
 Technology peripherals
AI
CVPR 2023 paper summary! The hottest field of CV is awarded to multi-modal and diffusion models
Technology peripherals
AI
CVPR 2023 paper summary! The hottest field of CV is awarded to multi-modal and diffusion models
CVPR 2023 paper summary! The hottest field of CV is awarded to multi-modal and diffusion models

The annual CVPR will officially open in Vancouver, Canada from June 18th to 22nd.
Every year, thousands of CV researchers and engineers from around the world gather for the Summit. This prestigious conference dates back to 1983 and represents the pinnacle of computer vision development.
Currently, CVPR’s h5 index ranks fourth among all conferences or publications, second only to Nature, Science and the New England Journal of Medicine.

Some time ago, CVPR announced the results of paper acceptance. According to statistics on the official website, a total of 9,155 papers were accepted, 2,359 were accepted, and the acceptance rate was 25.8%.
In addition, 12 award-winning candidate papers were announced.

So, what are the highlights of this year’s CVPR? What trends can we see in the CV field from the accepted papers?
will be announced next.
CVPR at a glance
The startup Voxel51 analyzed the list of all accepted papers.
Let’s first look at a summary diagram of the title of the paper. The size of each word is proportional to the frequency of occurrence in the data set.

##Brief description
- 2359 articles Papers accepted (9155 papers submitted)
- 1724 Arxiv papers
- 68 papers submitted to other addresses
Authors per paper
-The average author of a CVPR paper is about 5.4 people
- The paper with the most authors is: "Why is the winner the best?" There are 125 authors
- There are 13 papers with only one author.
Main Arxiv classification
Among the 1,724 Arxiv papers, there are 1,545, or close to 90% The paper lists cs.CV as the main category.
cs.LG ranked second with 101 articles. eess.IV (26) and cs.RO (16) also get a share of the pie.
Other categories for CVPR papers include: cs.HC, cs.CV, cs.AR, cs.DC, cs.NE, cs.SD, cs.CL, cs.IT , cs.CR, cs.AI, cs.MM, cs.GR, eess.SP, eess.AS, math.OC, math.NT, physics.data-an and stat.ML.
「Meta」data
- The two words "dataset" and "model" appear together in Among 567 abstracts. “Dataset” appears alone in 265 paper abstracts, while “model” appears alone 613 times. Only 16.2% of papers accepted by CVPR did not contain these two words.
- According to CVPR paper abstracts, the most popular datasets this year are ImageNet (105), COCO (94), KITTI (55) and CIFAR (36).
- 28 papers propose a new "benchmark".
Acronyms abound
It seems like there is no machine learning project without acronyms. Among the 2,359 papers, 1,487 have titles with multiple abbreviations or compound words in capital letters, accounting for 63%.
Some of these acronyms are easy to remember and even roll off the tongue:
##- CLAMP: Prompt-based Contrastive Learning for Connecting Language and Animal PoseCLAMP
- PATS: Patch Area Transportation with Subdivision for Local Feature Matching
- CIRCLE: Capture In Rich Contextual Environments
Some are much more complex:
- SIEDOB: Semantic Image Editing by Disentangling Object and Background
- FJMP : Factorized Joint Multi-Agent Motion Prediction over Learned Directed Acyclic Interaction GraphsFJMP
Some of them seem to have borrowed ideas from others on acronym construction:
- SCOTCH and SODA: A Transformer Video Shadow Detection Framework (Dutch popular brand Scotch & Soda)
- EXCALIBUR: Encouraging and Evaluating Embodied Exploration (Ex Curry sticks, lol)
What’s the hottest?In addition to the 2023 paper titles, we crawled all accepted paper titles in 2022. From these two lists, we calculated the relative frequency of various keywords to give you a deeper understanding of what is an uptrend and what is a downtrend.
Model
In 2023, diffusion models dominate.
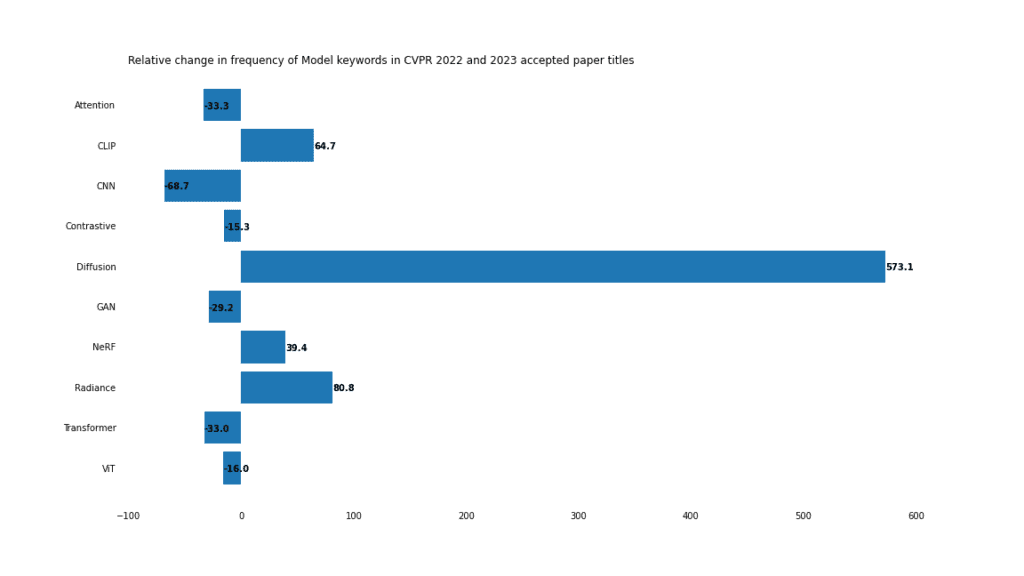
Diffusion Model
With Stable With the popularity of image generation models such as Diffusion and Midjourney, it is not surprising that the development of diffusion models is a hot trend.
Diffusion models also have applications in denoising, image editing, and style transfer. Add it all up, and it's by far the biggest winner across all categories, up 573% year-over-year.
Radiation Field
Neural Radiation Field (NERF) is also becoming more and more popular, and the word " "radiance" increased by 80%, and "NERF" increased by 39%. NeRF has moved from proof of concept to editing, application and training process optimization.
Transformers
The declining usage of "Transformer" and "ViT" does not mean that the Transformer model is outdated. Rather, it reflects the dominance of these models in 2022. In 2021, the word "Transformer" appeared in only 37 papers. In 2022, this number will soar to 201. Transformers aren't going away anytime soon.
CNN
CNN used to be the darling of computer vision. By 2023, it seems that they have lost their advantage. Usage dropped by 68%. Many headlines mentioning CNN also mention other models. For example, these papers mention CNN and Transformer:
- Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth EstimationLite-Mono
- Learned Image Compression with Mixed Transformer-CNN Architectures
Task
The combination of mask task and mask image modeling , occupying a dominant position in CVPR.
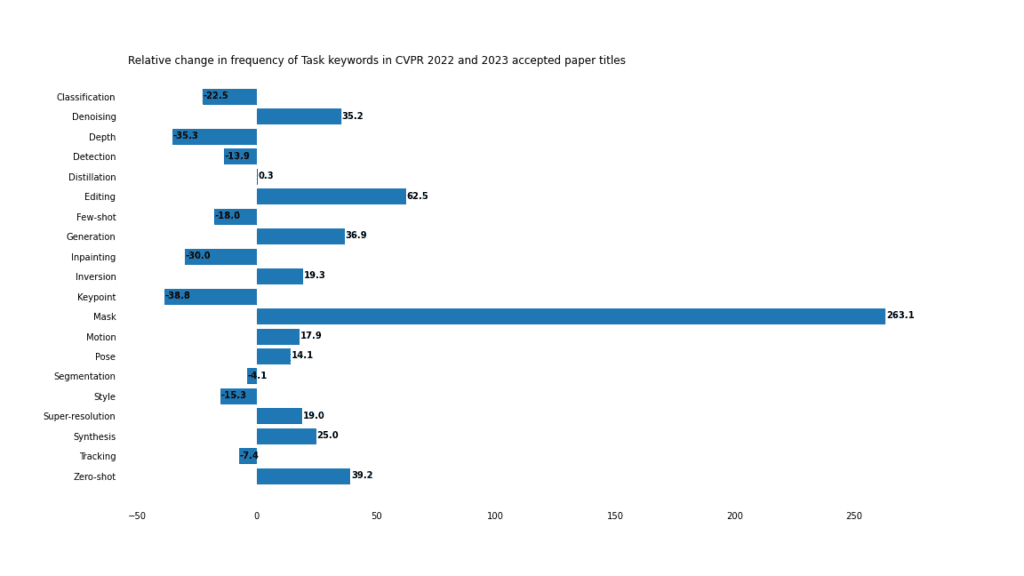
generate
Traditional discriminative tasks such as detection, classification and segmentation have not fallen out of favor, but their share in CV is shrinking due to a series of advances in generative applications, including "editing", "synthesis" and "generation" The rise proves this.
Mask
The keyword "mask" increased by 263% compared with the same period last year and was accepted in 2023 appears 92 times in papers and sometimes 2 times in a title.
- SIM: Semantic-aware Instance Mask Generation for Box-Supervised Instance SegmentationSIM
##- DynaMask: Dynamic Mask Selection for Instance SegmentationDynaMask
But the majority (64%) actually refer to the "mask" task, including 8 "mask image modeling" and 15 "mask autoencoder" tasks. In addition, "mask" appears in 8 articles.
It is also worth noting that the 3 paper titles with the word "mask" actually refer to the "no mask" task.
Zero sample vs small sample
With the rise of transfer learning, generative methods, hints and general models, "Zero-shot" learning is gaining traction. At the same time, “small sample” learning has declined from last year. However, in terms of raw numbers, at least for now, the "small sample" (45) has a slight advantage over the "zero sample" (35).
Modality
In 2023, the development of multi-modal and cross-modal applications will accelerate.
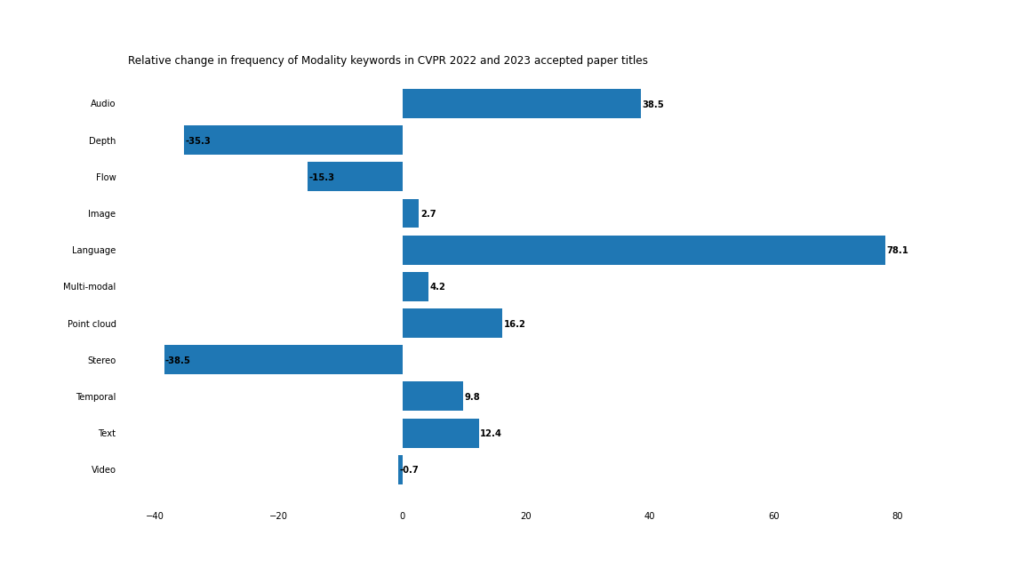
##Blurred boundaries
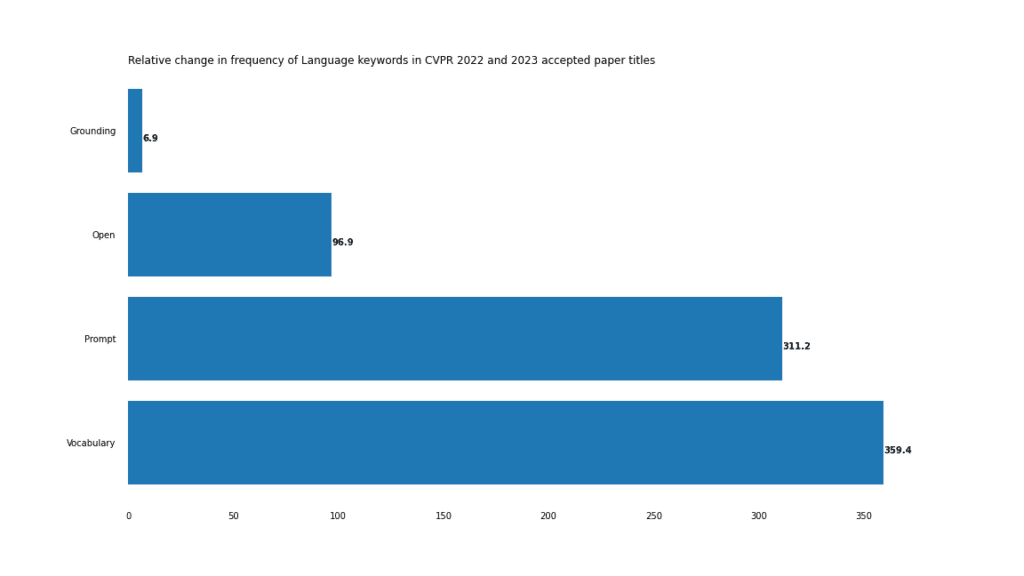
Although traditional computers The frequency of visual keywords such as "image" and "video" remains relatively unchanged, but "text"/"language" and "audio" appear more frequently.Even if the word "multimodal" itself does not appear in the title of the paper, it is difficult to deny that computer vision is heading towards a multimodal future.
This is especially evident in visual-verbal tasks, as shown by the sharp rise in Open, Prompt, and Vocabulary.
The most extreme example of this situation is the compound word "open vocabulary", which only appeared 3 times in 2022, but 18 times in 2023.
PointCloud9
Three-dimensional computer vision applications are moving from inferring 3D information ("depth" and "stereoscopic") from two-dimensional images to directly on 3D point cloud data The computer vision system that does the work.
Creativity in CV Titles
Any comprehensive machine learning-related coverage of 2023 would be incomplete without including ChatGPT in the mix. We decided to keep things interesting and used ChatGPT to find the most creative headlines from CVPR 2023.
For each paper uploaded to Arxiv, we scraped the abstract and asked ChatGPT (GPT-3.5 API) to generate a title for the corresponding CVPR paper.
Then, we combine these titles generated by ChatGPT and the actual paper titles, use OpenAI’s text-embedding-ada-002 model to generate embedding vectors, and calculate the sum of the titles generated by ChatGPT Cosine similarity between author-generated titles.
What can this tell us? The closer ChatGPT is to the actual paper title, the more predictable the title will be. In other words, the more "biased" ChatGPT's predictions are, the more "creative" the author is in naming the paper.
Embedding and cosine similarity provide us with an interesting, although far from perfect, method of quantification.
We sorted the papers according to this metric. Without further ado, here are the most creative headlines:
Actual headline: Tracking Every Thing in the Wild
Predicted headline : Disentangling Classification from Tracking: Introducing TETA for Comprehensive Benchmarking of Multi-Category Multiple Object Tracking
Actual title: Learning to Bootstrap for Combating Label Noise
Predicted title: Learnable Loss Objective for Joint Instance and Label Reweighting in Deep Neural Networks
Actual title: Seeing a Rose in Five Thousand Ways
Predicted title: Learning Object Intrinsics from Single Internet Images for Superior Visual Rendering and Synthesis
Actual title: Why is the winner the best?
Predicted title: Analyzing Winning Strategies in International Benchmarking Competitions for Image Analysis: Insights from a Multi-Center Study of IEEE ISBI and MICCAI 2021
The above is the detailed content of CVPR 2023 paper summary! The hottest field of CV is awarded to multi-modal and diffusion models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1379
1379
 52
52

 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV'23 paper award 'Fighting of Gods'! Meta Divide Everything and ControlNet were jointly selected, and there was another article that surprised the judges
Oct 04, 2023 pm 08:37 PM
ICCV2023, the top computer vision conference held in Paris, France, has just ended! This year's best paper award is simply a "fight between gods". For example, the two papers that won the Best Paper Award included ControlNet, a work that subverted the field of Vincentian graph AI. Since being open sourced, ControlNet has received 24k stars on GitHub. Whether it is for diffusion models or the entire field of computer vision, this paper's award is well-deserved. The honorable mention for the best paper award was awarded to another equally famous paper, Meta's "Separate Everything" ”Model SAM. Since its launch, "Segment Everything" has become the "benchmark" for various image segmentation AI models, including those that came from behind.
 NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Nov 14, 2023 pm 03:09 PM
Since Neural Radiance Fields was proposed in 2020, the number of related papers has increased exponentially. It has not only become an important branch of three-dimensional reconstruction, but has also gradually become active at the research frontier as an important tool for autonomous driving. NeRF has suddenly emerged in the past two years, mainly because it skips the feature point extraction and matching, epipolar geometry and triangulation, PnP plus Bundle Adjustment and other steps of the traditional CV reconstruction pipeline, and even skips mesh reconstruction, mapping and light tracing, directly from 2D The input image is used to learn a radiation field, and then a rendered image that approximates a real photo is output from the radiation field. In other words, let an implicit three-dimensional model based on a neural network fit the specified perspective
 Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Chat screenshots reveal the hidden rules of AI review! AAAI 3000 yuan is strong accept?
Apr 12, 2023 am 08:34 AM
Just as the AAAI 2023 paper submission deadline was approaching, a screenshot of an anonymous chat in the AI submission group suddenly appeared on Zhihu. One of them claimed that he could provide "3,000 yuan a strong accept" service. As soon as the news came out, it immediately aroused public outrage among netizens. However, don’t rush yet. Zhihu boss "Fine Tuning" said that this is most likely just a "verbal pleasure". According to "Fine Tuning", greetings and gang crimes are unavoidable problems in any field. With the rise of openreview, the various shortcomings of cmt have become more and more clear. The space left for small circles to operate will become smaller in the future, but there will always be room. Because this is a personal problem, not a problem with the submission system and mechanism. Introducing open r
 Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Paper illustrations can also be automatically generated, using the diffusion model, and are also accepted by ICLR.
Jun 27, 2023 pm 05:46 PM
Generative AI has taken the artificial intelligence community by storm. Both individuals and enterprises have begun to be keen on creating related modal conversion applications, such as Vincent pictures, Vincent videos, Vincent music, etc. Recently, several researchers from scientific research institutions such as ServiceNow Research and LIVIA have tried to generate charts in papers based on text descriptions. To this end, they proposed a new method of FigGen, and the related paper was also included in ICLR2023 as TinyPaper. Picture paper address: https://arxiv.org/pdf/2306.00800.pdf Some people may ask, what is so difficult about generating the charts in the paper? How does this help scientific research?
 The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
The Chinese team won the best paper and best system paper awards, and the CoRL research results were announced.
Nov 10, 2023 pm 02:21 PM
Since it was first held in 2017, CoRL has become one of the world's top academic conferences in the intersection of robotics and machine learning. CoRL is a single-theme conference for robot learning research, covering multiple topics such as robotics, machine learning and control, including theory and application. The 2023 CoRL Conference will be held in Atlanta, USA, from November 6th to 9th. According to official data, 199 papers from 25 countries were selected for CoRL this year. Popular topics include operations, reinforcement learning, and more. Although CoRL is smaller in scale than large AI academic conferences such as AAAI and CVPR, as the popularity of concepts such as large models, embodied intelligence, and humanoid robots increases this year, relevant research worthy of attention will also
 CVPR 2023 rankings released, the acceptance rate is 25.78%! 2,360 papers were accepted, and the number of submissions surged to 9,155
Apr 13, 2023 am 09:37 AM
CVPR 2023 rankings released, the acceptance rate is 25.78%! 2,360 papers were accepted, and the number of submissions surged to 9,155
Apr 13, 2023 am 09:37 AM
Just now, CVPR 2023 issued an article saying: This year, we received a record 9155 papers (12% more than CVPR2022), and accepted 2360 papers, with an acceptance rate of 25.78%. According to statistics, the number of submissions to CVPR only increased from 1,724 to 2,145 in the 7 years from 2010 to 2016. After 2017, it soared rapidly and entered a period of rapid growth. In 2019, it exceeded 5,000 for the first time, and by 2022, the number of submissions had reached 8,161. As you can see, a total of 9,155 papers were submitted this year, indeed setting a record. After the epidemic is relaxed, this year’s CVPR summit will be held in Canada. This year it will be a single-track conference and the traditional Oral selection will be cancelled. google research
 SEEM, a universal segmentation model created by a Chinese team, takes one-time segmentation to a new level
Apr 26, 2023 pm 10:07 PM
SEEM, a universal segmentation model created by a Chinese team, takes one-time segmentation to a new level
Apr 26, 2023 pm 10:07 PM
At the beginning of this month, Meta released the “segment everything” AI model-SegmentAnythingModel (SAM). SAM is considered a universal basic model for image segmentation. It learns general concepts about objects and can generate masks for any object in any image or video, including objects and image types that have not been encountered during the training process. This "zero sample migration" capability is amazing, and some even say that the CV field has ushered in a "GPT-3 moment." Recently, a new paper "SegmentEverythingEverywhereAllatOnce" on "SegmentEverythingEverywhereAllatOnce" has once again attracted attention. In the paper, researchers from the University of Wisconsin-Madison,
