and Answer-only (AO) prompting are similar; for reasoning tasks, CoT is significantly better Yu AO.
- So here you need to remember that CoT only adds reasoning effects but not knowledge effects. We also observed this phenomenon in the C-Eval dataset.
2 - The goal of C-Eval
With the above explanation of knowledge and reasoning, we decided to construct a data set starting from knowledge-based tasks Testing the knowledge capability of the model is equivalent to benchmarking the MMLU data set; at the same time, we also hope to bring some reasoning-related content to further measure the high-order capabilities of the model, so we include subjects that require strong reasoning in C-Eval (micro Integral, linear algebra, probability...) are specially extracted and named C-Eval Hard subset, which is used to measure the reasoning ability of the model, which is equivalent to benchmarking the MATH data set.
On C-Eval Hard, the model first needs to have mathematics-related knowledge, and then needs to have a step-by-step idea of solving the problem, and then needs to call Wolfram Alpha/Mathematica/Matlab during the problem-solving process The ability to perform numerical and symbolic/differential and integral calculations, and express the calculation process and results in Latex format. This part of the question is very difficult.
C-Eval hopes to benchmark MMLU as a whole (this data set is used for the development of GPT-3.5, GPT-4, PaLM, PaLM-2, Gopher, Chinchilla) , hoping to benchmark MATH on the Hard part (this data set is used in the development of GPT-4, PaLM-2, Minerva, and Galactica).
It should be noted here that our most important goal is toassist model development, not to list. Blindly pursuing a high ranking on the list will bring many adverse consequences, which we will explain shortly; but if you can use C-Eval scientifically to help model iteration, you will get huge benefits. We recommend to treat the C-Eval data set and list from the perspective of model development.
2.1 - The goal is to assist model development
In the actual research and development process, Many times we need to know the quality of a certain solution or the quality of a certain model. At this time we need a data set to help us test. The following are two classic scenes:
- Scenario 1, auxiliary hyperparameter search: We have multiple pre-training data mixing schemes, and we are not sure which one is more suitable. Okay, so we compare each other on C-Eval to determine the optimal pre-training data mixing scheme.
- Scenario 2, comparing the training phase of the model: I have a pre-trained checkpoint and an instruction-tuned checkpoint, and then I If I want to measure the effectiveness of my instruction-tuning, I can compare the two checkpoints with each other on C-Eval to measure the relative quality of pre-training and instruction-tuning.
2.2 - Ranking is not the goal
We need to emphasize why ranking should not be based on charts As a goal:
- # If you take ranking as the goal, it will be easy to overfit the list for high scores, but lose versatility - this is the NLP academic before GPT-3.5 The world learned an important lesson on finetune Bert.
- The list itself only measures the potential of the model, not the real user experience - if the model is really liked by users, it still requires a lot of manual evaluation
- If the goal is ranking, it is easy to take shortcuts for high scores and lose the quality and spirit of solid scientific research.
Therefore, if C-Eval is used as an auxiliary development tool, its positive role can be maximized; but if it is used as a list ranking, There is a huge risk of misuse of C-Eval, and there is a high probability that there will be no good results in the end.
So once again, we recommend to treat the C-Eval data set and list from the perspective of model development.
2.3 - Continuously iterate from developer feedback
because we want the model to be as efficient as possible Support developers, so we choose to communicate directly with developers and continue to learn and iterate from developers’ feedback - this also allows us to learn a lot; just like the big model is Reinforcement Learning from Human Feedback, C-Eval’s development team is Continue Learning from Developers' Feedback.
Specifically, during the research and development process, we invited companies such as ByteDance, SenseTime, and Shenyan to connect C-Eval Do testing in their own workflows, and then communicate with each other about the challenging points in the testing process. This process allowed us to learn a lot that we didn’t expect at the beginning:
- Many testing teams, even in the same company, have no way of knowing any relevant information about the model being tested. (Black box testing), we don’t even know whether this model has gone through instruction-tuning, so we need to support both in-context learning and zero-shot prompting.
- Because some models are black For box testing, there is no way to get logits, but without logits for a small model, it is more difficult to determine the answer, so we need to determine a solution for determining the answer with a small model.
- There are many model test models, such as in-context learning and zero-shot prompting; there are many prompt formats, such as answer-only and chain-of-thought; model There are many types of checkpoints, such as pretrained checkpoint and instruction-finetuned checkpoint, so we need to understand the respective impacts and interactions of these factors.
- The model is very sensitive to prompt, whether prompt engineering is needed, and whether prompt engineering hinders fairness.
- What should GPT-3.5 / GPT-4 / Claude / PaLM prompt engineering do, and then learn from their experience.
#The above issues were discovered through feedback from developers during our interactions with them. These problems have been solved in the documentation and github code of the current public version of C-Eval.
The above processes also prove that treating the C-Eval data set and list from the perspective of model development can very well help everyone develop Chinese large models.
We welcome all developers to submit issues and pull requests to our GitHub and let us know how to better help you. We hope to help you better:)
3 - How to ensure quality
In this chapter we discuss the methods we use to ensure the quality of the data set during the production process. Our most important references here are the two data sets MMLU and MATH. Because the four most important large model teams, OpenAI, Google, DeepMind, and Anthropic, all focus on MMLU and MATH, so we hope to be able to contribute to these two data sets. Set in line. After our preliminary research and a series of discussions, we made two important decisions, one was to manufacture the dataset from scratch, and the other was to Key pointsPrevent questions from being crawled into the training set by crawlers.
3.1 - Handmade
An important inspiration from the development process of GPT is that in the field of artificial intelligence, there are There is as much intelligence as there is artificial intelligence. This is also well reflected in the process of establishing C-Eval. Specifically, from the source of the question:
- C-Eval Most of the questions inside are derived from pdf and word format files. Such questions require additional processing and (manual) cleaning before they can be used. This is because there are too many various questions on the Internet. Questions that exist directly in the form of web page text are likely to have been used in the pre-training of the model
Then there are processing questions:
- After collecting the questions, first do OCR to digitize the pdf file, and then unify the format into Markdown, and the mathematical part is unified in Latex format
- Processing formulas is a troublesome thing: first, OCR may not be able to recognize it correctly, and then OCR cannot directly recognize it as Latex; our approach here is to automatically convert it to Latex if it can, but not It was automatically transferred to students who manually typed
- . The final result was that all symbol-related content (including mathematical formulas and chemical formulas, such as H2O) in more than 13,000 questions were solved by us. The students in the project team have verified it one by one. About a dozen of our students spent nearly two weeks doing this
- So now our questions can be written in markdown very beautifully Presented in the form, here we give an example of calculus. This example can be seen directly in the explore section of our website:

- The next difficulty is how to construct the official chain-of-thought prompt. The key point here is that we need to ensure that our CoT is correct. Our initial approach was to let GPT-4 generate a Chain-of-thought for each in-context example, but later we found that this was not feasible. First, the generated one was too long (more than 2048 tokens). The input length of some models may not be supported; the other is that the error rate is too high. It is better to check each one by yourself
- So our students generated CoT based on GPT-4 , I really did it myself by taking prompt questions such as calculus, line generation, probability, and discreteness (5 questions for each subject as in-context examples). The following is an example:

The left side is made by the students themselves, and then written in Markdown - Latex format; the right side is the rendered effect
You can also feel why the questions are difficult, the chain-of-thought prompt is very long, and why the model needs to be able to do symbolic and numerical calculations of calculus
3.2 - Preventing our questions from being mixed into the training set
#For the sake of scientific evaluation, we have considered a series of mechanisms to prevent our questions from being mixed into the training set
- First of all, our test set only discloses the questions but not the answers. You can use your own model to run the answers locally and submit them on the website, and then the score will be given in the background
- Then, all the questions in C-Eval are mock questions. We have never used any real questions from middle school to postgraduate entrance examinations to vocational exams. This is because the real questions of national examinations are widely available online and are very easy. Being crawled into the model training set
Of course, despite our efforts, it may inevitably happen that the question bank can be searched on a certain web page topic, but we believe this situation should be rare. And judging from the results we have, the C-Eval questions are still sufficiently differentiated, especially the Hard part.
4 - Methods to improve ranking
Next we analyze what methods can be used to improve the ranking of the model. We first list the shortcuts for everyone, including using LLaMA, which is not commercially available, and using data generated by GPT, as well as the disadvantages of these methods; then we discuss what is the difficult but correct path .
4.1 - What shortcuts can be taken?
Here are the shortcuts you can take:
- Use LLaMA as the base model: In our other related English model evaluation project Chain-of-thought Hub, we pointed out that the 65B LLaMA model is a slightly weaker basic model than GPT-3.5. It has great potential. If it is trained with Chinese data, its strong English capabilities can be automatically transferred to Chinese.
- But the disadvantage of doing this, is that the upper limit of R&D capabilities is locked by LLaMA 65B, no It may exceed GPT-3.5, let alone GPT-4. On the other hand, LLaMA is not commercially available. Using it for commercial purposes will directly violate the regulations.
- Generated using GPT-4 Data: Especially the C-Eval Hard part, just let GPT-4 do it again, and then feed the GPT-4 answer to your own model
- But the disadvantages of doing this are: first, it is naked cheating, and the results obtained cannot be generalized and cannot represent the true capabilities of the model; second, if it is commercialized, it directly violates OpenAI's usage regulations; third, Distillation from GPT-4 will aggravate the phenomenon of model nonsense. This is because RLHF encourages the model to know what it knows when fine-tuning the model's rejection ability. I don’t know because I don’t know; but if you directly copy GPT-4, other models may not necessarily know what GPT-4 knows, which will encourage the models to talk nonsense. This phenomenon was highlighted in a recent talk by John Schulman in Berkeley.
# Many times, what seems like a shortcut actually has a price tag on it secretly.
4.2 - Difficult but correct path
The best way is to be self-reliant and self-reliant , developed from scratch. This thing is difficult, takes time, and requires patience, but it is the right way.
Specifically, we need to focus on papers from the following institutions
- OpenAI - There is no doubt about this, all articles must be memorized in full
- Anthropic - What OpenAI won’t tell you, Anthropic will tell you
- Google DeepMind - Google is more of a scapegoat. It tells you all the technologies honestly, unlike OpenAI which hides and hides things. article. Develop your judgment first before reading articles elsewhere so you can distinguish good from bad. In academics, it is important to distinguish between good and bad rather than just accepting without judgment.
In the process of research and development, it is recommended to pay attention to the following content:
- How to group pretraining data, such as DoReMi’s method
- How to increase the stability of pretraining, such as BLOOM’s method
- How to group instruction tuning data, such as The Flan Collection
- How to do instruction tuning, such as Self-instruct
- How to do it RL, such as Constitutional AI
- How to increase reasoning capabilities, such as our previous blog
- How to increase coding capabilities, such as StarCoder
- How to increase the ability to use tools (C-Eval Hard requires the model to be able to call tools for scientific calculations), such as toolformer
4.3 - Don’t rush
Large model is a time-consuming thing. It is a comprehensive test of artificial intelligence industrial capabilities:
- OpenAI’s GPT series took a total of four years from GPT-3 to GPT-4, from 2019 to 2023.
- After the original team of Anthropic was separated from OpenAI, even with the experience of GPT-3, it took a year to redo Claude.
- LLaMA’s team, even with the lessons of OPT and BLOOM, took six months.
- GLM-130B took two years from project establishment to release.
- The alignment part of MOSS, the content before RL, also took nearly half a year, and this still does not include RL.
Therefore, there is no need to rush to the rankings, no need to see the results tomorrow, no need to go online the day after tomorrow - take your time, step by step. Many times, the difficult but correct path is actually the fastest path.
5 - Conclusion
In this article, we introduced the development goals, process, and key considerations of C-Eval. Our goal is to help developers better develop Chinese large models and promote the scientific use of C-Eval in academia and industry to help model iteration. We are not in a hurry to see the results, because large models themselves are a very difficult thing. We know the shortcuts we can take, but we also know that the difficult but correct path is actually the fastest path. We hope that this work can promote the research and development ecology of Chinese large models and allow people to experience the convenience brought by this technology earlier.
Appendix 1: Subjects included in C-Eval
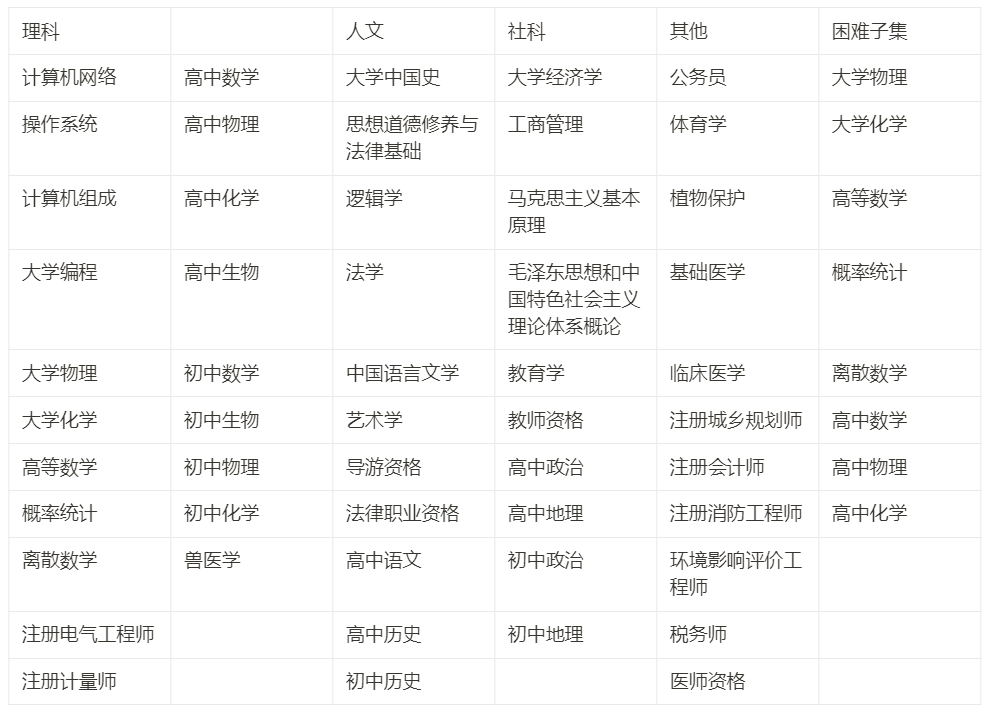
Appendix 2: Contributions of project members

##Note: In the text The corresponding URL of the mentioned paper can be found on the original page.
The above is the detailed content of 13948 questions, covering 52 subjects such as calculus and line generation, were submitted to Tsinghua University to make a test set for the Chinese large model. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1205
24
52
1205
24

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
