
 Technology peripherals
AI
The picture is inconsistent with the code. An error was found in the Transformer paper. Netizen: It should have been pointed out 1,000 times.
Technology peripherals
AI
The picture is inconsistent with the code. An error was found in the Transformer paper. Netizen: It should have been pointed out 1,000 times.
The picture is inconsistent with the code. An error was found in the Transformer paper. Netizen: It should have been pointed out 1,000 times.

In 2017, the Google Brain team creatively proposed the Transformer architecture in its paper "Attention Is All You Need". Since then, this research has been a success and has become one of the most popular models in the NLP field today. One, it is widely used in various language tasks and has achieved many SOTA results.
Not only that, Transformer, which has been leading the way in the field of NLP, has quickly swept across fields such as computer vision (CV) and speech recognition, and has achieved good results in tasks such as image classification, target detection, and speech recognition. Effect.

Paper address: https://arxiv.org/pdf/1706.03762 .pdf
#Since its launch, Transformer has become the core module of many models. For example, the familiar BERT, T5, etc. all have Transformer. Even ChatGPT, which has become popular recently, relies on Transformer, which has already been patented by Google.

## Source: https://patentimages.storage.googleapis.com /05/e8/f1/cd8eed389b7687/US10452978.pdf
In addition, the series of models GPT (Generative Pre-trained Transformer) released by OpenAI has Transformer in the name, visible Transformer It is the core of the GPT series of models.
At the same time, OpenAI co-founder Ilya Stutskever recently said when talking about Transformer that when Transformer was first released, it was actually the second day after the paper was released. I couldn’t wait to switch my previous research to Transformer, and then GPT was introduced. It can be seen that the importance of Transformer is self-evident.
Over the past 6 years, models based on Transformer have continued to grow and develop. Now, however, someone has discovered an error in the original Transformer paper.
Transformer architecture diagram and code are "inconsistent"The person who discovered the error was Sebastian, a well-known machine learning and AI researcher and the chief AI educator of the startup Lightning AI. Raschka. He pointed out that the architecture diagram in the original Transformer paper was incorrect, placing layer normalization (LN) between residual blocks, which was inconsistent with the code.
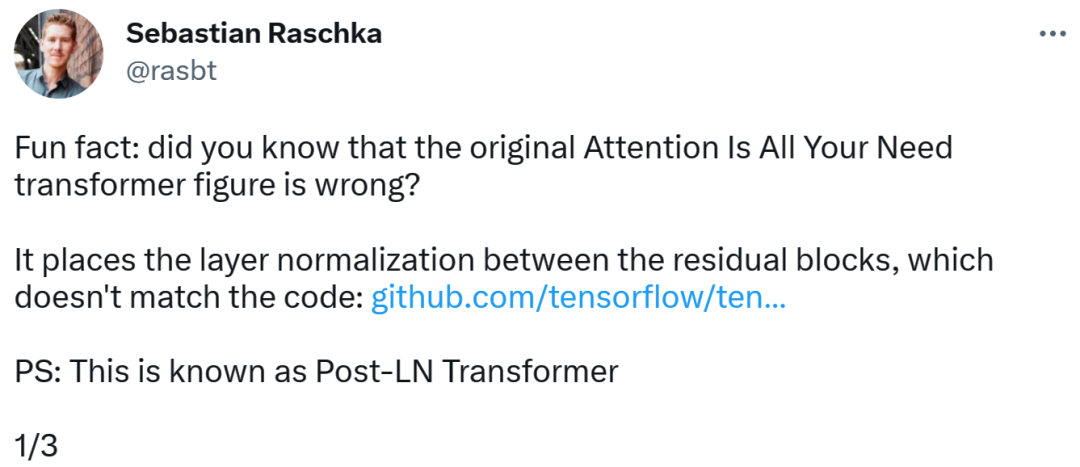
Transformer architecture diagram is as follows on the left, and on the right is the Post-LN Transformer layer (from the paper "On Layer Normalization in the Transformer Architecture" [1]).
The inconsistent code part is as follows. Line 82 writes the execution sequence "layer_postprocess_sequence="dan"", which means that the post-processing executes dropout, residual_add and layer_norm in sequence. If add&norm in the left middle of the above picture is understood as: add is above norm, that is, norm first and then add, then the code is indeed inconsistent with the picture.
Code address:
https://github.com/tensorflow/tensor2tensor/commit/ f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e…
Next, Sebastian He also stated that the paper "On Layer Normalization in the Transformer Architecture" believes that Pre-LN performs better and can solve the gradient problem. . This is what many or most architectures do in practice, but it can lead to representation corruption.
Better gradients can be achieved when layer normalization is placed in the residual connection before the attention and fully connected layers.
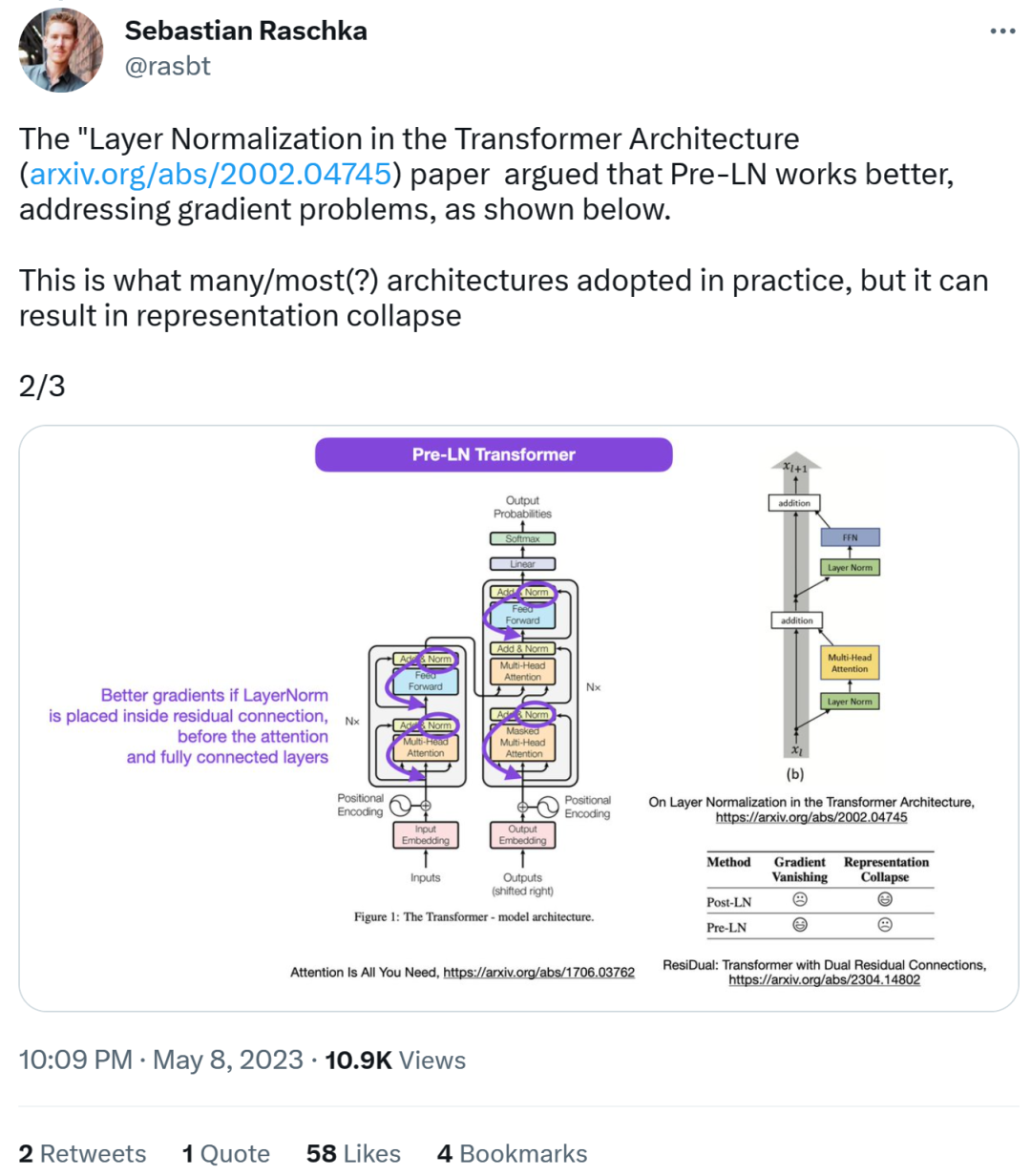
So while the debate about Post-LN or Pre-LN continues, another paper combines These two points are addressed in "ResiDual: Transformer with Dual Residual Connections"[2].
Regarding Sebastian’s discovery, some people think that we often encounter papers that are inconsistent with the code or results. Most of it is honest, but sometimes it's strange. Considering the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times over.
Sebastian replied that, to be fair, the "most original" code was indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified and the architecture diagram was not updated. So, this is really confusing.
As one netizen said, "The worst thing about reading code is that you will You often find small changes like this, and you don’t know if they were intentional or not. You can’t even test it because you don’t have enough computing power to train the model.”
I wonder what Google will do in the future Whether to update the code or the architecture diagram, we will wait and see!
The above is the detailed content of The picture is inconsistent with the code. An error was found in the Transformer paper. Netizen: It should have been pointed out 1,000 times.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 MySQL can't be installed after downloading
Apr 08, 2025 am 11:24 AM
MySQL can't be installed after downloading
Apr 08, 2025 am 11:24 AM
The main reasons for MySQL installation failure are: 1. Permission issues, you need to run as an administrator or use the sudo command; 2. Dependencies are missing, and you need to install relevant development packages; 3. Port conflicts, you need to close the program that occupies port 3306 or modify the configuration file; 4. The installation package is corrupt, you need to download and verify the integrity; 5. The environment variable is incorrectly configured, and the environment variables must be correctly configured according to the operating system. Solve these problems and carefully check each step to successfully install MySQL.
 Solutions to the service that cannot be started after MySQL installation
Apr 08, 2025 am 11:18 AM
Solutions to the service that cannot be started after MySQL installation
Apr 08, 2025 am 11:18 AM
MySQL refused to start? Don’t panic, let’s check it out! Many friends found that the service could not be started after installing MySQL, and they were so anxious! Don’t worry, this article will take you to deal with it calmly and find out the mastermind behind it! After reading it, you can not only solve this problem, but also improve your understanding of MySQL services and your ideas for troubleshooting problems, and become a more powerful database administrator! The MySQL service failed to start, and there are many reasons, ranging from simple configuration errors to complex system problems. Let’s start with the most common aspects. Basic knowledge: A brief description of the service startup process MySQL service startup. Simply put, the operating system loads MySQL-related files and then starts the MySQL daemon. This involves configuration
