

The development of large models can be said to be rapid, instruction fine-tuning methods have sprung up like mushrooms after a spring rain, and a large number of so-called ChatGPT "replacement" large models have been released one after another. In the training and application development of large models, the evaluation of the real capabilities of various large models such as open source, closed source, and self-research has become an important link in improving research and development efficiency and quality.
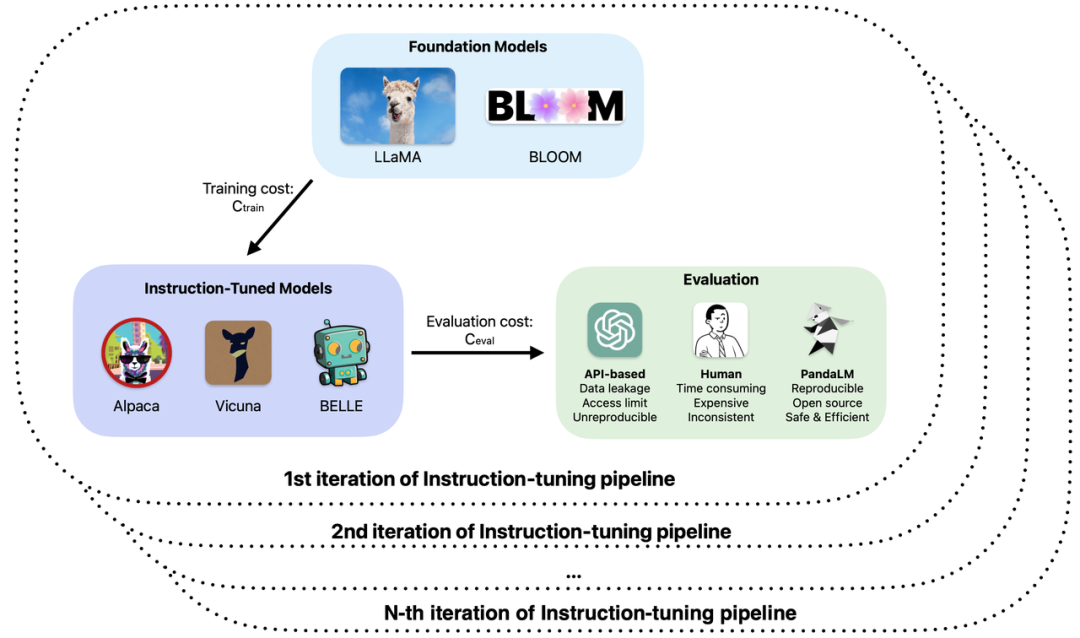
Specifically, in the training and application of large models, you may have encountered the following problems:
1. Different bases and parameters are used in fine-tuning or enhanced pre-training of large models. According to the observed sample effects, the performance of the model has its own advantages and disadvantages in different scenarios. How do you decide which model to use in a real application?
2. Use ChatGPT to evaluate the model output, but ChatGPT obtains different evaluation results for the same input at different times. Which evaluation result should be used?
3. Using manual annotation to evaluate the model generated results is time-consuming and labor-intensive. How to speed up the evaluation process and reduce costs when the budget is limited and time is tight?
4. When dealing with confidential data, whether using ChatGPT/GPT4 or labeling companies for model evaluation, you will face data leakage problems. How to ensure data security?
Based on these issues, researchers from Peking University, West Lake University and other institutions jointly proposed a new large model evaluation paradigm - PandaLM. PandaLM performs automated and reproducible testing and verification of large model capabilities by training a large model specifically for evaluation. PandaLM, released on GitHub on April 30, is the world’s first large model for evaluation. Relevant papers will be published in the near future.

##GitHub address: https://github.com/WeOpenML/PandaLM
PandaLM aims to enable large models to learn human overall preferences for texts generated by different large models through training, and make relative evaluations based on preferences to replace manual or API-based evaluation methods and reduce costs. Increase efficiency. PandaLM's weights are fully disclosed and can be run on consumer-grade hardware with low hardware thresholds. PandaLM's evaluation results are reliable, fully reproducible, and can protect data security. The evaluation process can be completed locally, making it very suitable for use in academia and units that require confidential data. Using PandaLM is very simple and requires only three lines of code to call. To verify the evaluation capabilities of PandaLM, the PandaLM team invited three professional annotators to independently judge the output of different large models, and built a diverse test set containing 1,000 samples in 50 fields. On this test set, PandaLM's accuracy reached the level of 94% of ChatGPT, and PandaLM produced the same conclusions about the advantages and disadvantages of the model as manual annotation.
Introduction to PandaLMCurrently, there are two main ways to evaluate large models:
(1) By calling the API interface of third-party companies;
(2) Hire experts for manual annotation.
However, transferring data to third-party companies can lead to data breaches similar to the one where Samsung employees leaked code [1]; and hiring experts to label large amounts of data is time-consuming and expensive. An urgent problem to be solved is: how to achieve privacy-preserving, reliable, reproducible and cheap large model evaluation?
In order to overcome the limitations of these two evaluation methods, this study developed PandaLM, a referee model specifically used to evaluate the performance of large models, and provides a simple interface that allows users to PandaLM can be called with just one line of code to achieve privacy-preserving, reliable, repeatable, and economical large-scale model evaluation. For training details on PandaLM, see the open source project.
To validate PandaLM’s ability to evaluate large models, the research team built a diverse human-annotated test set of approximately 1,000 samples, with context and labels generated by humans. On the test data set, PandaLM-7B achieved an accuracy of 94% of ChatGPT (gpt-3.5-turbo).
How to use PandaLM?
When two different large models produce different responses to the same instructions and context, the goal of PandaLM is to compare the quality of the responses of the two models and output the comparison Results, basis for comparison, and responses for reference. There are three comparison results: response 1 is better; response 2 is better; response 1 and response 2 are of equal quality. When comparing the performance of multiple large models, simply use PandaLM to perform pairwise comparisons and then aggregate these comparisons to rank the performance of the models or plot the partial order of the models. This allows for visual analysis of performance differences between different models. Because PandaLM only needs to be deployed locally and requires no human involvement, it can be evaluated in a privacy-preserving and low-cost manner. To provide better interpretability, PandaLM can also explain its selections in natural language and generate an additional set of reference responses.
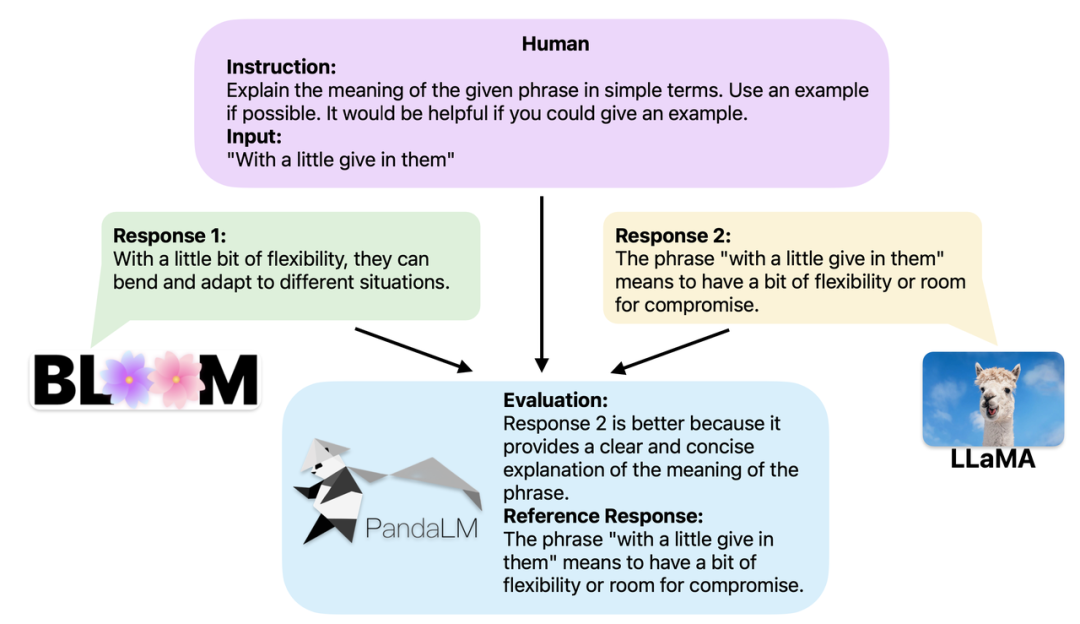
##PandaLM not only supports the use of Web UI for case analysis, but also supports three lines of code to call PandaLM for any model and Data-generated text evaluation. Considering that many existing models and frameworks may not be open source or difficult to infer locally, PandaLM allows generating text to be evaluated by specifying model weights, or directly passing in a .json file containing the text to be evaluated. Users can leverage PandaLM to evaluate user-defined models and input data simply by providing a list of model names, HuggingFace model IDs, or .json file paths. The following is a minimalist usage example:

In addition, in order to allow everyone to use PandaLM flexibly for free evaluation, The research team has disclosed the model weights of PandaLM on the HuggingFace website. You can easily load the PandaLM-7B model with the following command:

Features of PandaLM
The features of PandaLM include reproducibility, automation, privacy protection, low cost and high evaluation level.
1. Reproducibility: Since the weights of PandaLM are public, even if there is randomness in the language model output, the evaluation results of PandaLM will remain consistent after fixing the random seed. . Evaluation methods that rely on online APIs may have inconsistent updates at different times due to opaque updates, and as models are iterated, old models in the API may no longer be accessible, so evaluations based on online APIs are often not reproducible.
2. Automation, privacy protection and low cost: Users only need to deploy the PandaLM model locally and call ready-made commands to evaluate various large models, without the need to maintain real-time like hiring experts Communicate and worry about data breaches. At the same time, the entire evaluation process of PandaLM does not involve any API fees or labor costs, which is very cheap.
3. Evaluation level: To verify the reliability of PandaLM, this study hired three experts to independently complete repeated annotations and created a manual annotation test set. The test set contains 50 different scenarios, each with multiple tasks. This test set is diverse, reliable, and consistent with human preferences for text. Each sample in the test set consists of instructions and context, and two responses generated by different large models, and the quality of the two responses is compared by humans.
This study eliminates samples with large differences between annotators to ensure that each annotator's IAA (Inter Annotator Agreement) on the final test set is close to 0.85. It should be noted that there is no overlap at all between the PandaLM training set and the manually annotated test set created in this study.
These filtered samples require additional knowledge or difficult-to-obtain information to assist judgment, which makes it difficult for humans to Label them accurately. The filtered test set contains 1000 samples, while the original unfiltered test set contains 2500 samples. The distribution of the test set is {0:105, 1:422, 2:472}, where 0 indicates that the two responses are of similar quality; 1 indicates that response 1 is better; 2 indicates that response 2 is better.
Based on the human test set, the performance comparison between PandaLM and gpt-3.5-turbo is as follows:
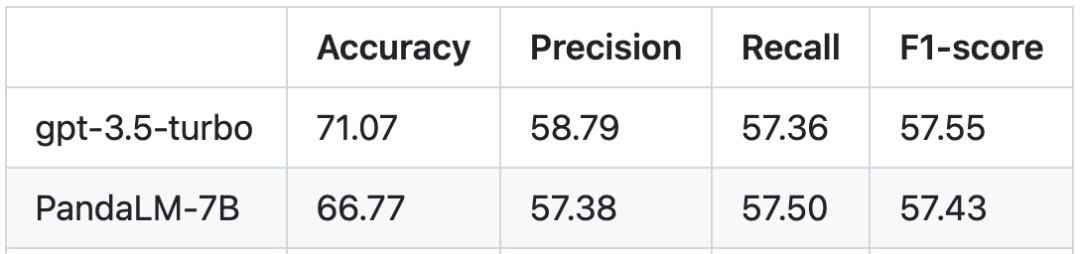
It can be seen that PandaLM-7B has reached the level of gpt-3.5-turbo 94% in accuracy, and in terms of precision rate, recall rate, and F1 score, PandaLM-7B has surpassed gpt -3.5-turbo Not too far behind. It can be said that PandaLM-7B already has large model evaluation capabilities equivalent to gpt-3.5-turbo.
In addition to the accuracy, precision, recall, and F1 score on the test set, this study also provides comparisons between 5 large open-source models of similar size. result. The study first used the same training data to fine-tune the five models, and then used humans, gpt-3.5-turbo, and PandaLM to conduct pairwise comparisons of the five models. The first tuple (72, 28, 11) in the first row of the table below indicates that there are 72 LLaMA-7B responses that are better than Bloom-7B, and 28 LLaMA-7B responses that are worse than Bloom-7B. Two The models had 11 responses with similar quality. So in this example, humans think LLaMA-7B is better than Bloom-7B. The results in the following three tables show that humans, gpt-3.5-turbo and PandaLM-7B are completely consistent in their judgments about the superiority and inferiority of each model.
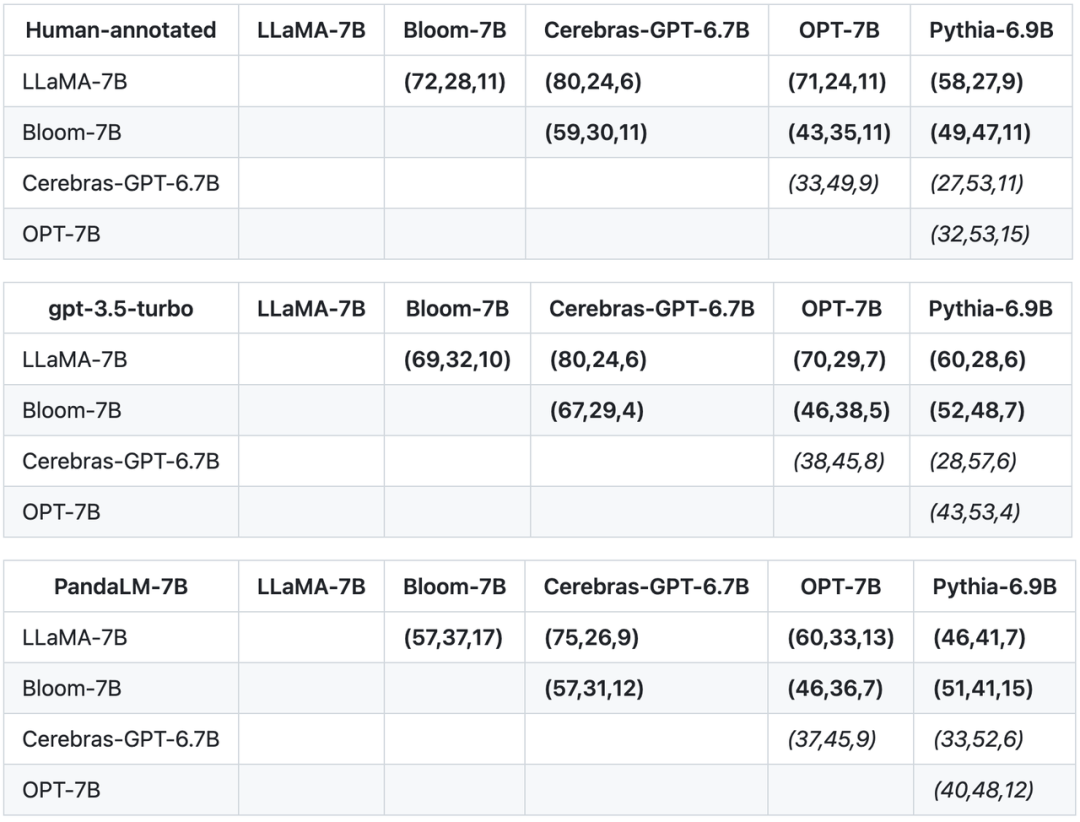
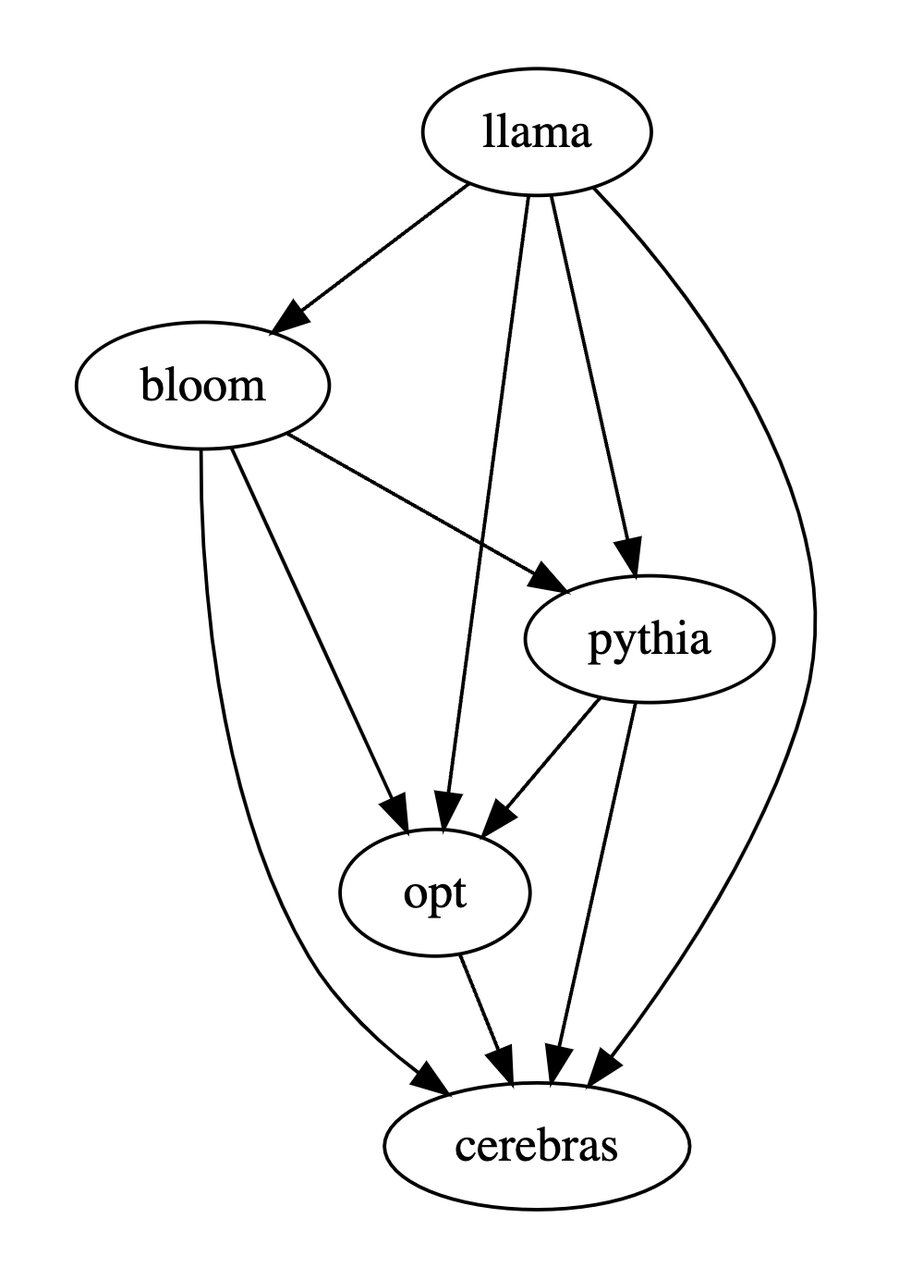
Based on the above three tables, this study generated a partial order diagram of the pros and cons of the model. This partial order diagram constitutes The total order relationship is obtained, which can be expressed as: LLaMA-7B > Bloom-7B > Pythia-6.9B > OPT-7B > Cerebras-GPT-6.7B.
In summary, PandaLM provides in addition to manual evaluation and third-party API A third option for evaluating large models. PandaLM's evaluation level is not only high, but its results are reproducible, the evaluation process is highly automated, privacy is protected and the cost is low. The research team believes that PandaLM will promote research on large-scale models in academia and industry, and enable more people to benefit from advances in this research field. Everyone is welcome to pay attention to the PandaLM project. More training, testing details, related articles and follow-up work will be announced at the project website: https://github.com/WeOpenML/PandaLM
Introduction to the author team
Among the author team, Wang Yidong* comes from the National Engineering Center for Software Engineering of Peking University (Ph.D.) and West Lake University (research assistant), Yu Zhuohao*, Zeng Zhengran , Jiang Chaoya, Xie Rui, Ye Wei† and Zhang Shikun† are from the National Engineering Center for Software Engineering at Peking University, Yang Linyi, Wang Cunxiang and Zhang Yue† are from West Lake University, Heng Qiang is from North Carolina State University, and Chen Hao is from Carnegie Mellon University , Jindong Wang and Xie Xing are from Microsoft Research Asia. * indicates co-first author, † indicates co-corresponding author.
The above is the detailed content of Reproducible, automated, low-cost, and high-level of evaluation, PandaLM, the first large model to automatically evaluate large models, is here. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



